目录
1.2 reinforcement learning of policy network
1. Alpha Go
- alphaGo actually uses a 19*19*48 tensor to store other information.
- number of possible sequence of actions is
- training in 3 steps:
- initialize policy network using behavior cloning.
- train the policy network using policy gradient.
- after training the policy network, use it to train a value network.
- Execution (actually play Go games)
- Do Monte Carlo Tree Search (MCTS) using the policy and value networks.
1.1 Behavior Cloning
Behavior cloning is imitation learning rather than reinforcement learning.
problem:会对未见过的操作懵逼,然后break down。
1.2 reinforcement learning of policy network

1.3 Alpha Zero
- AlphaGo Zero does not use human experience. (no behavior cloning)
1.4 Monte-Carlo Tree Search
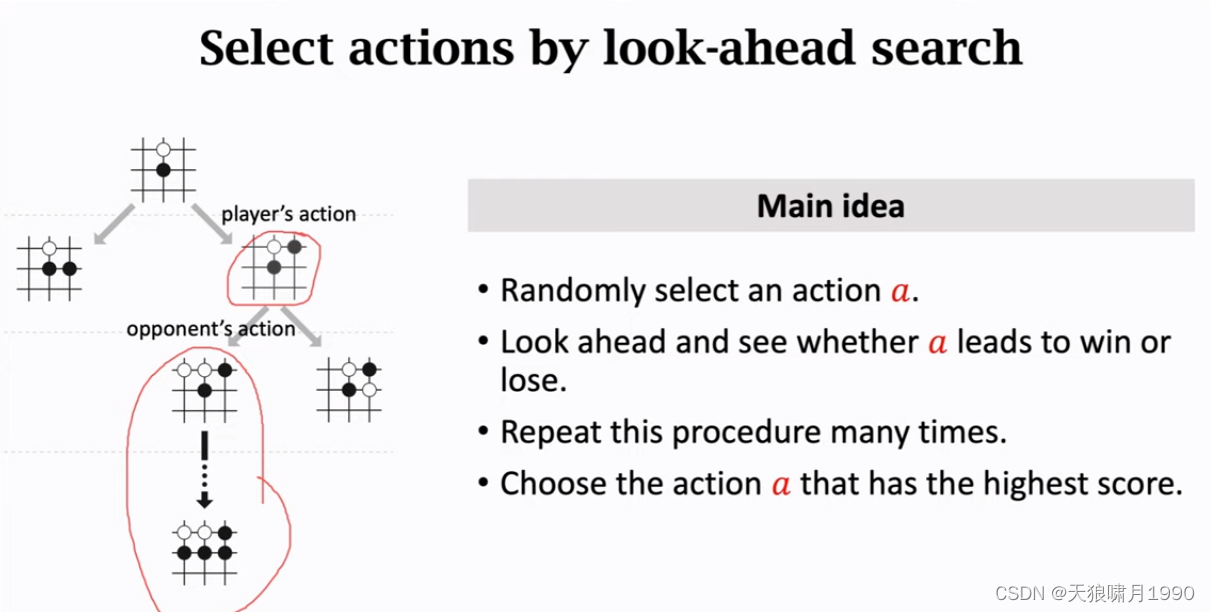
- step 1: Selection
- step 2: Expansion
- step 3: Evaluation
- step 4: Backup
参考
版权声明:本文为qq_33419476原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。