现如今,随着互联网业务需求的爆发式增长,分布式开发已成为常态。在分布式系统中,ID 生成服务是不可缺少的基础构件。ID,作为单个数据对象的唯一标识,一般要求具备全局唯一性;同时,在高并发场景下,对 ID 生成所带来的耗时问题也十分敏感;另外,时钟不同步、闰秒、时钟回拨等时间问题更是棘手。
业界已经提出了数种优秀的分布式 ID 解决方案和实现,各有不同的优缺点。美团点评,也开源了其使用的分布式 ID 服务系统:Leaf。这个源于名言“世界上没有两片完全相同的树叶”的系统,提供了高可靠、低延迟、全局唯一的 ID 生成,支撑起了众多的业务线。

Leaf 分布式ID生成
简介
Leaf,是 Meituan-Dianping(美团点评)在 Github 上开源的分布式 ID 生成服务,项目位于 https://github.com/Meituan-Dianping/Leaf,目前版本为 1.0.1。Leaf 在现有的分布式 ID 生成方案的基础上进行了优化,实现了两种模式方案:Left-segment 和 Leaf-snowflake,实现了具有:全局唯一性、趋势递增、单调递增、信息安全等不同的 ID 生成需求,并提供了缓存优化、高可容灾、和规避时钟问题等特性,能够满足绝大部分的分布式 ID 生成需求。
Leaf 项目
安装
Leaf 使用 Java 开发,使用 Spring Boot 框架启动一个 HTTP 服务来进行 ID 生成。首先拉取源码,然后使用 mvn 进行本地构建:
git clone git@github.com:Meituan-Dianping/Leaf.gitcd leafmvn clean install -DskipTestscd leaf-server进入到项目的 leaf-server 文件夹,使用 mvn 来启动 Spring Boot 服务:
mvn spring-boot:run或使用项目提供的部署脚本启动:
sh deploy/run.sh启动完成后,可以访问相应的测试 API 进行运行状态检验:
#segmentcurl http://localhost:8080/api/segment/get/leaf-segment-test#snowflakecurl http://localhost:8080/api/snowflake/get/test示例
Leaf 提供了两种 ID 生成方式:号段模式和 snowflake 模式,可以同时启用,也可以指定开启一种模式。 Leaf Server 的配置位于 leaf-server/src/main/resources/leaf.properties,包括:
- leaf.name:leaf 服务名
- leaf.segment.enable:是否开启号段模式
- leaf.jdbc.url:mysql 库地址
- leaf.jdbc.username:mysql 用户名
- leaf.jdbc.password:mysql 密码
- leaf.snowflake.enable:是否开启snowflake模式
- leaf.snowflake.zk.address:snowflake模式下的zookeeper地址
- leaf.snowflake.port:snowflake模式下的服务注册端口
如果使用号段模式,则需要使用数据库,配置 jdbc 相关配置,创建数据表
CREATE DATABASE leafCREATE TABLE `leaf_alloc` ( `biz_tag` varchar(128) NOT NULL DEFAULT '', `max_id` bigint(20) NOT NULL DEFAULT '1', `step` int(11) NOT NULL, `description` varchar(256) DEFAULT NULL, `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`biz_tag`)) ENGINE=InnoDB;insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')如果开启了号段模式,启动服务后,可以访问 http://localhost:8080/cache 查看监控页面。 而如果使用 Snowflake 模式,则需要连接 Zookeeper,配置 snowflake 相关配置。
Leaf 的两种模式各不相同,使用场景也不一样。 号段模式,是在数据库生成 ID 的方案上优化得到的。通过从数据库批量获取 ID,每次获取一个号段的值,该号段消耗完毕后,再去数据库获取,大大减轻了数据库的压力。同时,对于不同的发号需求,使用 biz_tag 字段进行区分,实现互相隔离,互不影响,数据库扩容时,只需根据 biz_tag 字段进行分库分表即可。
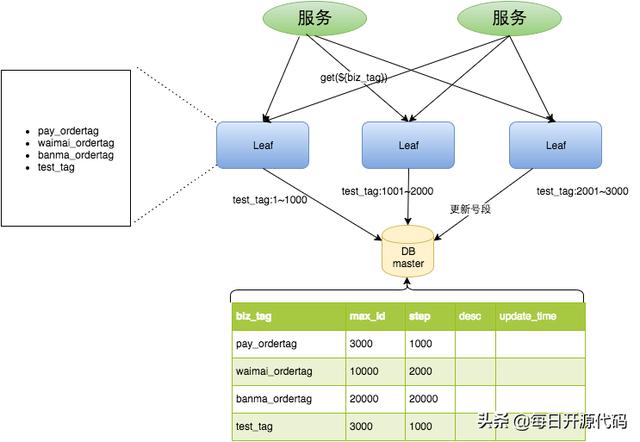
号段模式生成
此外,号段模式还实现了双 buffer 优化,使用两个号段缓存区,当当前的号段已经消耗了 10% 的时候,如果下一个号段还未更新,就启用一个线程去更新;而如果当前号段消耗完毕,就直接切换到另一个缓存区,继续进行消费。通过双缓存方式,降低了在缓存区号段消耗完毕时的临界点,由于网络抖动等各种因素所带来的阻塞,提高了系统的性能和稳定性。
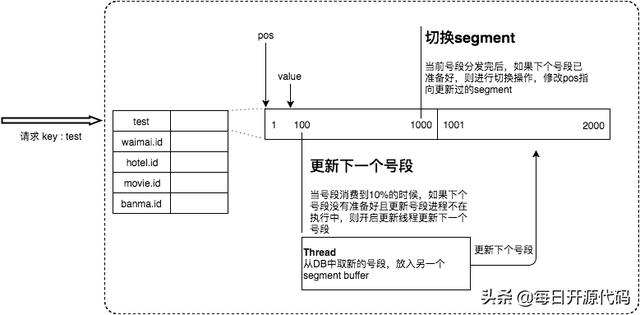
双缓存优化
对于一个基于数据库的 ID 生成方案,可用性十分重要。Leaf 实现了高可用容灾,采用一主两从的方式,主从间采用半同步方式同步数据。同时,Leaf 服务分 IDC 部署,服务调用时优先调用同机房的 Leaf 服务,并提供了过载保护、一键截流、动态流量分配等保护措施。
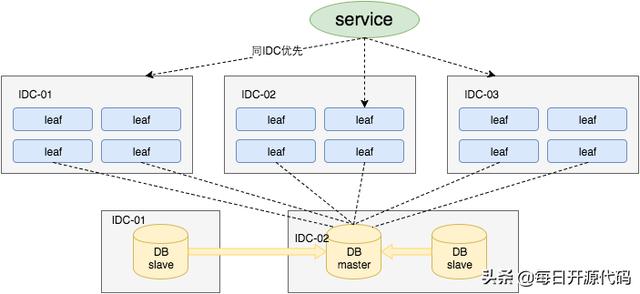
高可用容灾
尽管拥有着众多的优点,号段模式还是存在不足的。号段模式方案使用了基于数据库的方式,生成的 ID 序列是趋势递增的,同时 ID 号是可计算的,ID 之间的差值是有业务意义的。这种 ID 序列在某些内部使用场景是十分实用的,但对于如订单号等外部应用场景而言,其并不适用。趋势递增的订单号,使得竞争对手可以简单地从订单号就能估算出一天的业务订单量,这对于数据保护是非常不利的。
Snowflake 模式,则基本沿用了经典的 Twitter 开源的 Snowflake 算法实现,使用 1 + 41 + 10 + 12 的方式组装订单号。对于小规模场景,订单号中的 workerID 可以手动配置,大规模应用中则需要引入 Zookeeper 自动配置。

Snowflake算法
Leaf 实现了对于 Zookeeper 的弱依赖,每次到 Zookeeper 拿数据时,都会在本地缓存一个 workerID 文件,避免了 Zookeeper 出现问题时带来的服务无法正常运行。
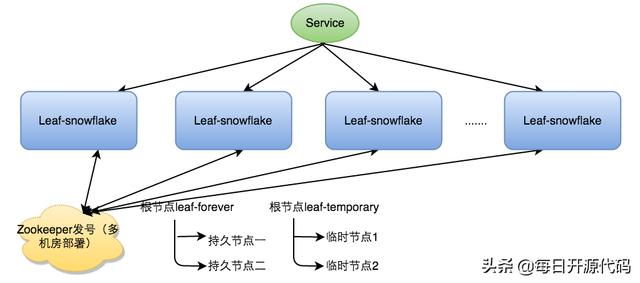
Zookeeper配置
对于类 Snowflake 实现而言,一个绕不过去的问题就是时钟问题。Snowflake 的 ID 生成算法的主体部分就是一个时间戳,在这种对于时间敏感的场景下,服务器时钟的可靠性是不足够的,如果出现时钟回拨,那么就可能会生成重复的 ID,破坏 ID 生成的全局唯一性在,这在几乎所有应用中都是不可接受的。
Leaf 利用了 Zookeeper 实现一个 leaf_forever 节点,服务启动时首先检查该节点,并比较系统时间和节点记录时间。若发生回退情况,直接发出警报。而若 leaf_forever 未被写过,则通过 RPC 获取所有临时节点的系统时间,使用平均化的方式,判断系统时间是否准确,若时间偏移过大则进行警报。Leaf 的时钟策略,成功地在线上避免了 2017 年的闰秒所造成的时钟回拨问题,可以说是十分成功的。
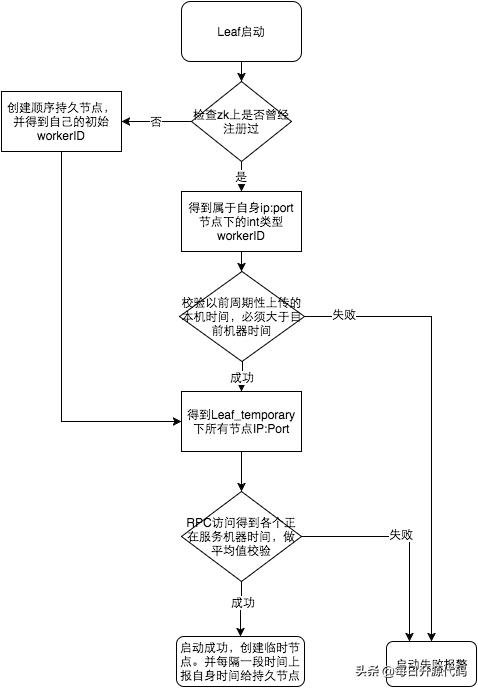
时钟回拨问题策略
总结
Leaf 作为一个分布式 ID 生成服务,提供了优化后的号段模式和 Snowflake 模式的 ID 生成策略,可以适应不同场景的需求。其对于已有方案进行了在包括性能、可用性、稳定性和安全性方面的提升,利用包括双缓存、高可用容灾、时钟回拨判断等技术,实现了一个可靠的高性能 ID 生成服务,为分布式系统提供了一个稳固的基石,十分值得在业务中进行使用。