本篇文章给大家带来的内容是关于超简单的Python爬虫之网易云音乐的下载,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
目标
偶然的一次机会听到了房东的猫的《云烟成雨》,瞬间迷上了这慵懒的嗓音和学生气的歌词,然后一直去循环听她们的歌。然后还特意去刷了动漫《我是江小白》,好期待第二季...我多想在见你,哪怕匆匆一眼就别离...
好了,不说废话了。这次的目标主要是根据网易云中歌手的ID,下载该歌手的热门音乐的歌词和音频,并保存到本地的文件夹中。
配置基础Python
Selenium(配置方法参照:Selenium配置)
Chrome浏览器(其它的也可以,需要进行相应的修改)
分析
如果爬取过网易云的网站的小伙伴都应该知道网易云是有反爬取机制的,POST时需要对一些信息的参数进行加密函数的模拟。但是这里为了简便,小白也能理解。直接使用了Selenium来模拟登录,然后使用接口来直接下载音乐和歌词。
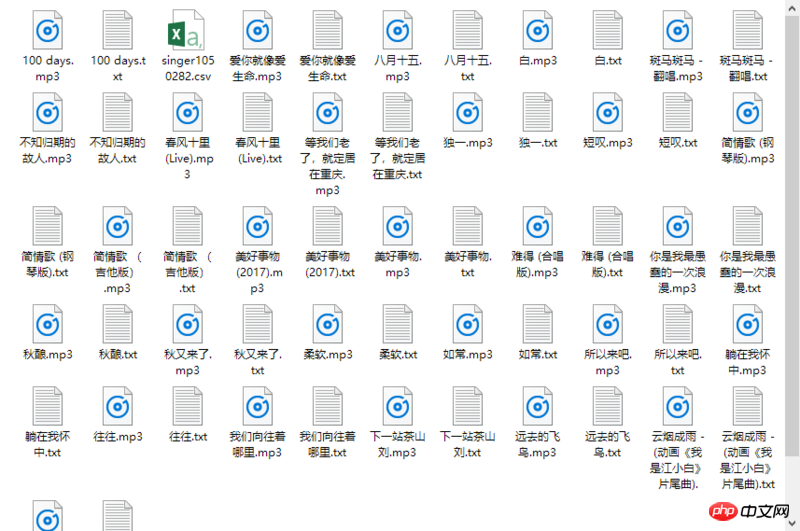
实验步骤:根据歌手ID获取该歌手的热门歌曲列表,歌曲名称和链接,并保存到csv文件中;
读取csv文件,根据歌曲链接,提取歌曲ID,然后利用相应的接口,下载音乐和歌词;
将音乐和歌词保存到本地。
Python实现
该部分将对几个关键的函数进行介绍...
获取歌手信息
利用Selenium我们就不需要看对网页的请求了,直接可以从网页源码中提取相应的信息。查看歌手页面源码可以发现,我们需要的信息在iframe框架内,所以我们先需要切换到iframe:browser.switch_to.frame('contentFrame')
继续往下看,发现我们需要的歌曲名字和链接是在id="hotsong-list"的标签中,然后每一行对应的是一个tr标签。所以先获取所有的tr内容,然后遍历单个tr。data = browser.find_element_by_id("hotsong-list").find_elements_by_tag_name("tr")
注意:前一个是find_element,后一个是find_elements,后者返回一个列表。
接下来就是解析单个tr标签的内容,获取歌曲名字和链接,可以发现两者在class="txt"标签中,而且链接是href属性,名字是title属性,可以直接通过get_attribute()函数获取。
 for i in range(len(data)):
for i in range(len(data)):
content = data[i].find_element_by_class_name("txt")
href = content.find_element_by_tag_name("a").get_attribute("href")
title = content.find_element_by_tag_name("b").get_attribute("title")
song_info.append((title, href))
下载歌词
网易云有个获取歌词的接口,链接为:http://music.163.com/api/song...
链接中的数字就是歌曲的id,所以我们拥有歌曲id后,可以直接从该链接下载歌词,歌词文件是json格式,所以我们需要用到json包。
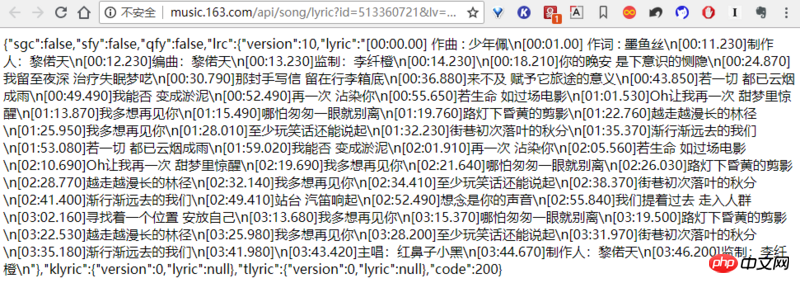
而且直接获取的歌词中,每行有一个时间轴,需要用正则表达式来剔除,完整代码如下:def get_lyric(self):
url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(self.song_id) + '&lv=1&kv=1&tv=-1'
r = requests.get(url)
json_obj = r.text
j = json.loads(json_obj)
lyric = j['lrc']['lyric']
# 利用正则表达式去除时间轴
regex = re.compile(r'\[.*\]')
final_lyric = re.sub(regex, '', lyric)
return final_lyric
下载音频
网易云也提供了音频文件的接口,链接为:http://music.163.com/song/med...
链接中的数字为歌曲的id,可以直接根据歌曲的id来下载音频文件。完整代码如下:def get_mp3(self):
url = 'http://music.163.com/song/media/outer/url?id=' + str(self.song_id)+'.mp3'
try:
print("正在下载:{0}".format(self.song_name))
urllib.request.urlretrieve(url, '{0}/{1}.mp3'.format(self.path, self.song_name))
print("Finish...")
except:
print("Fail...")
相关推荐:
以上就是超简单的Python爬虫之网易云音乐的下载的详细内容,更多请关注php中文网其它相关文章!

本文原创发布php中文网,转载请注明出处,感谢您的尊重!