目录
一、Spring Bean的生命周期
1.Spring Bean的创建生命周期:
bean:被spring管理的对象是bean,bean工厂获得的对象就是bean,
对象:自己手动创建的对象,不是被spring所管理的,是对象但是不是bean
spring容器创建bean的过程:
UserService 类
-------》无参构造方法(实例化)推断构造方法
-------》对象
-------》依赖注入(加了@Autowired注解的赋值)
-------》a()初始化前(@PostConstruct)
-------》初始化(InitializingBean)
-------》初始化后(AOP)
-------》代理对象
-------》bean
UserService 类对象的创建过程:
扫描包,类上面有@Compoent ,@Service,@Controller的注解的调用无参构造方法创建对象
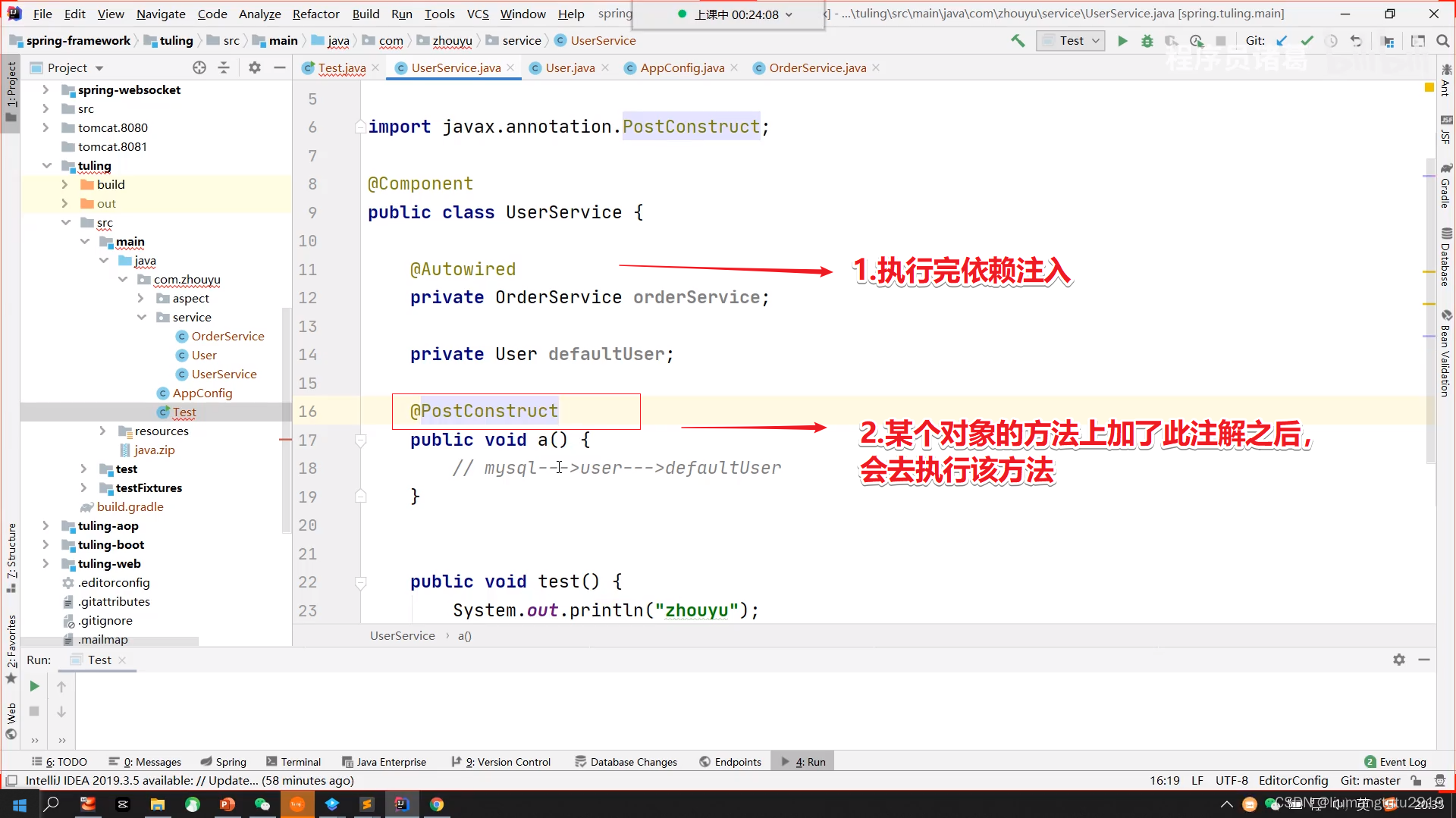
初始化前(@PostConstruct):
想要spring创建UserService的时候就初始化 默认defaltUser,初始化用户的权限信息(去数据库查询到权限信息,然后封装成User对象,赋值给UserService的deafultUser属性),可以使用注解@PostConstruct
如果自己写一个类似@PostConstruct注解的方法如何写?
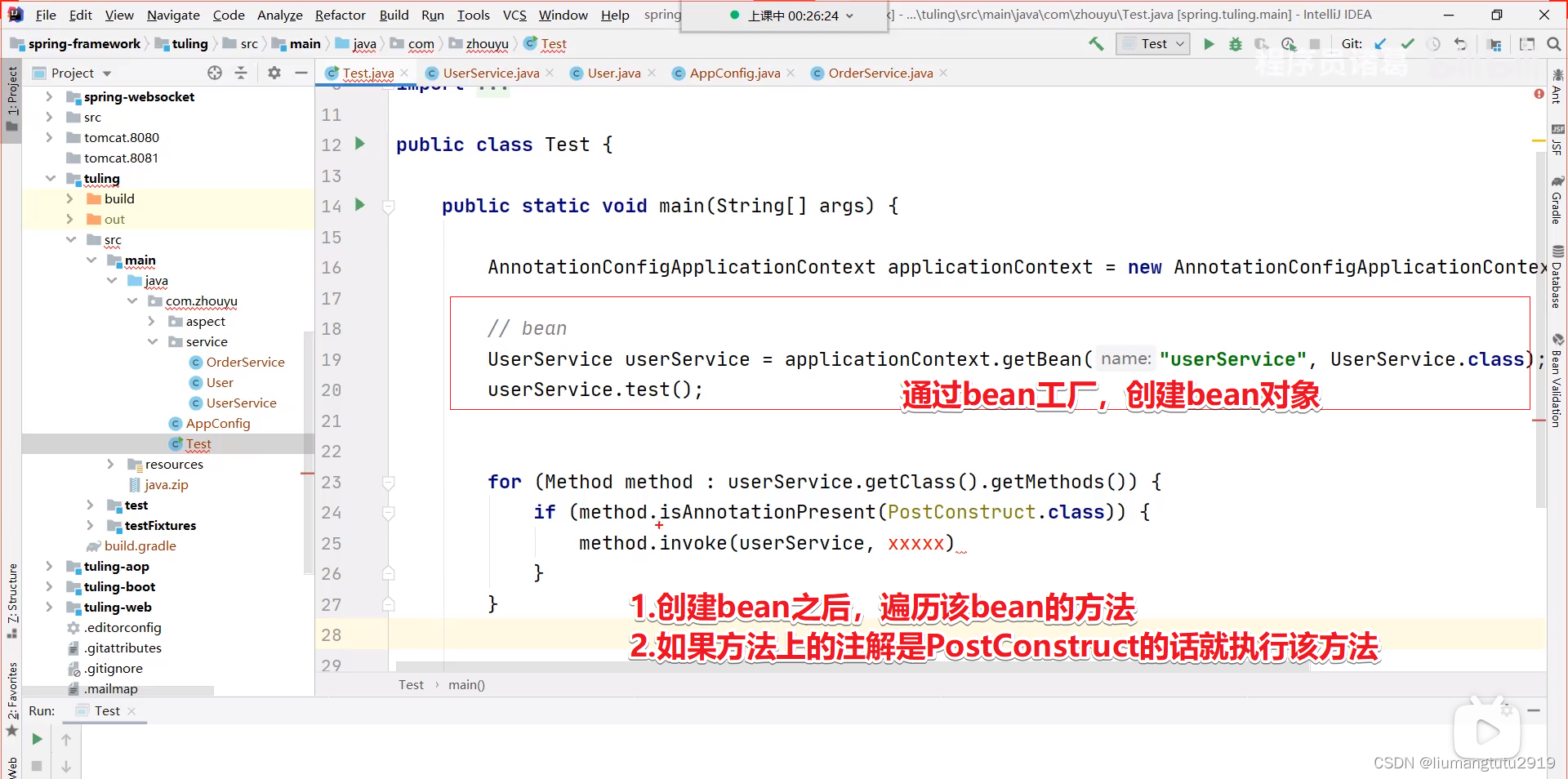
初始化(InitializingBean):
判断一个类是否实现了InitializingBean接口,instanceof InitialzingBean,如果实现了该接口,就强转类型,再调用它的方法:((InitialzingBean)对象).afterPropertiesSet()
有默认的无参构造方法 + 有参构造方法:都可以使用
只有一个有参构造方法:可以使用
有多个构造方法,但是没有无参构造方法:这个时候会报错,提示找不到默认的无参构造方法,因为spring无法识别到需要用哪一个有参构造方法,如果想要使用其中的一个构造方法需要加上@Autowired注解(这样程序员就告诉了spring需要用哪一个有参构造方法,spring知道使用具体的某个构造方法值就不会报错了)
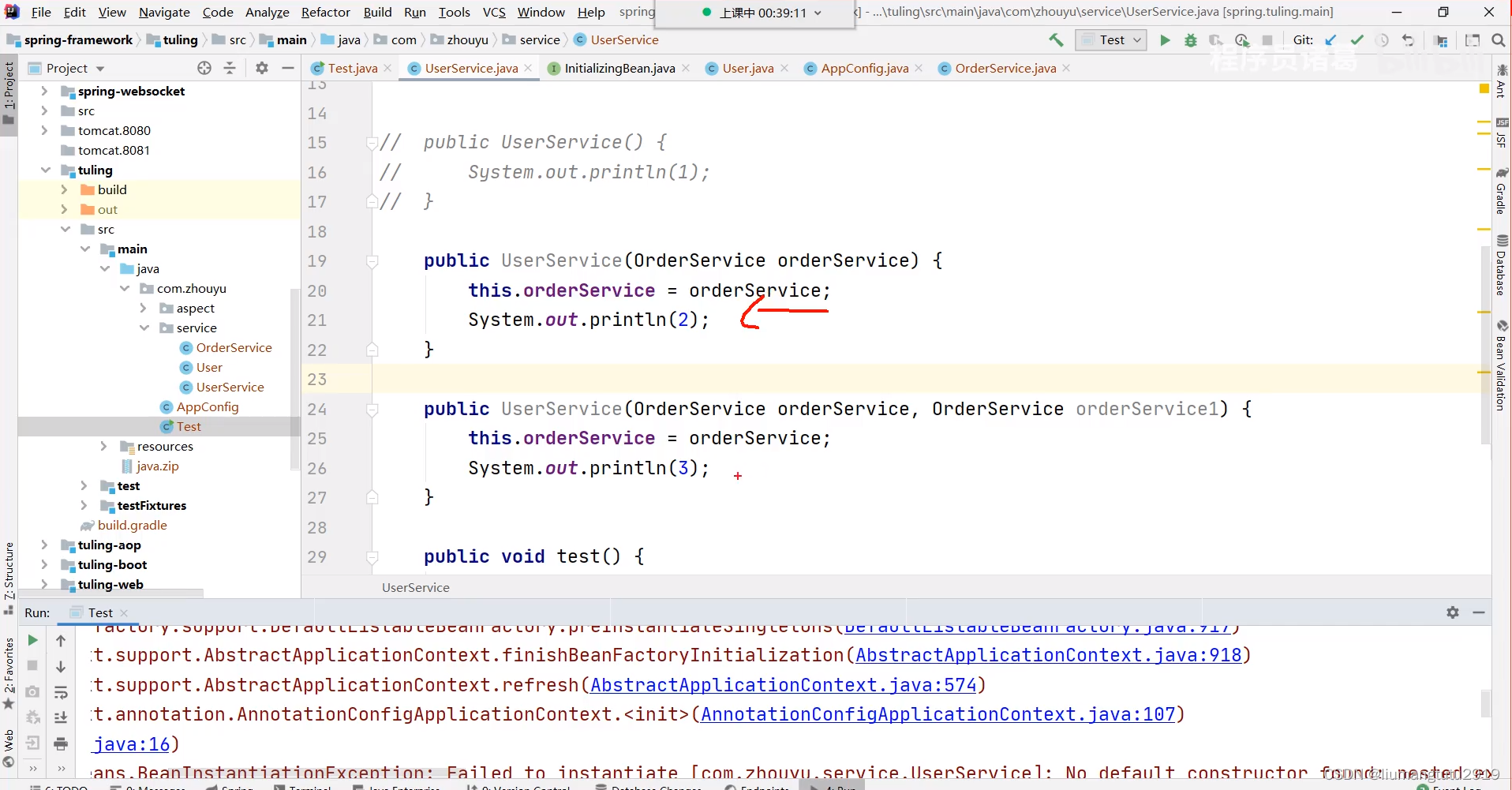
推断构造方法:
单例Bean 不等同于单例模式:
spring容器里面,不同的bean的name是唯一的
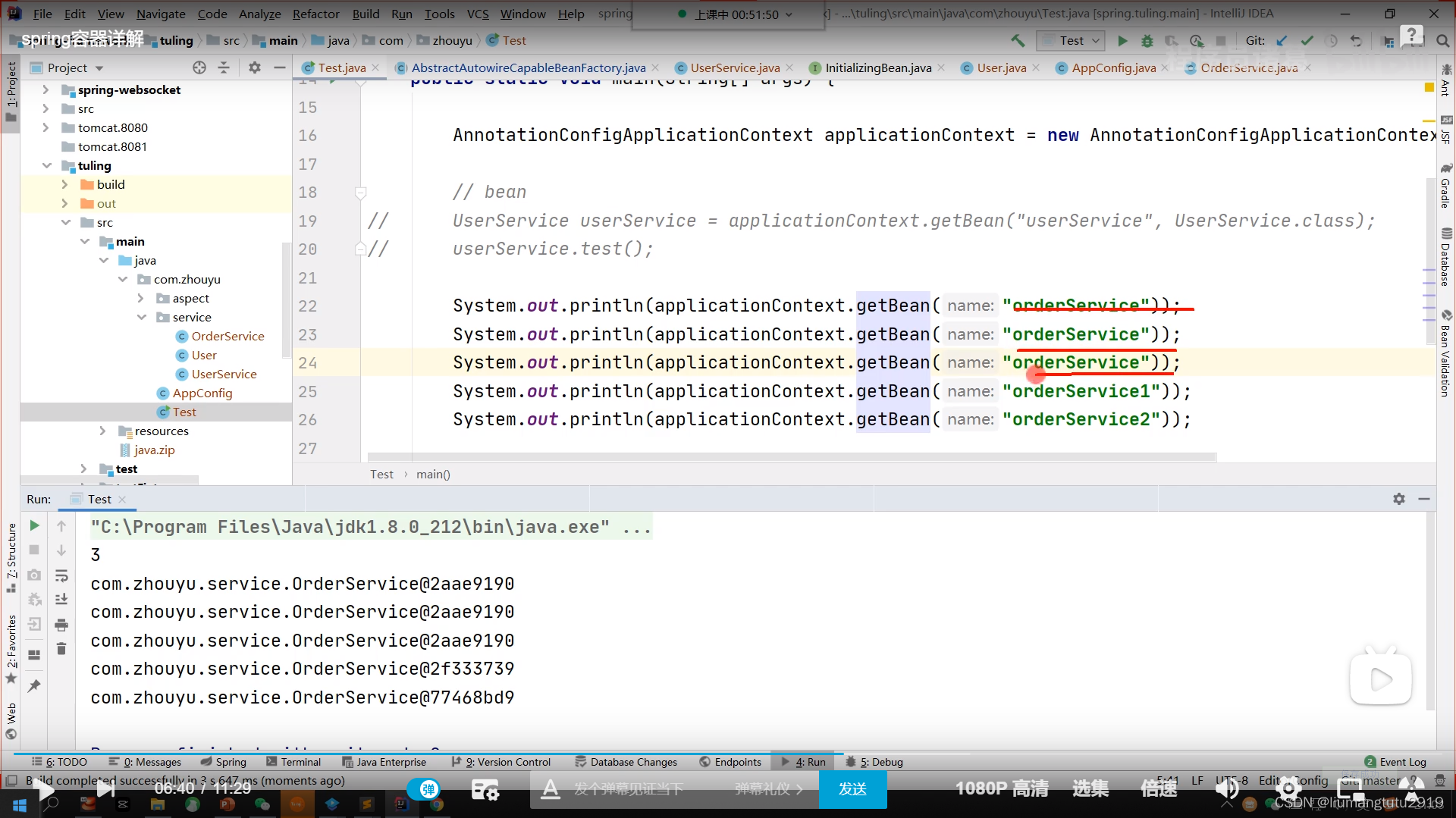
获取到name为orderService的bean都是同一个bean对象,这就是单例Bean
如果orderService不是单例Bean(假设是原型bean,独立bean),通过orderService从spring容器里面获取到的对象就不会是同一个对象,
spring底层如何实现单例bean的设计?
spring底层是使用map存储bean对象的,这样beanNam就是唯一的,同一个beanName获取到的bean对象都是同一个。Map ====等价于==== spring 容器
通过类型去容器里面寻找对象,类型找到3个对象 Map<OrderService, bean对象> orderService Map<OrderService, bean对象> orderService1 Map<OrderService, bean对象> orderService2 先根据类型找对象,找到3个,再根据name去找bean,可能一个都没有, 或者找到一个唯一的bean
当有3个bean对象的时候,(找name为orderService111的bean)找不到的时候spring会提示报错,提示找不到该bean
当只有1个bean对象的时候,(需要找找类型OrderService,name为orderService1 和 orderService2 的bean对象)这个时候不会报错,因为容器里面OrderService类型的bean对象只有一个,找到之后就直接返回,不再根据name去寻找
依赖注入(加了@Autowired注解的赋值):
过程和推断构造方法过程类似:
先去map里面通过类型找到bean,如果是单个就返回
如果通过类型找到的bean是多个,再通过name去寻找bean
初始化后(AOP)
cglib动态代理:如果没有实现接口,就使用的是cglib动态代理
jdk动态代理:如果实现了接口spring使用的就是jdk动态代理
到此步骤(初始化后(AOP))的时候 spring会判断对象是否需要aop
1.判断对象要不要进行AOP?
2.
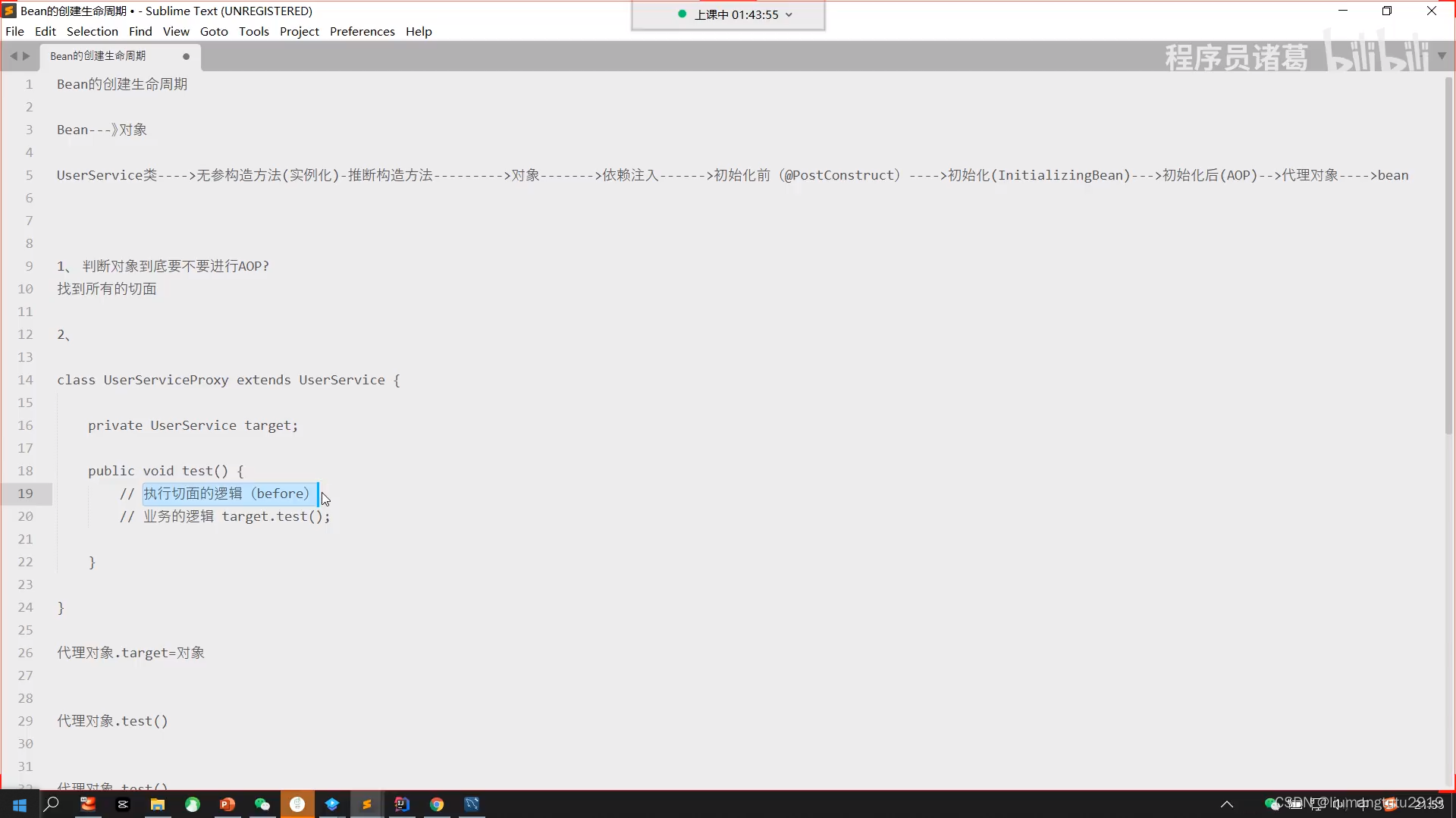
事务:
未加@Configuration注解的时候,使用事务,是不会回滚的
加上了@Configuration注解的时候,使用事务,抛异常的时候就会回滚
事务失效
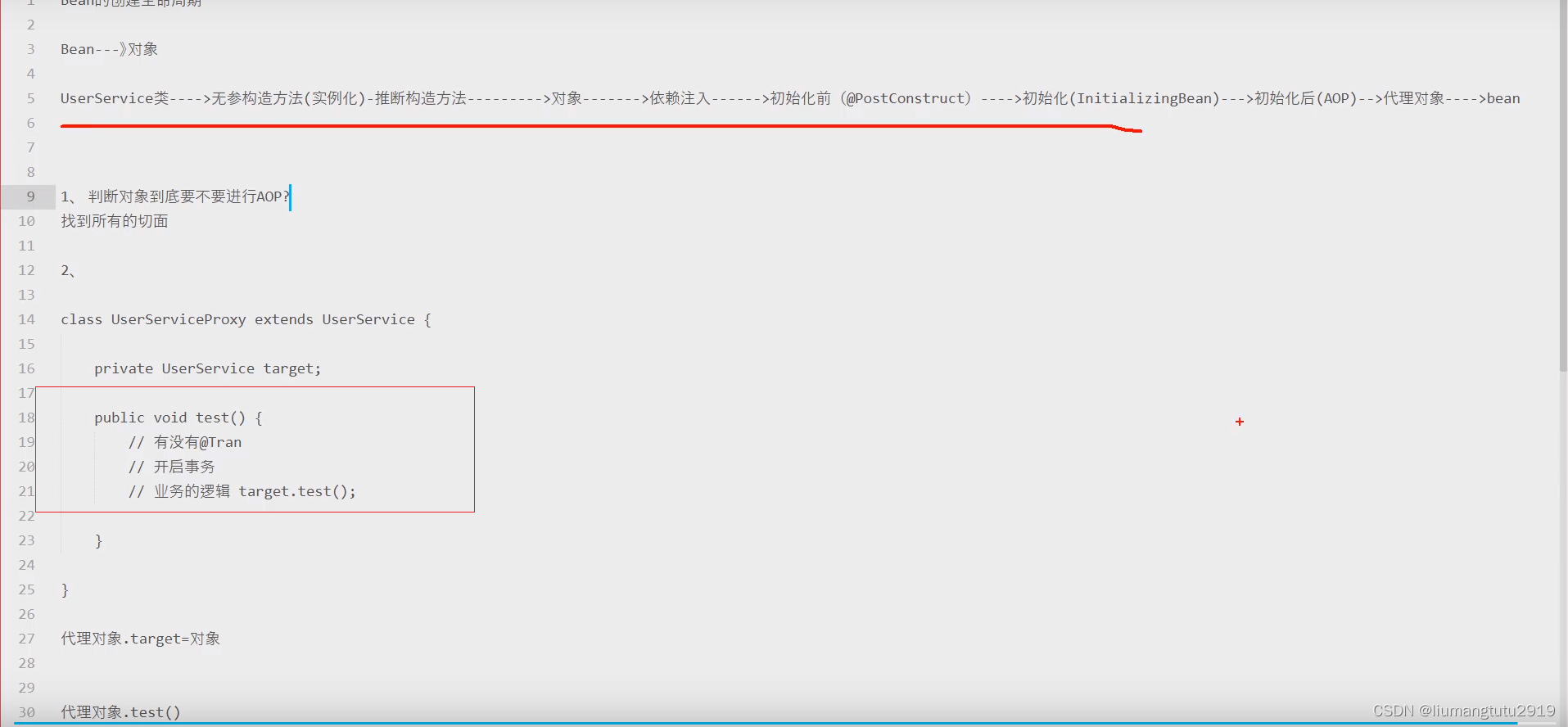
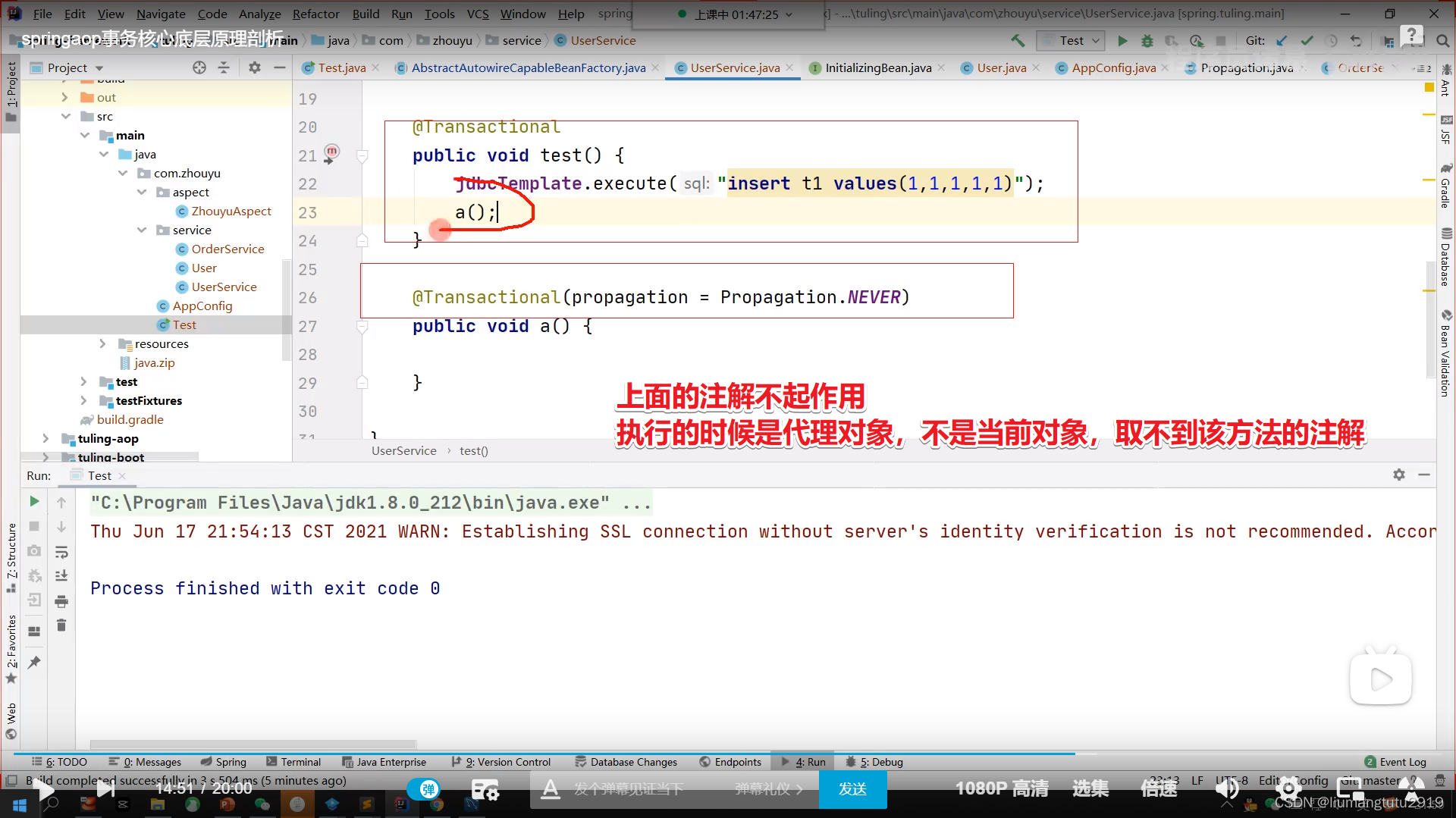
如何避免事务失效
1.UserService自己注入自己(注入的就是userService的代理对象),然后再调用a()方法
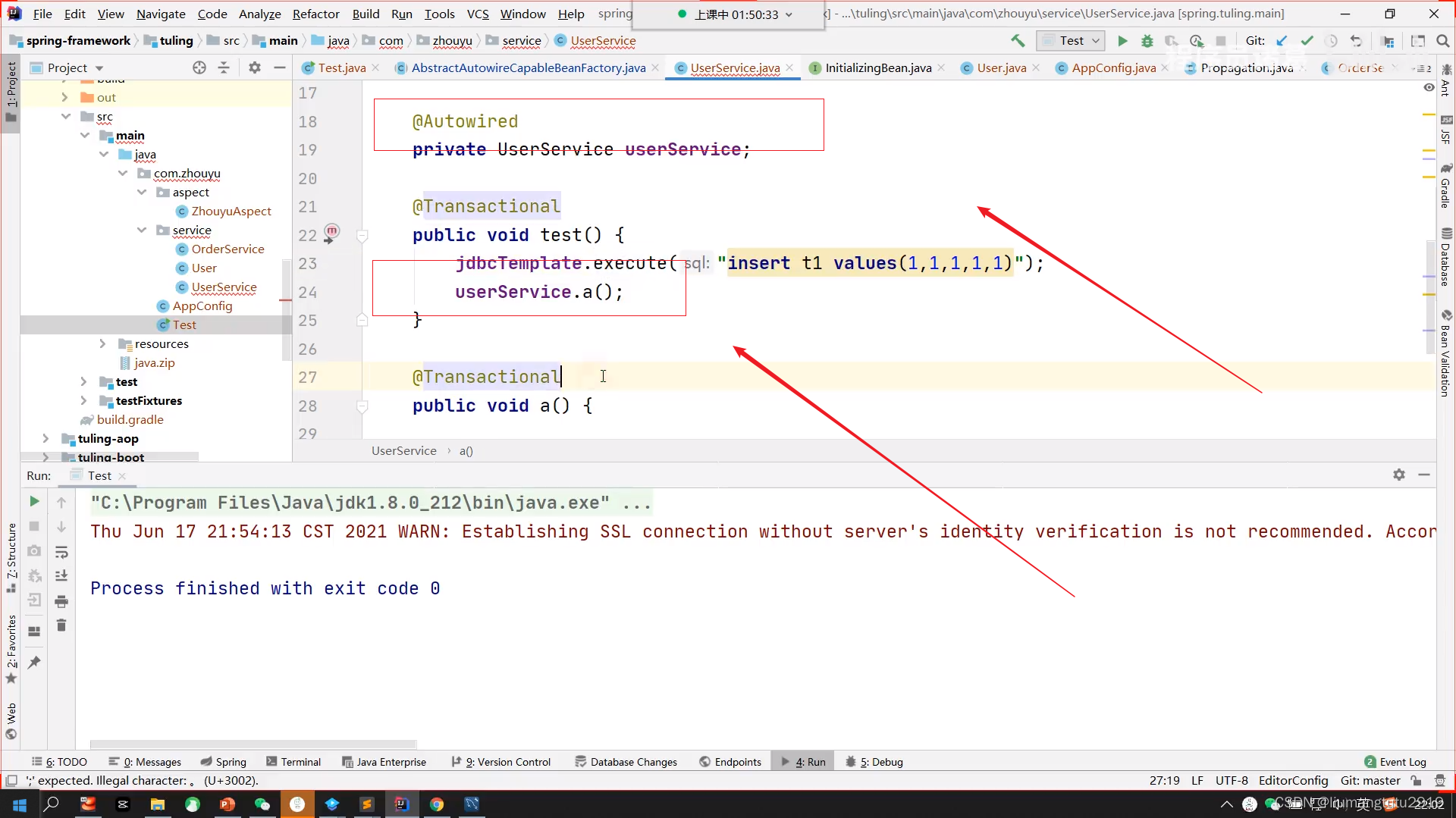
2.将方法写到另外的A类中,注入A类(注入的是A类的代理对象),用注入A类的对象(代理对象)调用a()方法就可以有效了
二、SpringMVC的执行流程
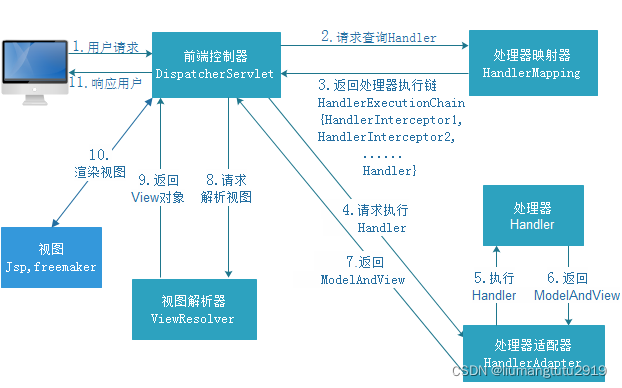
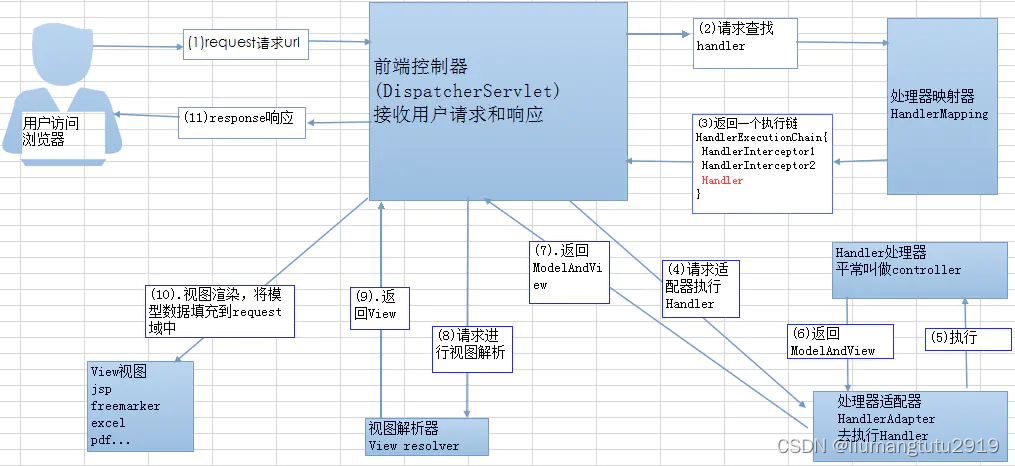
1.客户端发送请求到前端控制器DispatcherServlet
2.前端控制器根据请求路径进入相应的处理器
3.处理器调用相应的业务方法
4.处理器获取到相应的业务数据
5.处理器将组装好的数据交还给前端控制器
6.前端控制器将获取到的ModelAndView对象传给视图解析器ViewResolver
7.前端控制器获取到解析好的页面数据
8.前端控制器将解析好的页面返回给客户端
三、MyBatis
3.1一级缓存,二级缓存
一、mybatis缓存基本介绍
1、缓存:将相同查询条件的sql语句执行一遍后得到的结果存在内存或者某种缓存介质中,当下次遇到一模一样的查询sql时候不在执行sql与数据库交互,而是直接从缓存中获取结果,减少服务器的压力;
2、mybatis的查询缓存又分为一级缓存和二级缓存,
一级缓存的作用范围为同一个sqlsession,一级缓存是默认开启的
而二级缓存的作用范围为同一个namespace和mapper,二级缓存是默认不开启的
如何开启二级缓存:
1,打开总开关
在mybatis-config.xml文件中的标签配置开启缓存:
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>
2,在需要开启二级缓存的mapper.xml中加入caceh标签
<cache>
<cache/>
3,让使用二级缓存的POJO类实现Serializable接口3.2.MyBatis执行流程
1.首先加载Mapper配置文件的SQL映射文件,或者是注解相关的SQL内容
2.创建会话工厂,MyBatis通过读取配置文件信息来构造会话工厂SqlSessionFactory
3.创建会话,根据会话工厂,MyBatis就可以通过它来创建会话对象SqlSession,会话对象是一个接口,该接口中包含了对数据库的增删改查方法
4.创建执行器,因为会话对象不能直接操作数据库,所以它使用了一个叫做数据库执行器Executor的接口来帮它操作
5.封装SQL对象,在这一步,执行器将待处理的SQL信息封装到一个对象中MapperStatement,该对象包括SQL语句,输入参数映射信息和输出结果映射信息
6.操作数据库,拥有执行器和SQL信息封装对象就使用它们访问数据库了,最后返回操作结果,结束流程
3.3 MyBatis的使用
3.3.“#”和"$"的区别
1.“#”是预编译处理,
2.“$”是字符替换。
在使用“#”时,MyBatis会将SQL中的参数替换为“?”,配合preparedStatement的set方法赋值,这样可以有效防止SQL注入,保证程序运行的安全性