前言
在微服务架构下,⼀次请求少则经过三四次服务调⽤完成,多则跨越几十
个甚至是上百个服务节点,如何动态展示服务的调用链路?如何分析服务调⽤链路中的瓶颈节点并对其进行调优?如何快速进行服务链路的故障发现?这就是分布式链路追踪技术存在的目的和意义。
一、分布式链路追踪核心思想
本质:记录日志。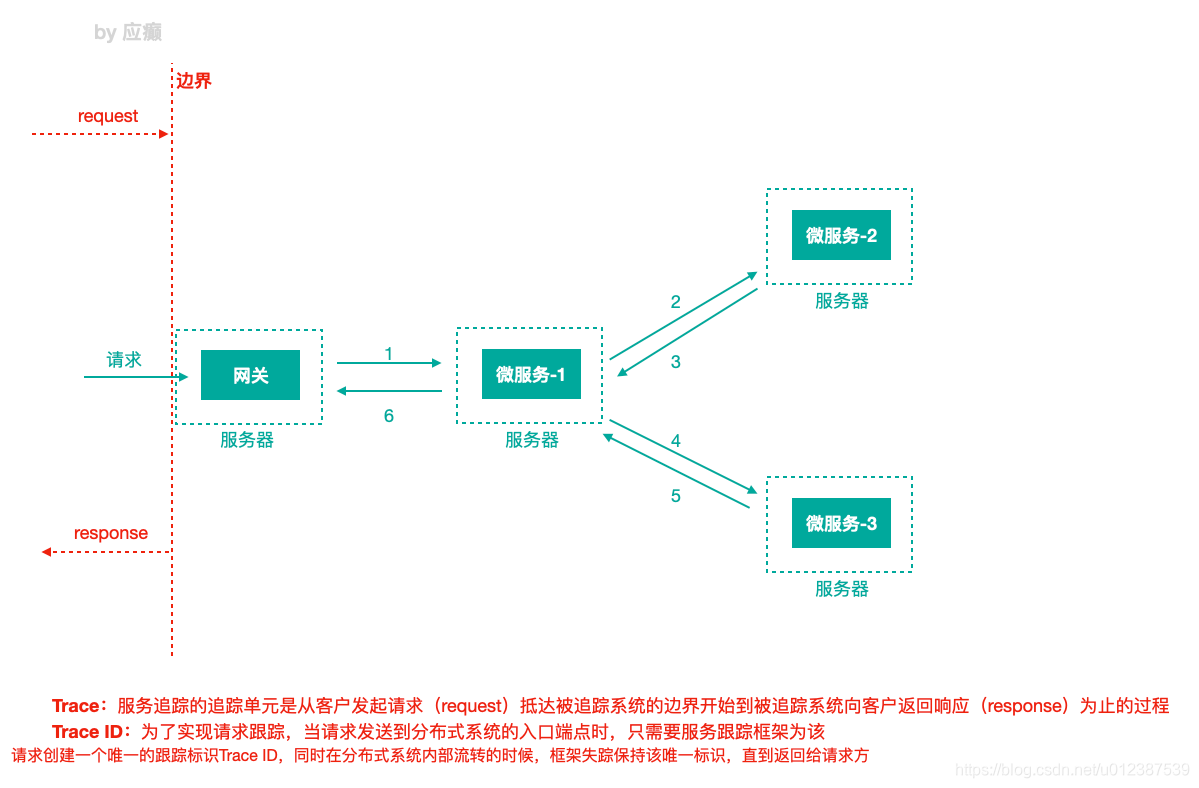
Trace:服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为⽌的过程。
Trace ID:为了实现请求跟踪,当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建⼀个唯⼀的跟踪标识Trace ID,同时在分布式系统内部流转的时候,框架失踪保持该唯⼀标识,直到返回给请求方。
⼀个Trace由⼀个或者多个Span组成,每⼀个Span都有⼀个SpanId,Span中会记录TraceId,同时还有⼀个叫做ParentId,指向了另外⼀个Span的SpanId,表明父子关系,其实本质表达了依赖关系。
Span ID:为了统计各处理单元的时间延迟,当请求到达各个服务组件时,也是通过⼀个唯⼀标识Span ID来标记它的开始,具体过程以及结束。对每⼀个Span来说,它必须有开始和结束两个节点,通过记录开始Span和结束Span的时间戳,就能统计出该Span的时间延迟,除了时间戳记录之外,它还可以包含⼀些其他元数据,比如时间名称、请求信息等。
每⼀个Span都会有⼀个唯⼀跟踪标识 Span ID,若⼲个有序的 span 就组成了⼀个trace。
Span可以认为是⼀个日志数据结构,在⼀些特殊的时机点会记录了⼀些日志信息,比如有时间戳、spanId、TraceId,parentIde等,Span中也抽象出了另外⼀个概念,叫做事件,核心事件如下:
- CS :client send/start 客户端/消费者发出⼀个请求,描述的是⼀个span开始
- SR: server received/start 服务端/生产者接收请求 SR-CS属于请求发送的⽹络延迟
- SS: server send/finish 服务端/生产者发送应答 SS-SR属于服务端消耗时间
- CR:client received/finished 客户端/消费者接收应答 CR-SS表示回复需要的时间(响应的⽹络延迟)
二、Sleuth + Zipkin
1.介绍
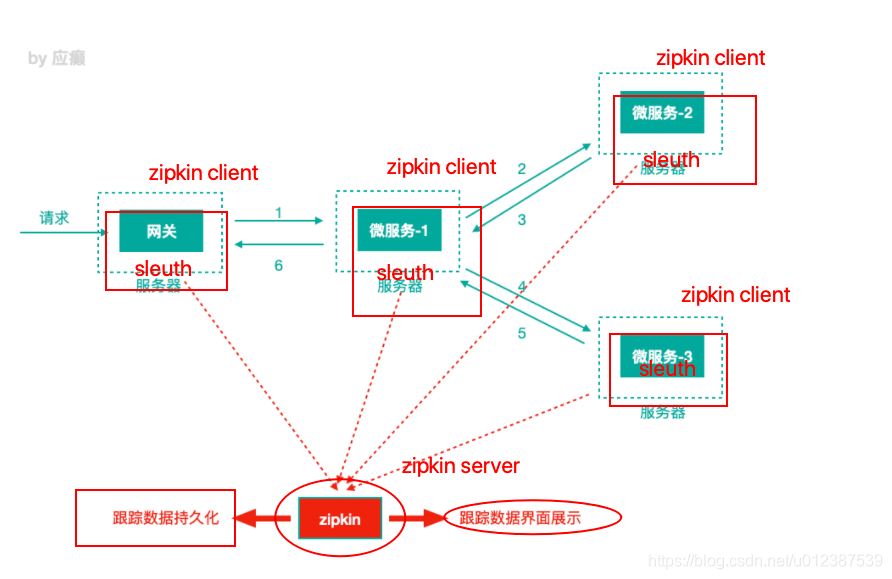
Sleuth可以记录⼀个服务请求经过哪些服务、服务处理时⻓等。
Zipkin通过聚合各个微服务下的Sleuth记录的日志信息进行展示。
2.使用
Sleuth需要在每个微服务添加
- pom依赖
<!--链路追踪-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
- application.yml配置⽂件
#分布式链路追踪
logging:
level:
org.springframework.web.servlet.DispatcherServlet: debug
org.springframework.cloud.sleuth: debug
Zipkin 包括Zipkin Server和 Zipkin Client两部分,Zipkin Server是⼀个单独的服务,Zipkin Client就是具体的微服务。
- Zipkin Server构建
- pom依赖:
<!--zipkin-server的依赖坐标-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.12.3</version>
<exclusions>
<!--排除掉log4j2的传递依赖,避免和springboot依赖的⽇志组件冲突-->
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starterlog4j2</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--zipkin-server ui界⾯依赖坐标-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.12.3</version>
</dependency>
SpringBoot启动类添加@EnableZipkinServer注解。
application.yml配置⽂件
management:
metrics:
web:
server:
auto-time-requests: false # 关闭⾃动检测请求
- Zipkin Client 构建
- pom依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
- application.yml配置
spring:
zipkin:
base-url: http://127.0.0.1:9411 # zipkin server的请求地址
sender:
# web 客户端将踪迹⽇志数据通过⽹络请求的⽅式传送到服务端,另外还有配置
# kafka/rabbit 客户端将踪迹⽇志数据传递到mq进⾏中转
type: web
sleuth:
sampler:
# 采样率 1 代表100%全部采集 ,默认0.1 代表10% 的请求踪迹数据会被采集
# ⽣产环境下,请求量⾮常⼤,没有必要所有请求的踪迹数据都采集分析,对于⽹络包括server端压⼒都是⽐较⼤的,可以配置采样率采集⼀定⽐例的请求的踪迹数据进⾏分析即可
probability: 1