最近自学transformer阅读经典论文《Attention Is All You Need》时对其中的符号表示以及具体计算过程有点小疑惑,多方查阅后整理出本文作为笔记以供参考,若有错误敬请斧正。
论文中的公式:
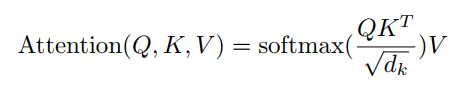

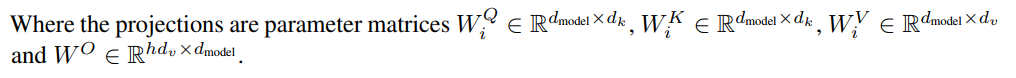
K,Q,V的含义
K: Key;
Q: Query;
V: Value;
基本原理:给定一个 query,计算query 与 key 的相关性,然后根据query 与 key 的相关性去找到最合适的 value。
Self-Attention
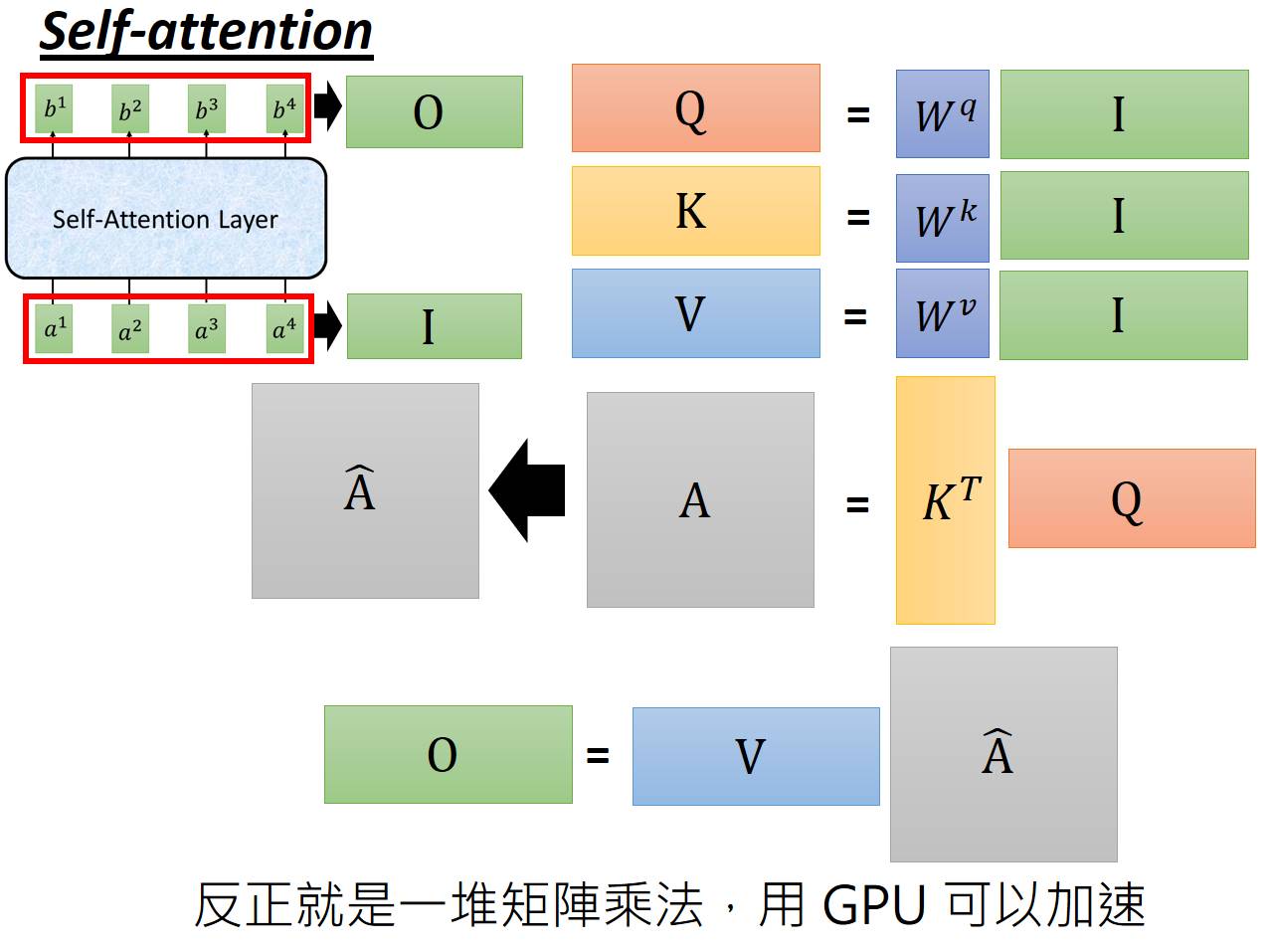
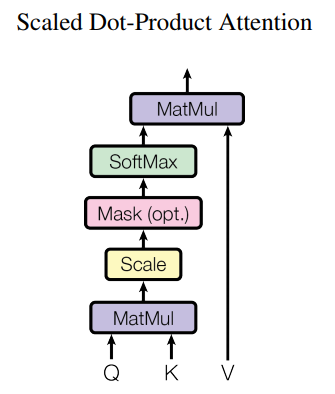
设输入张量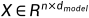 (其中n为样本个数,d为模型维度数量,注意在X,Q,K,V等矩阵中,一行表示一个样本,每一列表示样本的每一个维度)
(其中n为样本个数,d为模型维度数量,注意在X,Q,K,V等矩阵中,一行表示一个样本,每一列表示样本的每一个维度)
则在Attention(Q, K, V) 中,K,Q,R为输入张量X通过Linear mapping变换到Q,K,V的特征空间中的张量,即:
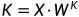 ,
,
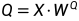 ,
,
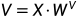 .
.
(Linear层权重W初始化后由梯度下降自动更新)
以下为单头self-attention的简单实现(具体实现见https://blog.csdn.net/beilizhang/article/details/115282604)
import torch
n = 3
d_model = 4
d_k = 3
d_v = 3
torch.manual_seed(1)#设定随机数种子
x = torch.rand(n,d_model)
print(x)#查看输入张量(每行为一个样本,每列为一个维度)
Wq = torch.rand(d_model,d_k)#随机初始化权重
torch.manual_seed(2)
Wk = torch.rand(d_model,d_k)
torch.manual_seed(3)
Wv = torch.rand(d_model,d_v)
K = x @ Wk # @为矩阵乘法,相当于torch.mm
Q = x @ Wq
V = x @ Wv
Attention = torch.nn.functional.softmax((Q @ K.T)/d_k**0.5, -1) @ V
#Attention 每一维输出,相当于是所有输入序列样本对应维度的加权和未来目标:理解mutihead attention并手动复现。
相关参考:
李宏毅nlp课程
版权声明:本文为ziro_原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。