Motivations
ZSL问题为了能够泛化到unseen class,通常做了类别辅助信息可用性的假设(辅助信息可以帮助从seen class迁移知识到unseen class)。辅助信息可以是类别属性、词向量等或者是unseen class和每个seen class的相似度。
现有的大多数ZSL方法假设每个类别可以用语义空间中的一个固定点表示,而一个点不足以解释类内方差。而生成模型有很多优势:可以通过特征学习来揭示数据的复杂结构;生成数据的能力可以将ZSL问题扩展为transductive/semi-supervised形式;在seen class的数据很少,而seen/unseen classes的无标记数据很多的情况下,或许也很有用( few-shot learning )。
受此启发,设计了一种深度生成模型来解决ZSL问题。模型学习attribute-specific的潜在空间分布( pψ(z|a),服从高斯分布),作为VAE模型的先验分布,有助于VAE学习判别性更强的特征表示(相当于构造更好的生成器??)。此外,
模型的生成能力使其能够扩展为transductive/semi-supervised形式(通过无监督学习)。模型参数是由seen class的标记数据端到端地学习得到的。(在semi-supervised/transductive也可以用无标记数据)
测试时,对于给定的输入x∗,首先通过VAE的识别模型 qφ (z∗ | x∗) 将x∗映射到隐变量空间z,然后寻找能够使得VAE的下界(对数似然函数变分下界)最大化的a∗ ,根据a∗可以得到对应的标签y∗ 。这相当于寻找pψ(z|a)来使得与qφ (z∗ | x∗)的KL散度最小。
Method
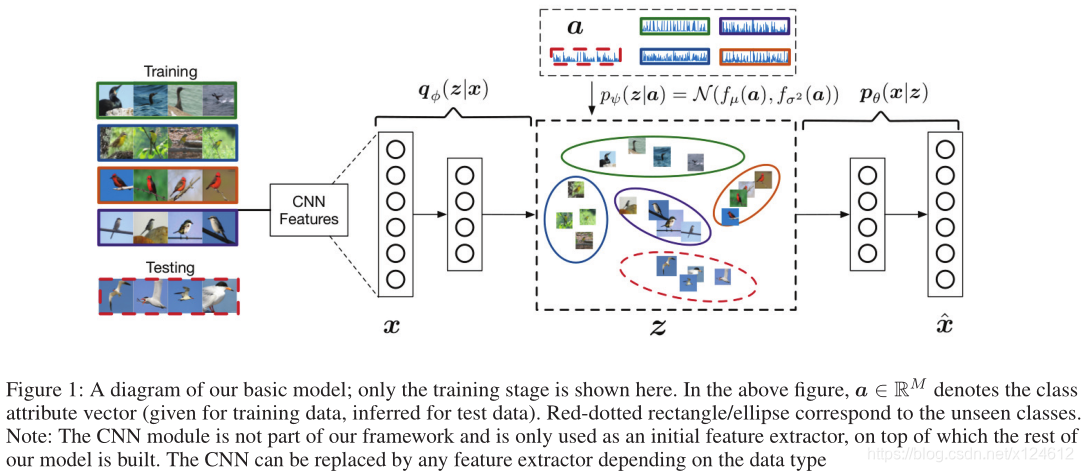
Note :我们的框架利用attribute-specific的潜在空间分布 pψ(z|a) 来作为隐变量z(关于某个x)的先验分布。(Class-Conditioned的含义)
Variational Autoencoder
VAE可以通过隐变量学习数据的复杂模型。VAE的目标是利用识别模型qφ (z | x)来近似隐变量的后验分布pθ (z | x),通过最大化变分下界来实现: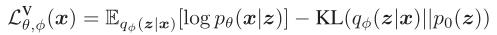
假定qφ (z | x)是服从高斯分布的。
Inductive ZSL
不同于标准VAE的隐变量z的先验分布是服从标准正态分布,我们假设每个zn是从attribute-specific的高斯分布 pψ(z|a) 中得到的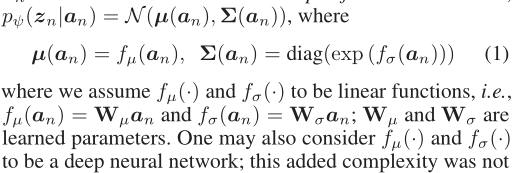
所以,变分下界变为: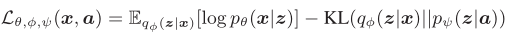
Trick: Margin Regularizer
上述目标函数让 qφ (z | x) 与 pψ(z|a) 尽可能接近,但是我们的目标是分类,所以引入最大化间隔准则来促使qφ (z | x)与其他类别的 pψ(z|Ac) 越远越好。所以,将−KL( qφ(z|x) || pψ(z|a) ) 用 −[KL( qφ(z|x) || pψ(z|a) ) − R∗ ] 代替。其中R∗表示qφ (z | x)与其他类别的 pψ(z|Ac) 的最小KL散度。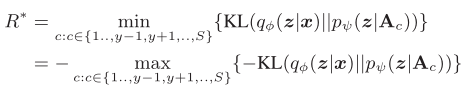
正则化项−[KL( qφ(z|x) || pψ(z|a) ) − R∗ ] 使得真实类别与最易混淆的那个类别( the next best class)能尽可能分离开。但是R∗是不可微分的,导致优化困难,所以用以下近似: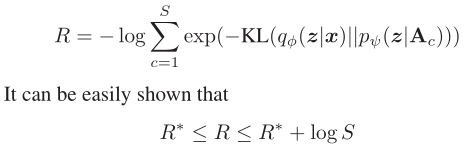
因此,最大化R,等价于最大化R∗的上界,最终目标函数为: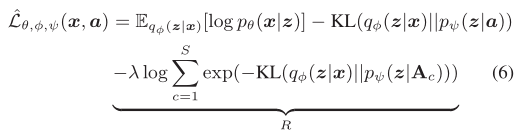
测试时,对于给定的输入x∗,首先通过VAE的识别模型 qφ (z∗ | x∗) 将x∗映射到隐变量空间z,然后寻找能够使得VAE的下界(对数似然函数变分下界)最大化的a∗ ,根据a∗可以得到对应的标签y∗ 。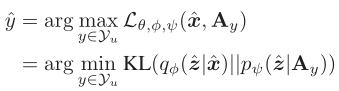
相比于传统的ZSL方法通过计算测试样本x的embedding向量与所有类别class prototypes(也是一个点)的欧式距离,我们的方法考虑了类别分布,因此预测效果更好(特别是在类内方差较大的情况下)
Transductive ZSL
在Transductive ZSL场景下,有unseen class的无标记数据,所以提出无监督方法利用这些数据来refine the inductive ZSL。
可以用重构误差来利用无标记数据: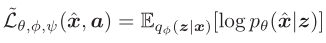
但是,该方法完全忽视了类别信息,效果不理想。由于 inductive ZSL模型能够为unseen class提供有一定置信度的预测结果(通过计算测试类别分布),而这些分布可以指导测试样例。
对于unseen class的测试样例,应用inductive ZSL模型:
为了使得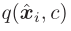 更加sharper(对于unseen class的测试样例,最有可能的类应该占
更加sharper(对于unseen class的测试样例,最有可能的类应该占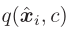 的主导地位)
的主导地位)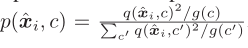
其中,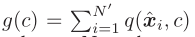
Note:sharper是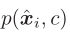 中的平方项实现的,用
中的平方项实现的,用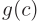 来对概率标准化,能够防止大的类别扭曲隐空间。
来对概率标准化,能够防止大的类别扭曲隐空间。
然后,用KL散度来使得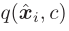 与
与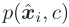 尽可能接近:
尽可能接近: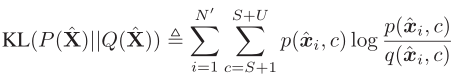
结合之前的重构误差,可以得到unseen class无标记数据的目标函数: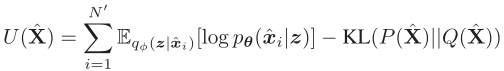
再与inductive ZSL模型相结合,得到Transductive ZSL的目标函数: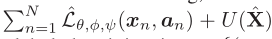
前者用seen class的标记数据训练,后者用unseen class的无标记数据训练。
我们的框架还能够直接应用到few-shot learning(unseen class有少数样本)中,直接在unseen class上优化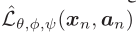 即可。
即可。