最近运行了github上的一个deepvo代码,在此做一个学习笔记。
1. 文章以及整体结构
文章:DeepVO: Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks(基于深度循环卷积神经网络的端到端视觉里程计)
作者:Sen Wang, Ronald Clark, Hongkai Wen and Niki Trigoni
来源:ICRA2017
deepvo网络结构如下:CNN+RNNs (单目VO)
CNN网络的结构:
CNN分析:
- CNN学习的是几何特征。
RNNs网络的结构: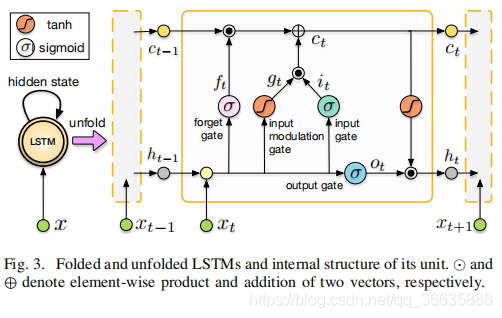
RCNNs分析:
将卷积层6之后提取的特征放入RCNNs进行建模。
两种激活函数:tanh函数、sigmod函数
LSTM神经元的输入有三部分:当前网络的输入Xt,上一时刻的输出ht-1、上一时刻的单元状态Ct-1
ht-1和xt进入细胞后乘以各自的权重然后作加法。
细胞内更新过程:
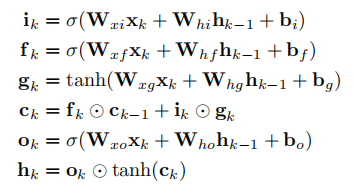
代价函数和优化:
将系统看成条件概率模型:xt发生的条件下Yt发生的概率
单目RGB图像序列Xt=(x1,…,xn),位姿Yt=(y1,…,yn)随时间的条件概率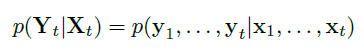
视觉里程计的优化参数θ*:找最优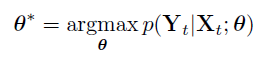
即真实位姿与估计位姿之间的欧式距离最小。损失函数由所有的位置p和方向φ的均方差(MSE)组成。(ϕ为欧式角)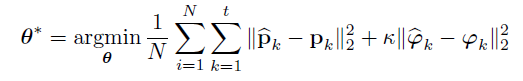
参考的deepvo解析文章:【泡泡图灵智库】DeepVO
自己的理解:
a. 使用一种新型的网络–深度递归卷积神经网络(RNNs),设计出一种新颖的端到端的单目vo框架。
b.网络结构为CNN+RNNs,CNN自动学习有效的特征表示,RNN对时序模型(运动模型)、数据关联模型(图像序列)进行隐式建模。
c.使用的数据集为KITTI数据集中的灰色图像集为: data_odometry_poses.zip和data_odometry_gray.zip
2. 代码运行:
参考的代码:https://github.com/Kallaf/Visual-Odometry
数据集:KITTI官网
odometry-------官网下载彩色数据集。color 65GB
 运行环境:.ubuntu16.04+Python+创建一个虚拟环境,在虚拟环境中安装tensorflow、opencv、opencv-contrib+jupyter notebook
运行环境:.ubuntu16.04+Python+创建一个虚拟环境,在虚拟环境中安装tensorflow、opencv、opencv-contrib+jupyter notebook
创建虚拟环境教程链接:ubuntu16.04下安装&配置anaconda+ tensorflow 新手教程
安装完之后测试一下import cv2,看是否会报错,如果报错,则参考链接:No module named cv2的完美解决方法!
然后在运行代码时,还会出现一个关于CV2的问题:
ImportError: /opt/ros/kinetic/lib/python2.7/dist-packages/cv2.so: undefined symbol: PyCObject_Type
可以用以下方法:
import sys
sys.path.remove('/opt/ros/kinetic/lib/python2.7/dist-packages')
3. 运行注意事项:
a. 数据集很大,两个文件一共23GB,为了下载数据集,我买了迅雷的会员,下载了一天一夜才搞定(请不要嘲笑我,哈哈)下载完之后发现ubuntu内存不够,安装双系统的时候只分了60G(不知道当时脑子咋想的,还觉得60G很大了,O(∩_∩)O~)下载好数据集后,由于空间不够,连解压都解压不了,悲痛欲绝,然后我又把自己的ubuntu扩容到了快300G,ubuntu16.04的扩容方法在下一篇博客。
b.参考的源代码中的Mount drive部分不需要运行,这部分是用了谷歌上的虚拟GPU,我们在自己的笔记本上运行,不需要这部分,如下截图:
(如果自己有谷歌账号,想在谷歌上使用虚拟GPU运行,可以点击open in colab) c.需要修改的部分:自己的数据集存放位置。数据集解压之后都会有一个dataset文件夹,把sequences和poses两个文件夹放同一个dataset文件夹下,代码中的数据集路径为…/dataset/
c.需要修改的部分:自己的数据集存放位置。数据集解压之后都会有一个dataset文件夹,把sequences和poses两个文件夹放同一个dataset文件夹下,代码中的数据集路径为…/dataset/
4. 总结:
目前只是运行出来和github中的结果一样,但有很多不理解的地方,下一步理解之后再来更新。
************************** 2020.9.19更新:*****************************
之后使用了彩色数据集运行,65G,比较大。
代码中有错误,需要修改:
pose = self.get6DoFPose(poses[i+1,:]) - self.get6DoFPose(poses[i,:])计算出的相对位姿会保存在estimated.txt文件中,但是保存的是两针之间之间的位姿差,还需要将其累积,还原出真实的位姿。
给出的代码中bitchsize值为1,相当于在线学习,可以更改为32,加快训练速度。
学习率大概设置为0.00001效果较好。
需要很强的硬件支持,很多资料上使用的是ti系列显卡,12g独立显卡两个,运行100代话费将近20小时。