做这个题目之前我并不知道robots协议是什么,我就上网查询了相关资料
这是一位博主的robots详解,看了这个我才刚刚懂点robots协议
简单来说当robots访问一个网站(比如http://www.abc.com)时,首先会检查该网站中是否存在http://www.abc.com/robots.txt这个文件,如果机器人找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。(也就相当于一个管理权限的文件)
robots.txt文件用法举例:
User-agent(搜索引擎robots的名字):*(*代表所有)
Disallow(以Disallow开头的url都禁止访问):/(代表禁止所有引擎访问网站任何部分)
例:
User-agent:baiduspider
Disallow:
User-agent:*
Disallow:/
代表允许baiduspider来访问网站任何,其他都不行
打开环境,习惯性按F12

什么都没有空白一片,联想到题目提示robots协议,会不会flag的网页在robots.txt中被禁止访问了,因此直接在根目录下输入/robots.txt查看

发现robots.txt里禁止了所有搜索引擎robot访问f1ag_1s_h3re.php,看这链接名就知道flag在这个链接下了,进入该url下
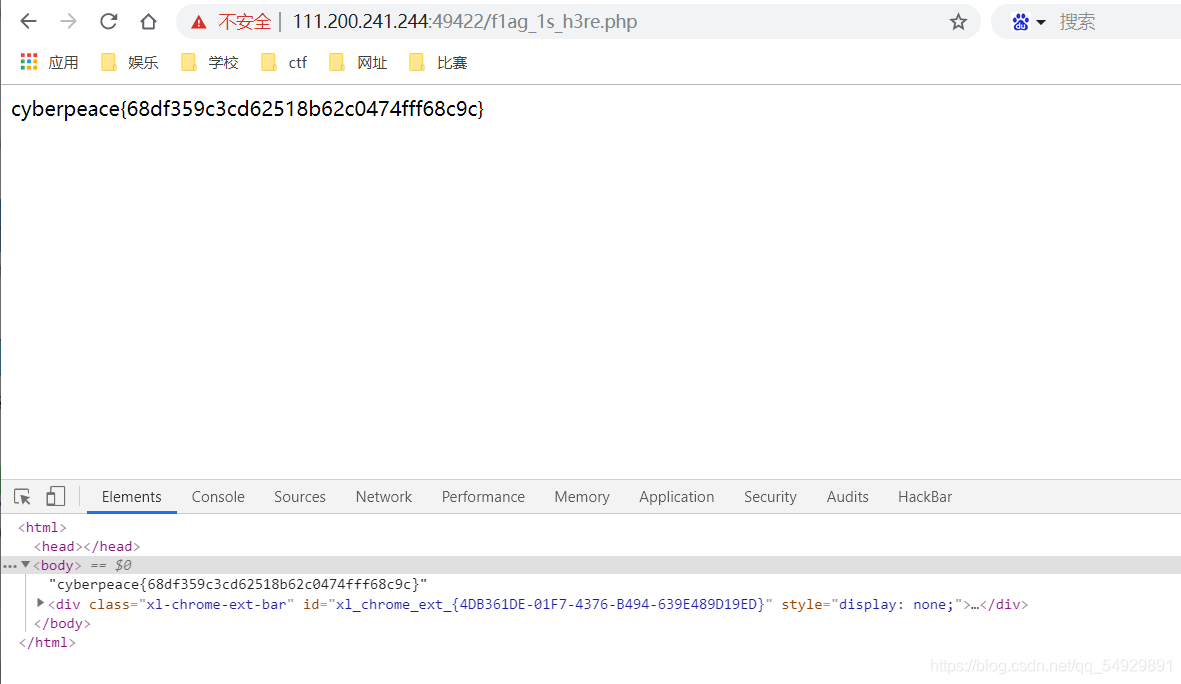
即可发现flag就在里面
版权声明:本文为qq_54929891原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。