一般做文本分类时,模型最后的输出都是准确率。但在实际应用中,知道准确率肯定是不够的,我们最希望得到一个表格,第一列是原始文本,第二列是分类结果。那么要怎么做呢。
这里麻烦的地方在于模型的输入是向量化后的文本,而且顺序都是打乱的,想要知道原始文本对应的分类结果就只能追溯回去。emmm,好像很难的样子。我在这里的做法是给原始文本添加一列id,让id充当这个中间桥梁,而不是词向量。具体如下。
下图即训练集的数据,其中id这一列已经加上了。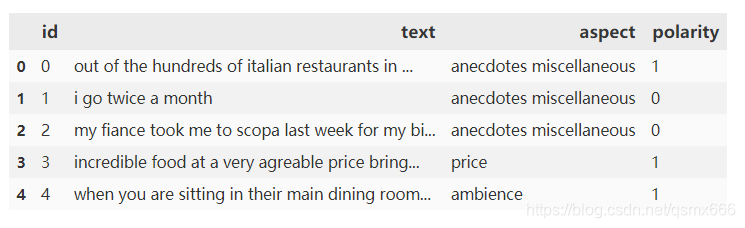
然后在数据处理部分做一些修改,这里用的是torchtext库。
tokenize = lambda x: x.split()
ID = data.Field(sequential=False, use_vocab=False)
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True)
ASPECT = data.Field(sequential=True,
tokenize=tokenize,
lower=True,
fix_length=2)
LABEL = data.Field(sequential=False, use_vocab=False)
train, val = data.TabularDataset.splits(path='data/',
skip_header=True,
train='train.tsv',
validation='test.tsv',
format='tsv',
fields=[('id', ID), ('text', TEXT),
('aspect', ASPECT),
('polarity', LABEL)]
cache = 'data/.vector_cache'
if not os.path.exists(cache):
os.mkdir(cache)
vectors = Vectors(name='data/glove.6B/glove.6B.300d.txt')
ID.build_vocab(train, val)
TEXT.build_vocab(train, val, vectors=vectors)
ASPECT.build_vocab(train, val, vectors=vectors)
LABEL.build_vocab(train, val)
主要是加上对id列的处理。注意这里的field最好大写,不要和表格列名重复,不然可能出现莫名其妙的错误。
模型部分不用动,我们直接跳到训练部分。代码如下。
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
with torch.no_grad():
for batch_idx, batch in enumerate(data_iter):
textid, X1, X2, y = batch.id, batch.text, batch.aspect, batch.polarity
X1 = X1.permute(1, 0)
X2 = X2.permute(1, 0)
y.data.add_(1) #下标从0开始
y_hat = net(X1, X2)
predict = y_hat.argmax(dim=1)
data = {'id': textid, 'real': y, 'predict': predict}
result = pd.DataFrame(data)
result.to_csv('data/reslut.tsv', sep='\t',index=0)
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (y_hat.argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else:
if ('is_training'
in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X1, X2, is_training=False).argmax(
dim=1) == y).float().sum().item()
else:
acc_sum += (net(
X1, X2).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, num_epochs):
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for batch_idx, batch in enumerate(train_iter):
# batch.text (seq_len,batch_size) batch.aspect (2,batch_size)
X1, X2, y = batch.text, batch.aspect, batch.polarity
X1 = X1.permute(1, 0)
X2 = X2.permute(1, 0)
y.data.add_(1) #下标从0开始 0 1 2
y_hat = net(X1, X2)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print(
'epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n,
test_acc, time.time() - start))
我们把改动的部分单独拎出来看一下。
textid, X1, X2, y = batch.id, batch.text, batch.aspect, batch.polarity
y_hat = net(X1, X2)
predict = y_hat.argmax(dim=1)
data = {'id': textid, 'real': y, 'predict': predict}
result = pd.DataFrame(data)
result.to_csv('data/reslut.tsv', sep='\t',index=0)
其实很简单,这里直接将textid、实际值y和预测值predict生成一个dataframe保存了。
需要注意的是我们需要的是测试集的数据。并且每一个epoch都会产生新的数据,采用保存到文件的方式可以让新数据覆盖旧数据。
读取reslut.tsv,并按id从小到大排序。
现在打开测试集原始数据。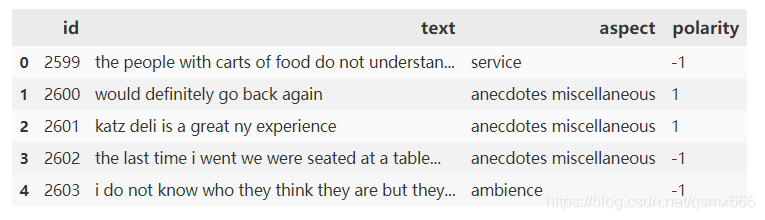
可以看到两张表id部分是对应相同的,无需匹配,直接拼成一张表即可。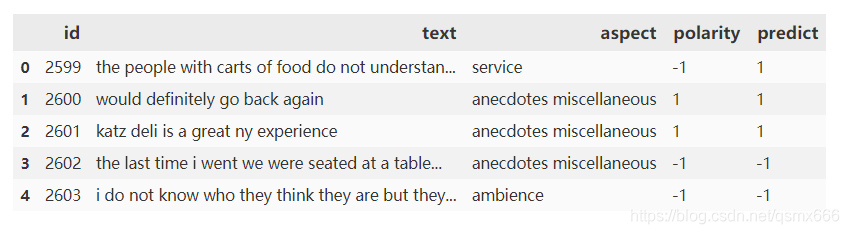
完成。
版权声明:本文为qsmx666原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。