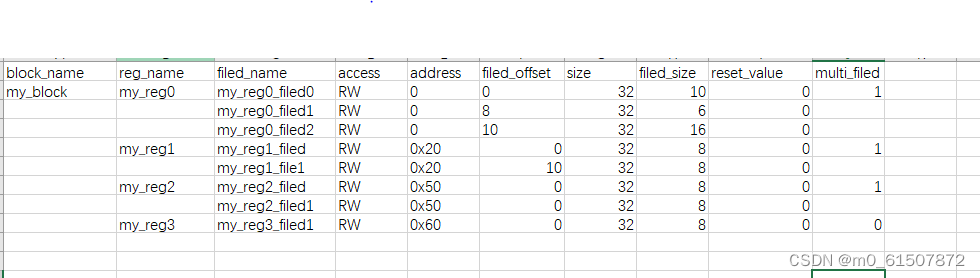
register model 在uvm的验证环境里是必不可缺少的一部分,涉及到对dut的寄存器的操作都需要通过register model。register model不同与uvm 其它component,它比较独立。register model里涉及到了一些概念,uvm_filed,uvm_reg,uvm_block。这三者具有层层包含的关系,最终生成一个完整的register_model。如果同过手动的方式去写register_model,对于变动比较的小register_model简单改下就行,但是对于变化比较大的register model就会花费大量时间,考虑到register model的生成是具有一定规律的,因此可以考虑通过python去生成,通过制定一些规则给DE,让DE按规填写excel 表格,然后DV可以根据表格可以生成需要的registermodel
from openpyxl import load_workbook
import sys
import numpy as np
import functools
def reg(reg):#例化reg 内部的filed,filed需要指定各个parameter
reg_name=reg['reg_name']
filed_name=reg['filed_name']
size=reg['size']
filed_size=reg['filed_size']
filed_offset=reg['filed_offset']
reset_value=reg['reset_value']
access=reg['access']
address=reg['address']
print("class "+str( reg_name )+" extend uvm_reg:")
print('\trand uvm_reg_filed '+str(filed_name)+";")
for reg_filed in reg_model:
if reg_filed['reg_name']==None:#判断是否具有多filed
if(reg_filed['address']==address):#用excel里的addr判断是否属于同一个寄存器的filed
filed1_name=reg_filed['filed_name']
print('\trand uvm_reg_filed '+str(filed1_name)+";")#filed
print('\tvirtual function void build();')#build 函数用来配置filed,同时进行例化
print('\t\t'+str(filed_name)+'=uvm_reg_filed::type_id::create(\"'+str(filed_name)+'\");')
for reg_filed in reg_model:
if reg_filed['reg_name']==None:#判断是否具有多个filed
if(reg_filed['address']==address):#判断是否属于同一个寄存器
filed1_name=reg_filed['filed_name']
print('\t\t'+str(filed1_name)+'=uvm_reg_filed::type_id::create(\"'+str(filed1_name)+'\");')
if reg['multi_filed']==0:
print('\t\t'+str(filed_name)+'.configure(this,'+str(filed_size)+','+str(filed_offset)+',\"'+str(access)+'\");')#str使用的时候必须是放在字符串中间
print('\tendfunction')
print('\tfunction new(input string name='"unamed "+str(reg_name)+" ")#加空格
print('\t\tspuper.new(name,'+str(size)+',UVM_NO_COVERAGE);')
print('\tendfunction')
print("endclass\n")
def block(block):#block的例化
block_name=block['block_name']
print('class '+str(block_name)+' extends uvm_reg_block;')
for reg in reg_model:#遍历block内部的 reg,
if(reg['reg_name']):
print('\trand '+str(reg['reg_name'])+' '+str(reg['reg_name'])+'_inst;')
print('\tfunction void build();')
print('\t\tdefault_map=create_map(\"default_map\",0,4,UVM_LITTLE_ENDIAN)')
for reg in reg_model:
if reg['reg_name']:
print('\t\t'+str(reg['reg_name'])+'_inst='+str(reg['reg_name'])+'::type_id:create(\"'+str(reg['reg_name'])+'_inst", ,get_full_name());')
print('\t\t'+str(reg['reg_name'])+'_inst.configure(this,null,\"'+str(reg['reg_name'])+'_inst\");')
print('\t\t'+str(reg['reg_name'])+'_inst.build();')
print('\t\tdefault_map.add_reg('+str(reg['reg_name'])+'_inst,'+str(reg['address'])+',\"'+str(reg['access'])+');\n')
print('\tendfunction\n')
print('\t`uvm_object_utils('+str(block_name)+')')
print('\tfunction new(input string name="unamed_'+str(block_name)+'\");')
print('\t\tsuper.new(name,UVM_NO_COVERAGE);')
print('\tendfunction')
print('endclass\n')
#def search:
if __name__=="__main__":
book = load_workbook(r'C:\Users\chenzhongping\Desktop\reg_model.xlsx')#需要加r'否则报错
sheet=book.active
#获得所有行
rows=sheet.rows
#print(rows)
row_count =sheet.max_row
columns=sheet.columns
#获得第一行所有数据
headers=[cell.value for cell in next(rows)]
print(headers)
reg_model = []
template= []
result={}
for row in rows:
data = {}
for title,cell in zip(headers,row):#生成字典,获得excel里的所有数据
data[title] = cell.value
# reg(data)#生成reg
reg_model.append(data)
# reg_tmp={}#用来保存所有的reg生成新的字典
reg_data=[]
print('Hello world \n\n')
#字典去重
# for reg_val in reg_model:
# reg_tmp={}#需要在for循环里声明否则append的都是最后一个字典
# reg_tmp['reg_name']=reg_val['reg_name']
# reg_data.append(reg_tmp)
# reg_unique=functools.reduce(lambda x,y:y in x and x or x +[y],reg_data,[])
# print(reg_data)
#print(reg_unique)
for block_valid in reg_model:
if(block_valid['block_name']):#这个python目前只考虑单block
block(block_valid)#生成block
if(block_valid['reg_name']):
reg(block_valid)#如果for 循环有个变量reg,那么这里会报错 dict' object is not callable
else:
if block_valid['reg_name']:
reg(block_valid)版权声明:本文为m0_61507872原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。