Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
先从PageRank讲起。
PageRank
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:
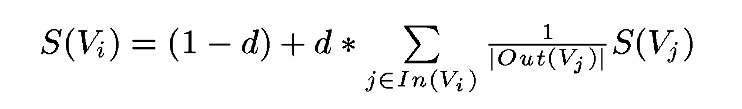
S(Vi)是网页i的中重要性(PR值)。d是阻尼系数,一般设置为0.85。In(Vi)是存在指向网页i的链接的网页集合。Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
举个例子:
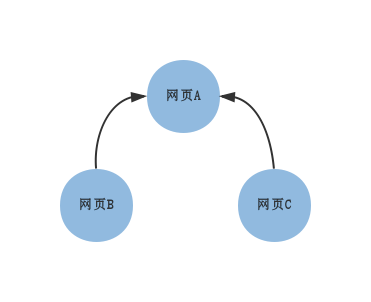
上图表示了三张网页之间的链接关系,直觉上网页A最重要。可以得到下面的表:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
横栏代表其实的节点,纵栏代表结束的节点。若两个节点间有链接关系,对应的值为1。
根据公式,需要将每一竖栏归一化(每个元素/元素之和),归一化的结果是:
| 结束\起始 | A | B | C |
| A | 0 | 1 | 1 |
| B | 0 | 0 | 0 |
| C | 0 | 0 | 0 |
上面的结果构成矩阵M。我们用matlab迭代100次看看最后每个网页的重要性:
1 2 3 4 5 6 7 8 9 10 11 | M = [0 1 1 0 0 0 0 0 0];PR = [1; 1 ; 1];for iter = 1:100 PR = 0.15 + 0.85*M*PR; disp(iter); disp(PR);end |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | ...... 95 0.4050 0.1500 0.1500 96 0.4050 0.1500 0.1500 97 0.4050 0.1500 0.1500 98 0.4050 0.1500 0.1500 99 0.4050 0.1500 0.1500 100 0.4050 0.1500 0.1500 |
如果把上面的有向边看作无向的(其实就是双向的),那么:
1 2 3 4 5 6 7 8 9 10 11 | M = [0 1 1 0.5 0 0 0.5 0 0];PR = [1; 1 ; 1];for iter = 1:100 PR = 0.15 + 0.85*M*PR; disp(iter); disp(PR);end |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ..... 98 1.4595 0.7703 0.7703 99 1.4595 0.7703 0.7703 100 1.4595 0.7703 0.7703 |
使用TextRank提取关键字
将原文本拆分为句子,在每个句子中过滤掉停用词(可选),并只保留指定词性的单词(可选)。由此可以得到句子的集合和单词的集合。
每个单词作为pagerank中的一个节点。设定窗口大小为k,假设一个句子依次由下面的单词组成:
w1, w2, w3, w4, w5, ..., wn
w1, w2, ..., wk、w2, w3, ...,wk+1、w3, w4, ...,wk+2等都是一个窗口。在一个窗口中的任两个单词对应的节点之间存在一个无向无权的边。
基于上面构成图,可以计算出每个单词节点的重要性。最重要的若干单词可以作为关键词。
使用TextRank提取关键短语
参照“使用TextRank提取关键词”提取出若干关键词。若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
例如,在一篇介绍“支持向量机”的文章中,可以找到三个关键词支持、向量、机,通过关键短语提取,可以得到支持向量机。
使用TextRank提取摘要
将每个句子看成图中的一个节点,若两个句子之间有相似性,认为对应的两个节点之间有一个无向有权边,权值是相似度。
通过pagerank算法计算得到的重要性最高的若干句子可以当作摘要。
论文中使用下面的公式计算两个句子Si和Sj的相似度:

分子是在两个句子中都出现的单词的数量。|Si|是句子i的单词数。
由于是有权图,PageRank公式略做修改:

实现TextRank
因为要用测试多种情况,所以自己实现了一个基于Python 2.7的TextRank针对中文文本的库TextRank4ZH。位于:
https://github.com/someus/TextRank4ZH
下面是一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | #-*- encoding:utf-8 -*-import codecsfrom textrank4zh import TextRank4Keyword, TextRank4Sentencetext = codecs. open ( './text/01.txt' , 'r' , 'utf-8' ).read()tr4w = TextRank4Keyword(stop_words_file = './stopword.data' ) # 导入停止词#使用词性过滤,文本小写,窗口为2tr4w.train(text = text, speech_tag_filter = True , lower = True , window = 2 ) print '关键词:'# 20个关键词且每个的长度最小为1print '/' .join(tr4w.get_keywords( 20 , word_min_len = 1 )) print '关键短语:'# 20个关键词去构造短语,短语在原文本中出现次数最少为2print '/' .join(tr4w.get_keyphrases(keywords_num = 20 , min_occur_num = 2 )) tr4s = TextRank4Sentence(stop_words_file = './stopword.data' )# 使用词性过滤,文本小写,使用words_all_filters生成句子之间的相似性tr4s.train(text = text, speech_tag_filter = True , lower = True , source = 'all_filters' )print '摘要:'print '\n' .join(tr4s.get_key_sentences(num = 3 )) # 重要性最高的三个句子 |
1 2 3 4 5 6 7 8 | 关键词:媒体/高圆圆/微/宾客/赵又廷/答谢/谢娜/现身/记者/新人/北京/博/展示/捧场/礼物/张杰/当晚/戴/酒店/外套关键短语:微博摘要:中新网北京12月1日电(记者 张曦) 30日晚,高圆圆和赵又廷在京举行答谢宴,诸多明星现身捧场,其中包括张杰(微博)、谢娜(微博)夫妇、何炅(微博)、蔡康永(微博)、徐克、张凯丽、黄轩(微博)等高圆圆身穿粉色外套,看到大批记者在场露出娇羞神色,赵又廷则戴着鸭舌帽,十分淡定,两人快步走进电梯,未接受媒体采访记者了解到,出席高圆圆、赵又廷答谢宴的宾客近百人,其中不少都是女方的高中同学 |