关系网络

关系网络由两个重要的函数组成:嵌入函数和关系函数。嵌入函数用于从输入中提取特征。如果输入是图像,那么可以使用卷积网络作为嵌入函数,它会提供图像的特征向量,如果输入是文本,那么可以使用LSTM网络获得文本的嵌入。
零样本学习中的关系网络
零样本学习场景中,每个类下都没有数据点,但会有元信息。元信息是关于每个类的属性的信息,元信息会被编码到语义向量Vc中,下标c表示类别。没有使用单一的嵌入函数来学习支撑集和查询集的嵌入,而是分别使用了两个不同的嵌入函数,使用第一个函数学习语义向量的嵌入,使用第二个函数学习查询集的嵌入,并使用拼接运算符拼接这些嵌入。
使用均方误差(MSE)作为损失函数。
使用TensorFlow构建关系网络
import tensorflow as tf
import numpy as np
# 随机为每个类生成1000个数据点
classA = np.random.rand(1000,18)
ClassB = np.random.rand(1000,18)
# 组合这些类创建数据集
data = np.vstack([classA, ClassB])
# 设置标签
label = np.vstack([np.ones((len(classA),1)),np.zeros((len(ClassB),1))])
# 为支撑集和查询集定义占位符
xi = tf.placeholder(tf.float32, [None, 9])
xj = tf.placeholder(tf.float32, [None, 9])
# 为标签y定义占位符
y = tf.placeholder(tf.float32, [None, 1])
def embedding_function(x):
#使用一个前馈网络作为嵌入函数
weights = tf.Variable(tf.truncated_normal([9,1]))
bias = tf.Variable(tf.truncated_normal([1]))
a = (tf.nn.xw_plus_b(x,weights,bias))
embeddings = tf.nn.relu(a)
return embeddings
f_xi = embedding_function(xi)
f_xj = embedding_function(xj)
#结合特征向量
Z = tf.concat([f_xi,f_xj],axis=1)
def relation_function(x):
# 将关系函数定义为具有Relu激活的三层神经网络
w1 = tf.Variable(tf.truncated_normal([2,3]))
b1 = tf.Variable(tf.truncated_normal([3]))
w2 = tf.Variable(tf.truncated_normal([3,5]))
b2 = tf.Variable(tf.truncated_normal([5]))
w3 = tf.Variable(tf.truncated_normal([5,1]))
b3 = tf.Variable(tf.truncated_normal([1]))
#layer1
z1 = (tf.nn.xw_plus_b(x,w1,b1))
a1 = tf.nn.relu(z1)
#layer2
z2 = tf.nn.xw_plus_b(a1,w2,b2)
a2 = tf.nn.relu(z2)
#layer3
z3 = tf.nn.xw_plus_b(z2,w3,b3)
#output
y = tf.nn.sigmoid(z3)
return y
#关系得分
relation_scores = relation_function(Z)
loss_function = tf.reduce_mean(tf.squared_difference(relation_scores,y))
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss_function)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# 随机抽取支撑集和查询集的数据点训练网络
for episode in range(1000):
_, loss_value = sess.run([train, loss_function],
feed_dict={xi:data[:,0:9]+np.random.randn(*np.shape(data[:,0:9]))*0.05,
xj:data[:,9:]+np.random.randn(*np.shape(data[:,9:]))*0.05,
y:label})
if episode % 100 == 0:
print("Episode {}: loss {:.3f} ".format(episode, loss_value))
匹配网络
它甚至可以为数据集中未观察到的类生成标签,总流程图如下图所示:
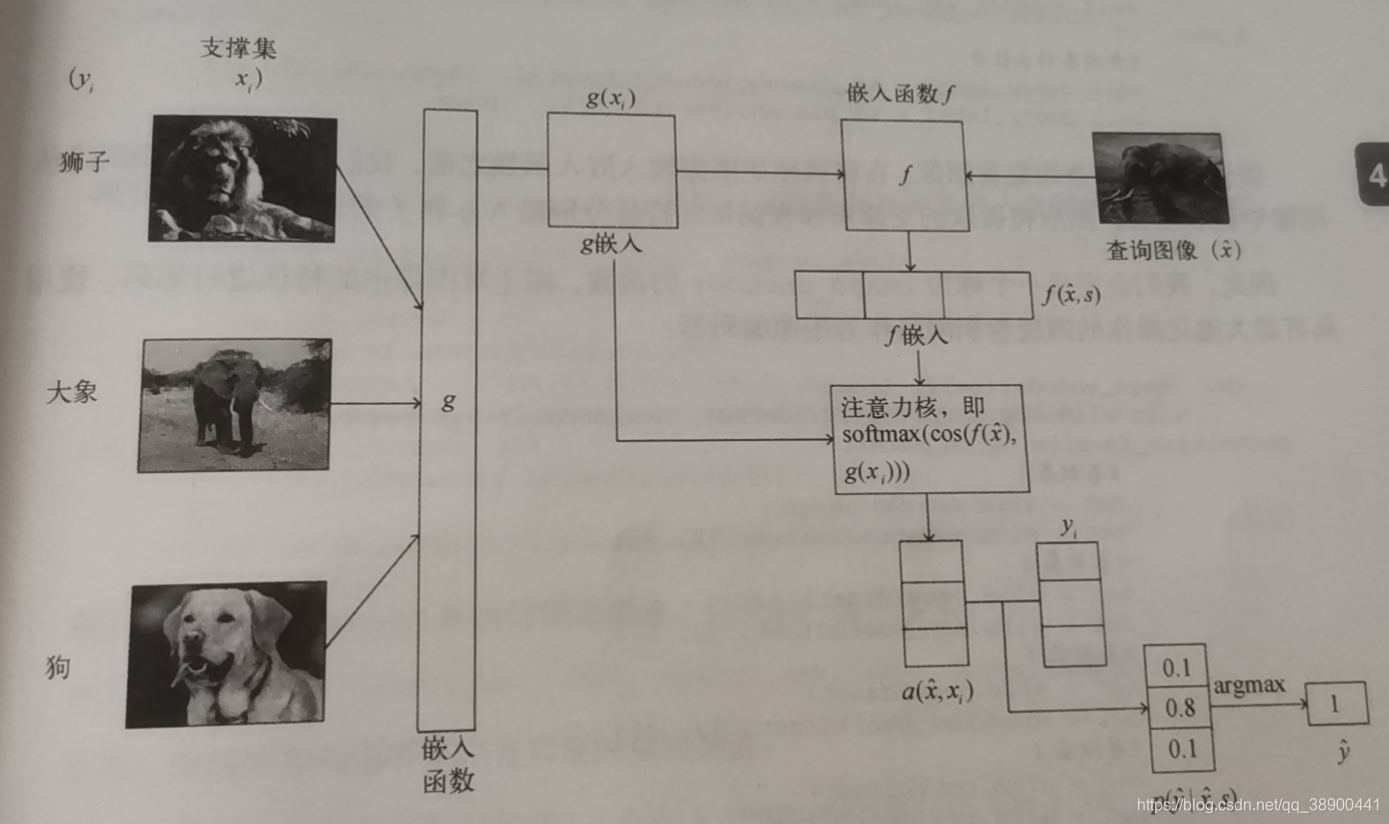
import tensorflow as tf
slim = tf.contrib.slim
rnn = tf.contrib.rnn
class Matching_network():
#initialize all the variables
def __init__(self, lr, n_way, k_shot, batch_size=32):
#初始化所有变量
self.support_set_image = tf.placeholder(tf.float32, [None, n_way * k_shot, 28, 28, 1])
self.support_set_label = tf.placeholder(tf.int32, [None, n_way * k_shot, ])
#placeholder for query set
self.query_image = tf.placeholder(tf.float32, [None, 28, 28, 1])
self.query_label = tf.placeholder(tf.int32, [None, ])
# 假设支撑集和查询集有图像,在将原始图像输入嵌入函数之前,首先使用卷积网络提取特征,
# 然后将提取的支撑集和查询集的特征分别输入g和f的嵌入函数
def image_encoder(self, image):
# 使用具有最大池化操作的四层卷积网络作为图像编码器
with slim.arg_scope([slim.conv2d], num_outputs=64, kernel_size=3, normalizer_fn=slim.batch_norm):
#conv1
net = slim.conv2d(image)
net = slim.max_pool2d(net, [2, 2])
#conv2
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv3
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv4
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
return tf.reshape(net, [-1, 1 * 1 * 64])
#提取支撑集嵌入的嵌入函数
def g(self, x_i):
forward_cell = rnn.BasicLSTMCell(32)
backward_cell = rnn.BasicLSTMCell(32)
outputs, state_forward, state_backward = rnn.static_bidirectional_rnn(forward_cell, backward_cell, x_i, dtype=tf.float32)
return tf.add(tf.stack(x_i), tf.stack(outputs))
#提取查询集嵌入的嵌入函数
def f(self, XHat, g_embedding):
cell = rnn.BasicLSTMCell(64)
prev_state = cell.zero_state(self.batch_size, tf.float32)
for step in xrange(self.processing_steps):
output, state = cell(XHat, prev_state)
h_k = tf.add(output, XHat)
content_based_attention = tf.nn.softmax(tf.multiply(prev_state[1], g_embedding))
r_k = tf.reduce_sum(tf.multiply(content_based_attention, g_embedding), axis=0)
prev_state = rnn.LSTMStateTuple(state[0], tf.add(h_k, r_k))
return output
# 学习支撑集和查询集嵌入之间的余弦相似度
def cosine_similarity(self, target, support_set):
target_normed = target
sup_similarity = []
for i in tf.unstack(support_set):
i_normed = tf.nn.l2_normalize(i, 1)
similarity = tf.matmul(tf.expand_dims(target_normed, 1), tf.expand_dims(i_normed, 2))
sup_similarity.append(similarity)
return tf.squeeze(tf.stack(sup_similarity, axis=1))
def train(self, support_set_image, support_set_label, query_image):
#使用图像编码器编码支撑集和查询集特征
query_image_encoded = self.image_encoder(query_image)
support_set_image_encoded = [self.image_encoder(i) for i in tf.unstack(support_set_image, axis=1)]
#使用嵌入函数g学习支撑集的嵌入,f学习查询集的嵌入
g_embedding = self.g(support_set_image_encoded)
f_embedding = self.f(query_image_encoded, g_embedding)
# 计算余弦相似度
embeddings_similarity = self.cosine_similarity(f_embedding, g_embedding)
#对余弦相似度执行softmax注意力
attention = tf.nn.softmax(embeddings_similarity)
# 通过将注意力矩阵与one-hot编码的支撑记标签相乘 来预测查询集标签
y_hat = tf.matmul(tf.expand_dims(attention, 1), tf.one_hot(support_set_label, self.n_way))
#get the probabilities
probabilities = tf.squeeze(y_hat)
# 选择概率最高的索引作为查询图像的类
predictions = tf.argmax(self.probabilities, 1)
loss_function = tf.losses.sparse_softmax_cross_entropy(label, self.probabilities)
tf.train.AdamOptimizer(self.lr).minimize(self.loss_op)
版权声明:本文为qq_38900441原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。