今天分享的是使用python语言然后通过cookie来爬取淘宝天猫评论的方法。
1、首先我们打开一个产品页,地址:几素usb小风扇,按下F12,然后下拉到产品评论可以看到如下图

2、点击这个script的文件,然后点preview进去看可以看到
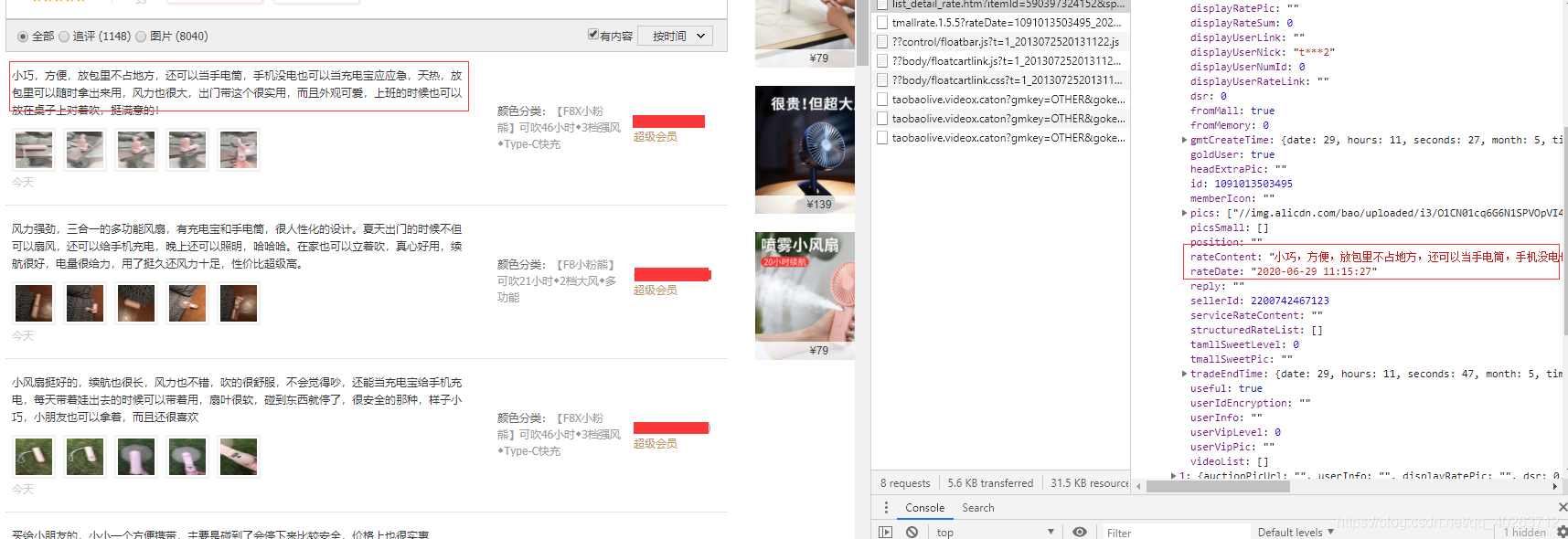
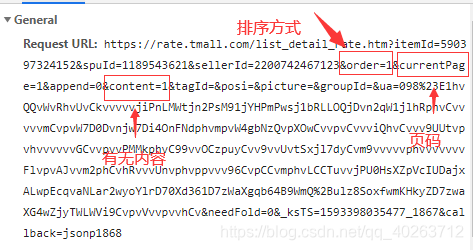
3、可以看到我们需要爬取的内容全在这个script文件中了,接下来我们来分析这个文件,首先是url
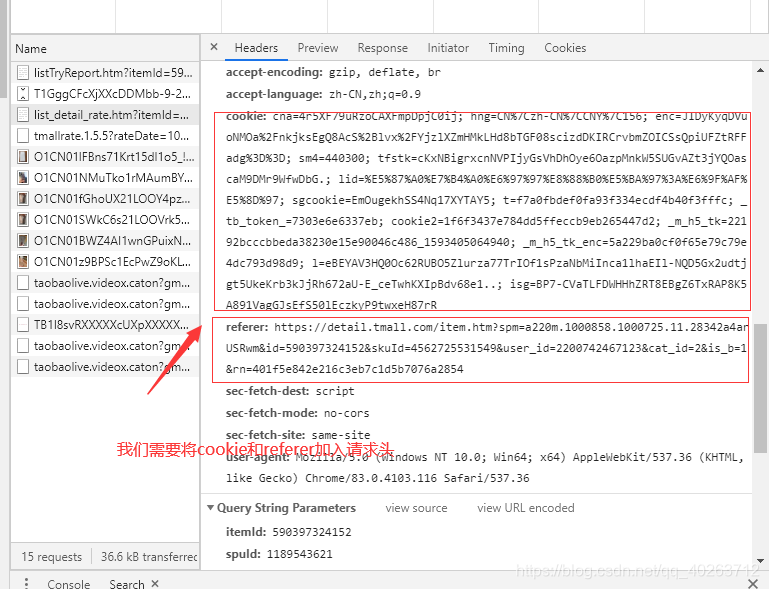
4、然后是请求头,因为淘宝的反爬策略需要你将cookie和referer加入请求头中才有数据返回
完整源码如下:
# -*- coding: utf8 -*-
import requests
import simplejson
import json
import time
import random
import pymysql
db = pymysql.connect(host='localhost', user='root', password='root', db='data', charset='utf8mb4')
cursor = db.cursor()
sql_insert = 'INSERT INTO tianmao(productid, tm_date,tm_name,tm_productcolor,tm_content,tm_addcontent) ' \
'VALUES (%s, %s, %s, %s, %s, %s)'
base_url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=586696084498&spuId=1149458431&sellerId=2453972737&order=1&append=0&content=1&tagId=&posi=&picture=&groupId='
header = {'Connection': 'keep-alive',
'Cookie': 'cna=K7c1Fm9QeEgCAbcLRkfyEEkC; lid=tb6215742558; UM_distinctid=16df69efef8368-0d17b004125eac-3a61'
'4f0b-1fa400-16df69efef9702; t=51922f4c39f93329c58b9cdc16acd994; uc3=lg2=W5iHLLyFOGW7aA%3D%3D&nk2'
'=F5RDLjy6p5kZXRnW&id2=UUphzpYqX5cXz4y8lQ%3D%3D&vt3=F8dByucleTWQ3pAvn3E%3D; tracknick=tb621574255'
'8; uc4=id4=0%40U2grFbWxeDPEmc0F057GUPxem7nmQZBW&nk4=0%40FY4I7WLlGHTv%2FDuByUGgKVV1pgUXZqQ%3D; lg'
'c=tb6215742558; enc=jPw8tSC%2FNjBsBFw9O%2BQ%2B0Shib7cT%2BihJoRr5%2BSGntM3mJ9wh%2FqOXRuMVHwhvVT6'
'UlTWGxK%2F0vnPx0IjOGpy9Kg%3D%3D; _tb_token_=34d1dd80e336e; cookie2=17bf660b9fa21e72fa378ab0acdf8'
'0d2; x5sec=7b22726174656d616e616765723b32223a22613736663562373461653765663439303261633764306563'
'326536653231393543493679774f3046454d507836636a796c656e6f7777453d227d; l=dBNaqkKuqkD7Fkz6BOfCCuI'
'8LnQ9mIRbzsPzw4OMrICP_HfkS7BVWZQAfOTDCnGVnstXR3RA-8MLBW8ZHyznhZXRFJXn9MpTNdTh.; isg=BISEfiwQhcc'
'DpTEUim39VA72VQK2Nakz175-sJ4llM8ZySaTxq7JlkwvCSG0UeBf',
'Referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.81.40c53838SohPgl&id=586696084498&skuId=3988162532751&user_id=2453972737&cat_id=2&is_b=1&rn=d85129182224147e63f360f636fb686d',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/75.0.3770.100 Safari/537.36'}
productId = '586696084498'
for i in range(1, 100, 1):
url = base_url + '¤tPage=%s' % str(i)
tb_req = requests.get(url, headers=header).text[11:-1]
print(tb_req)
tb_dict = simplejson.loads(tb_req)
tb_json = json.dumps(tb_dict, indent=2)
review_j = json.loads(tb_json)
print('正在爬取第%s页'%str(i))
for p in range(0, 20, 1):
ys = [review_j["rateDetail"]["rateList"][p]['auctionSku'].encode('utf-8').decode('utf-8')]
dat = [review_j["rateDetail"]["rateList"][p]['rateDate'].encode('utf-8').decode('utf-8')]
pl = [review_j["rateDetail"]["rateList"][p]['rateContent'].encode('utf-8').decode('utf-8')]
nam = [review_j["rateDetail"]["rateList"][p]['displayUserNick'].encode('utf-8').decode('utf-8')]
zp = [review_j["rateDetail"]["rateList"][p]['appendComment']]
if zp == [None]:
zp = zp
else:
zp = [review_j["rateDetail"]["rateList"][p]['appendComment']['content'].encode('utf-8').decode('utf-8')]
cursor.execute(sql_insert, (productId, dat, nam, ys, pl, zp))
db.commit()
time.sleep(random.uniform(2.5, 3))
print('Done!')
db.close()
如果对你有帮助的话请点个赞哦,有问题请发送邮箱w13145960812@163.com。
版权声明:本文为qq_40263712原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。