一、String类型的存储空间
String保存简单键值对时,key、value的数据量非常小时,保存数据时所消耗的内存空间比较多。例如:key:Long 占8字节,value:Long 占8字节,只需要16字节就可以了,实际保存后,每个占用了64个字节,这64个字节用在哪了?
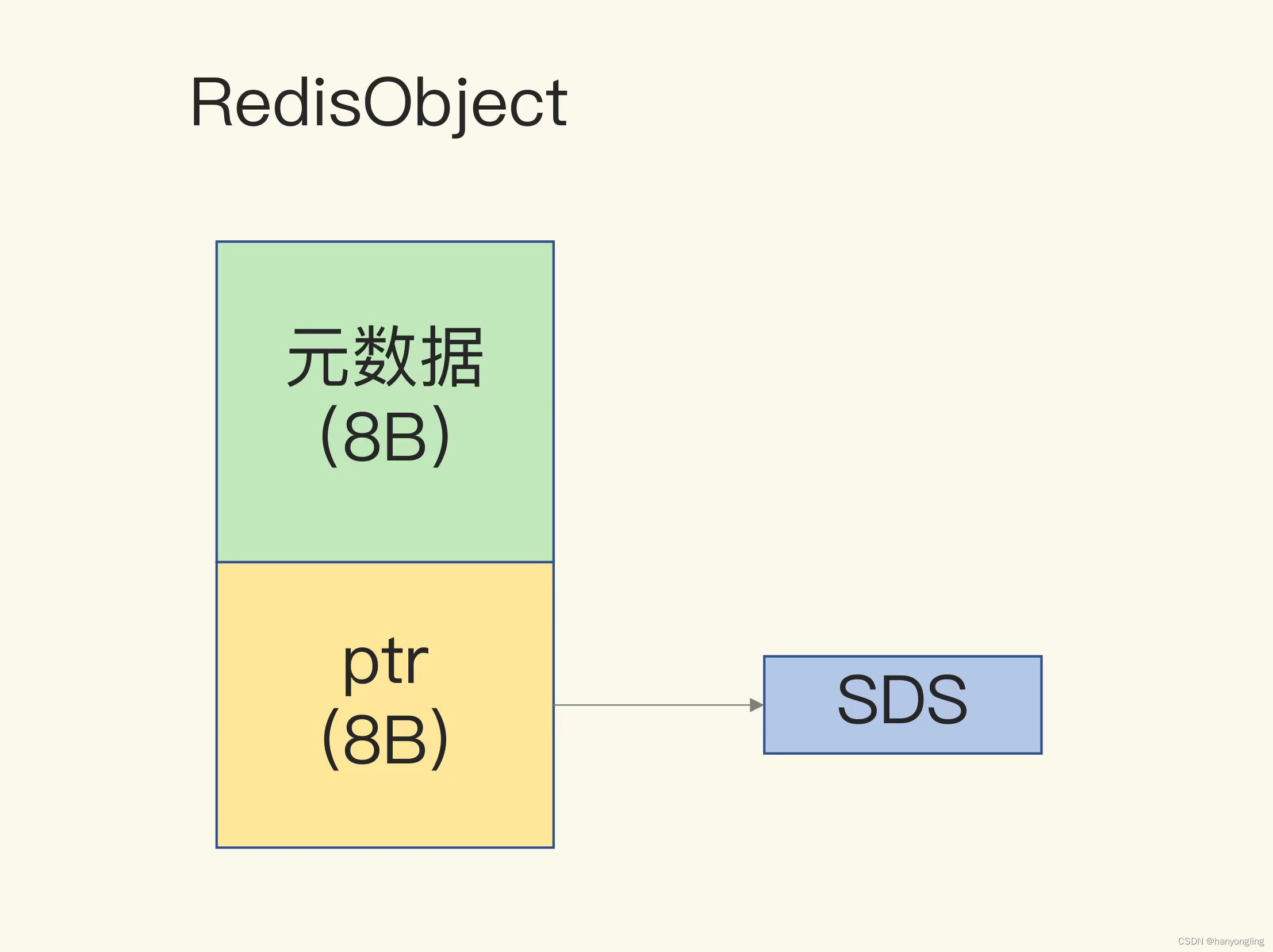
Redis不同的数据类型都用了一个RedisObject对像,8字节元数据和8字节的指针,指什指向具体数据实际数据。
String类型有三种编码方式:
1、int编码
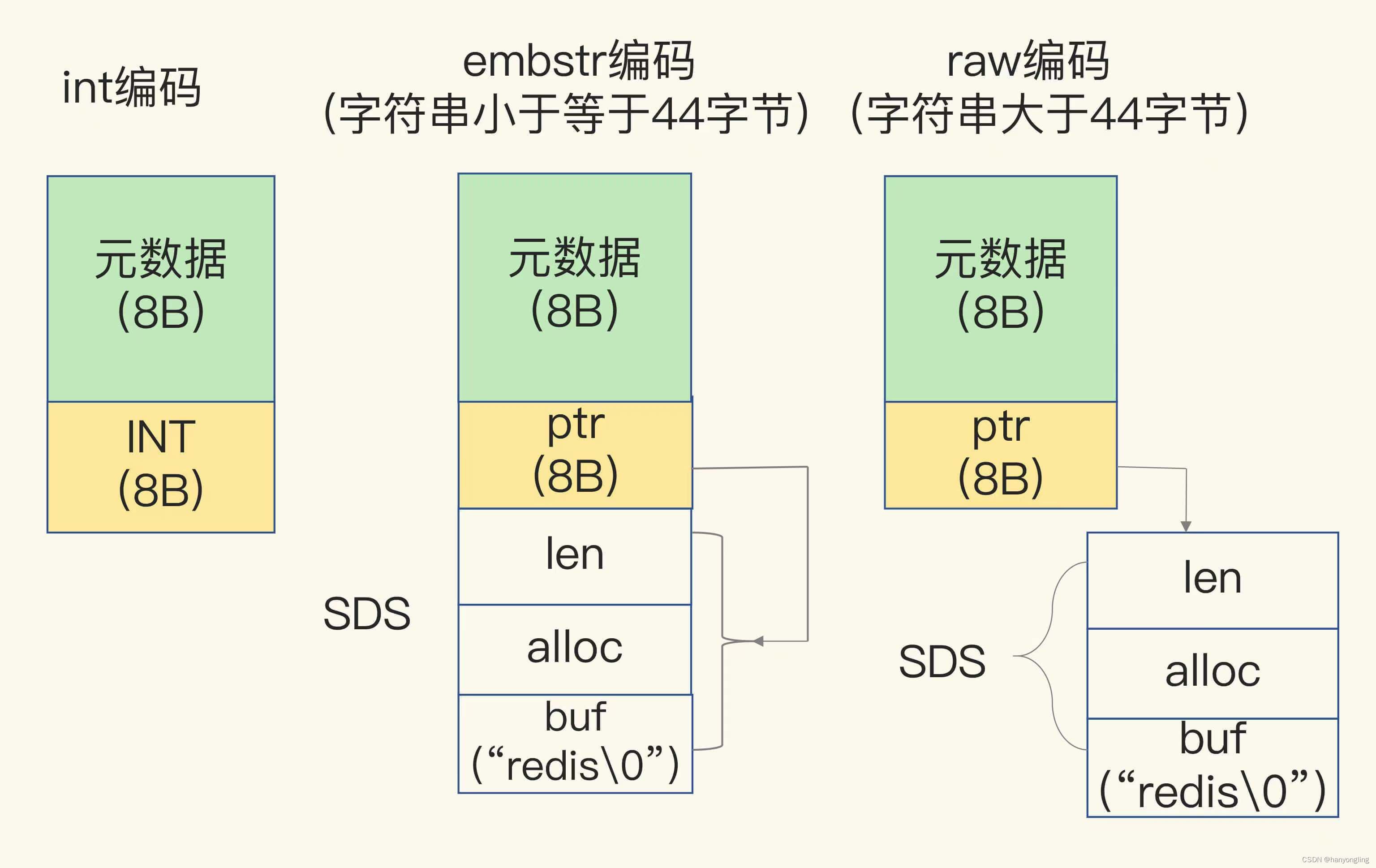
当保存64位有符号整数时,String类型会把它保存为一个8字节的Long类型整数,这种方式叫int编码。这种方式RedisObject的指针直接存储了Long的整数,没有额外的内存开销。
2、embstr编码
当保存的数据中含字符串时,String类型就会用简单的动态字符串(SDS)结构体来保存
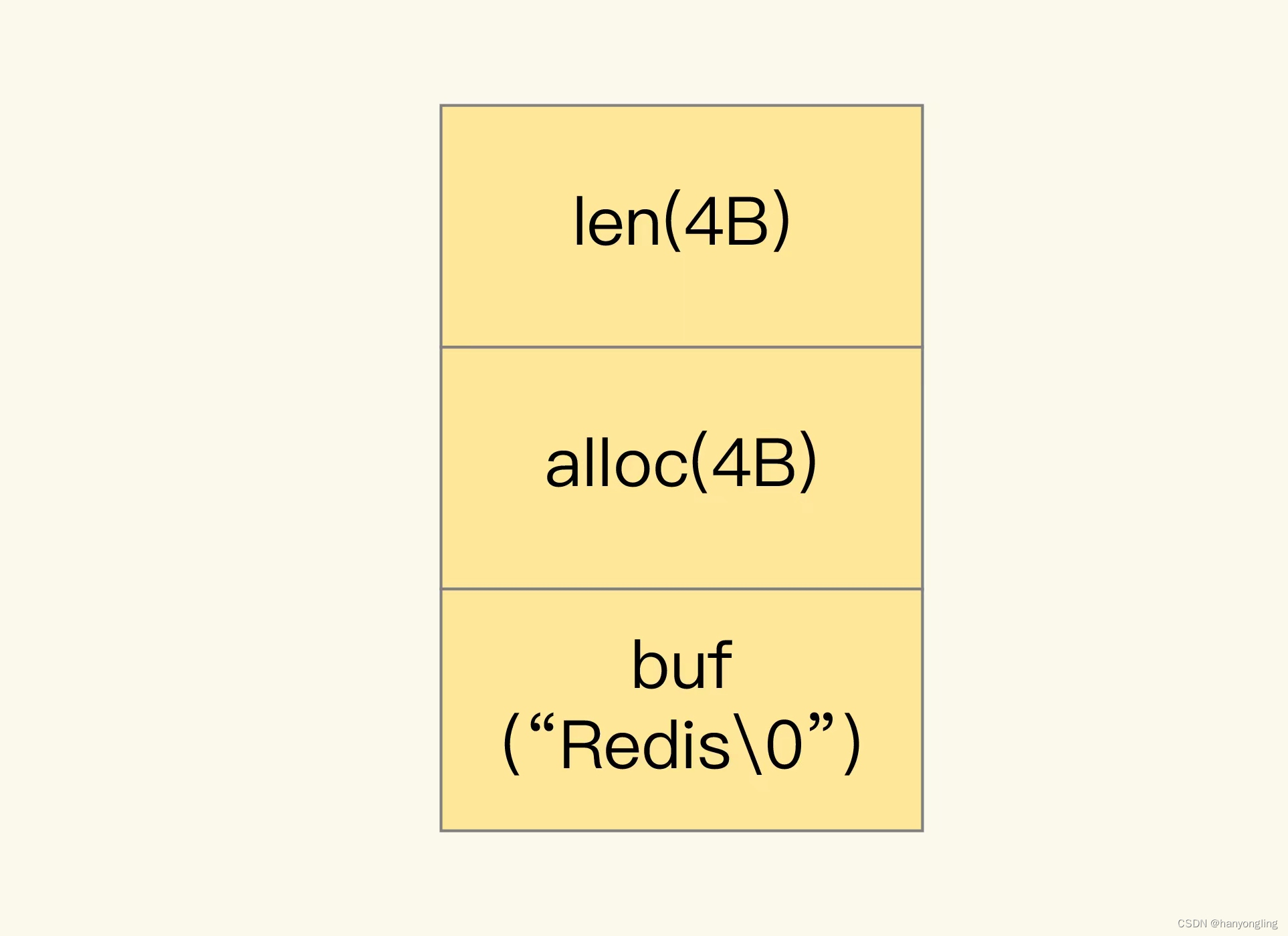
len:占4字节,表示buf长度
alloc:占4字节,表示buf的实际分配长度,一般大于len
buf:字节数据,保存的实际数据,结尾"\0"多占一个字节
字符串小于等于44字节时,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样可以避免内存碎片,这种布局方式称为embstr编码模式。
3、raw编码
当字符串大于44字节时,Redis就不再把SDS和RedisObject分配在一起了,SDS会分配独立的空间,并用指针指向SDS结构,这种方式称为raw编码模式。
三种编码模式示意图:
这样我们可以计算出Long的key,value在内存中的使用量了:
key、value都采用int编码,各占16字节,一共32字节,还有其它32个字节去哪了?
Redis会使用一个全局哈希表保存所有的键值对,哈希表的每一个项是一个dictEntry结构体,用来指向一个键值对。dictEntry结构中有三个8字节的指针,分别指向key,value,以级下一个dictEntry,三个指针共24个字节,内存分配库jemalloc会根据申请的字节数N,找一个比N大,但是最接近N的2的幂次数做为分配的空间,这里24个字节,内存会分配32个字节,如下图:
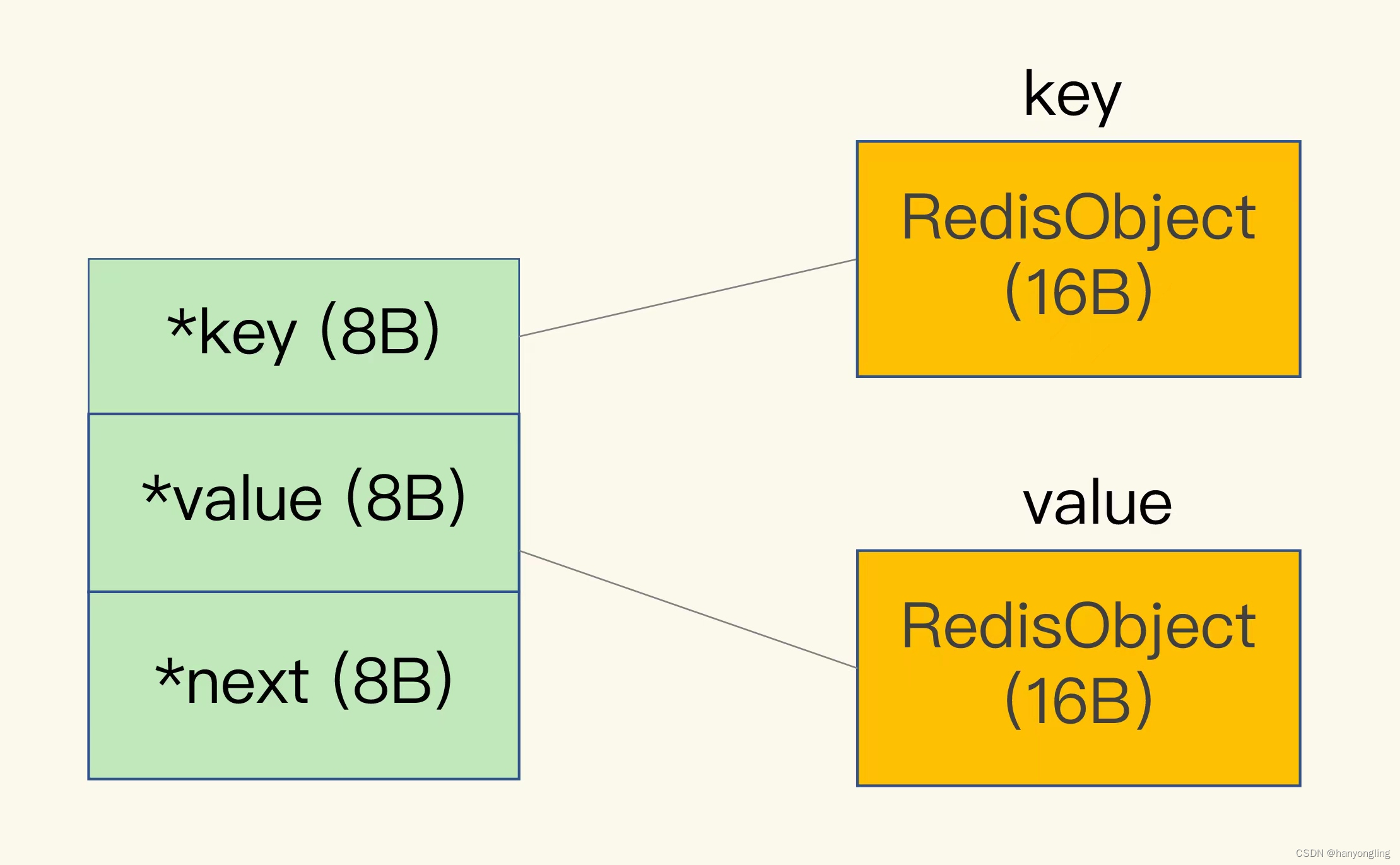
好了,这里就可以理解String类型保存Long的key,value为什么会占用64个字节了。
二、节省存储空间实践
如果存储Long的key,value,1亿个key,使用String类型,每个键值对会占用64个字节,一共需要6.4GG的内存,可以用另一种存储结构来实现存储,达到节省内存的目的。
Redis有一种底层数据结构压缩列表(ziplist)非常节省内存,用一系列连续的entry保存数据
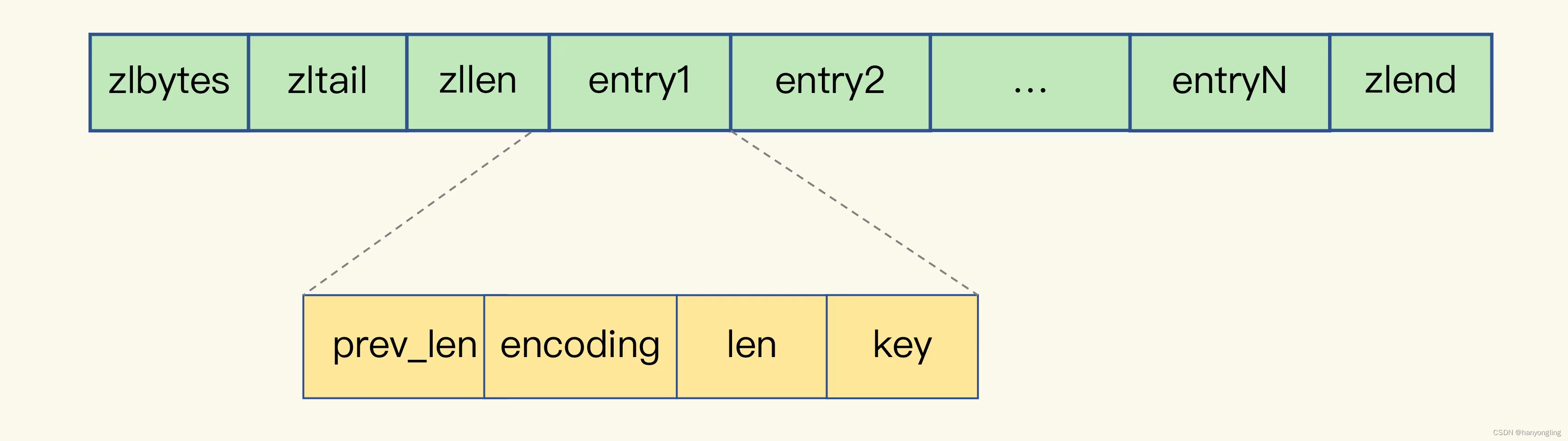
表头有三个字段:
zlbyge:列表长度
zltail:列表尾的偏移量
zllen:列表中的元素个数
表尾还有一个:zlend:表示列表结束
entry的元数据包括以下几个部分:
pre_len:表示一个entry的长度,1字节空间:前一个entry长度小于254(zlend占一个字节),否则为5字节空间占用
encoding:表示编码方式,1字节
len:表示自身长度,4字节
content:保存的实际内容
每一个entry保一个Long类型的value(8字节),每个entry的pre_len只需要1字节,这样一来,一共点用14字节(1+4+1+8),实际分配16字节。
Long类型的key做拆分:例:1111000001,前7位:1111000做为Hash类型的key,后3位:001 和 value分别做为Hash类型的key、value
hset 1111000 001 1234567890需要注意点:Hash底层类型有压缩表,哈希表,Redis的Hash类型设置了用压缩表保存数据的两个阀值:
hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中最大元素个数,这里设置为1000
hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度
如果超过这两个阀值,则Redis就会自动把Hash类型的实现结构从压缩表转换为哈希表,在节省内存方面哈希表就没有那么高效了。