我们在迁移Oracle到PostgreSQL的过程中,遇到了一些不小的挑战。使用Ora2PG工具迁移数据遇到的小问题比较多,同时在迁移LOB字段的时候,性能表现不够理想,于是我们采用了DataX来做数据迁移。
[ DataX3.0概览 ]先介绍一下DataX,DataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台。特点是实现了众多异构数据源之间高效的数据同步功能。
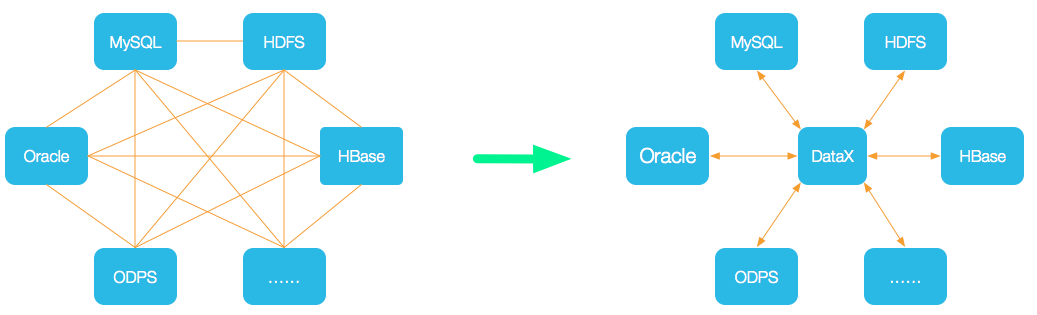
我们当前使用ogg软件来实现异构数据源同步的问题,从左图可见其链路及其复杂,这给后续运维工作带来了很多不可控因素,一旦数据库多起来,对维护人员来说不仅仅是工作量的增加,错综复杂的逻辑关系都是潜在的天坑。
而DataX则采用了星型数据链路来实现,运维人员只要管理中间的DataX服务器即可完成。当需要新增加一个数据源时,只需要接进来就可以完成数据同步工作。
当然缺点也显而易见,一旦宕机,将会影响其上所有同步的数据源。同时性能上也受制于DataX主机网卡的性能。一旦该网卡流量打满,则会导致同步速度达到天花板。
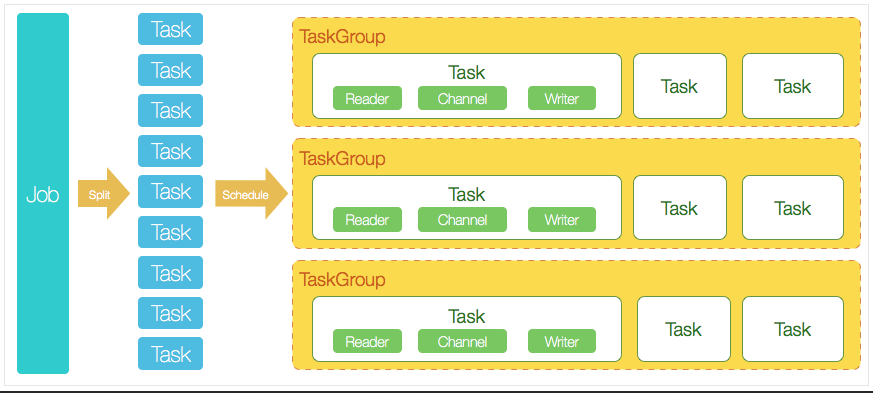
[ DataX架构 ]DataX作为离线数据同步框架,采用Framework+ plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

如图所示:
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
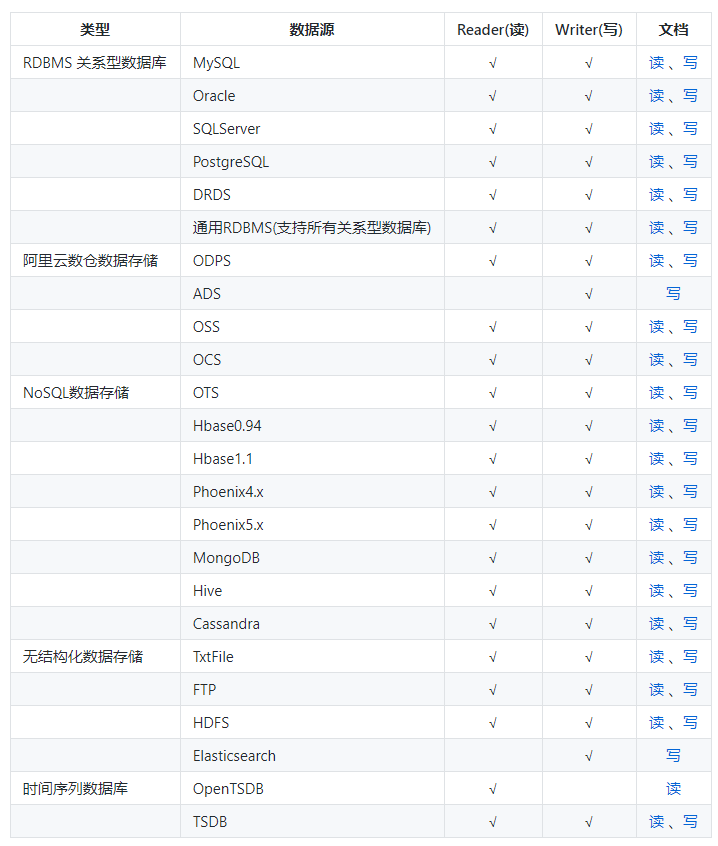
当前DataX支持的Reader插件和Writer非常多,从官网上可以看到,主流的关系型数据库都支持。
了解了基本概念和架构之后,来看看如何使用。先看看我们的表。这是一张Oracle中的表,包含BLOB字段。表上没有主键,也没有索引。
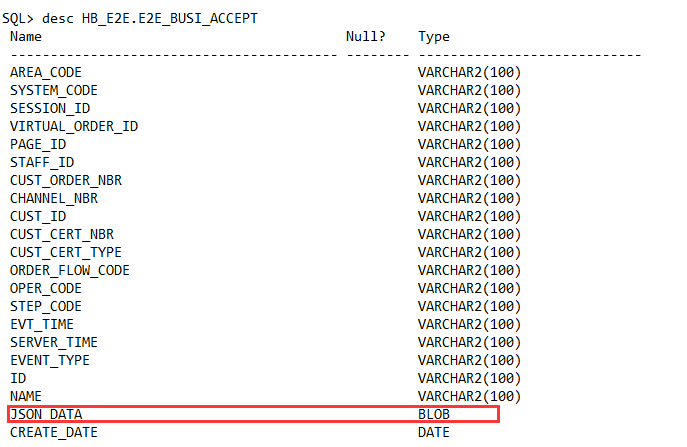
表的大小接近75G。

我们先看下Ora2PG迁移这张表的速度
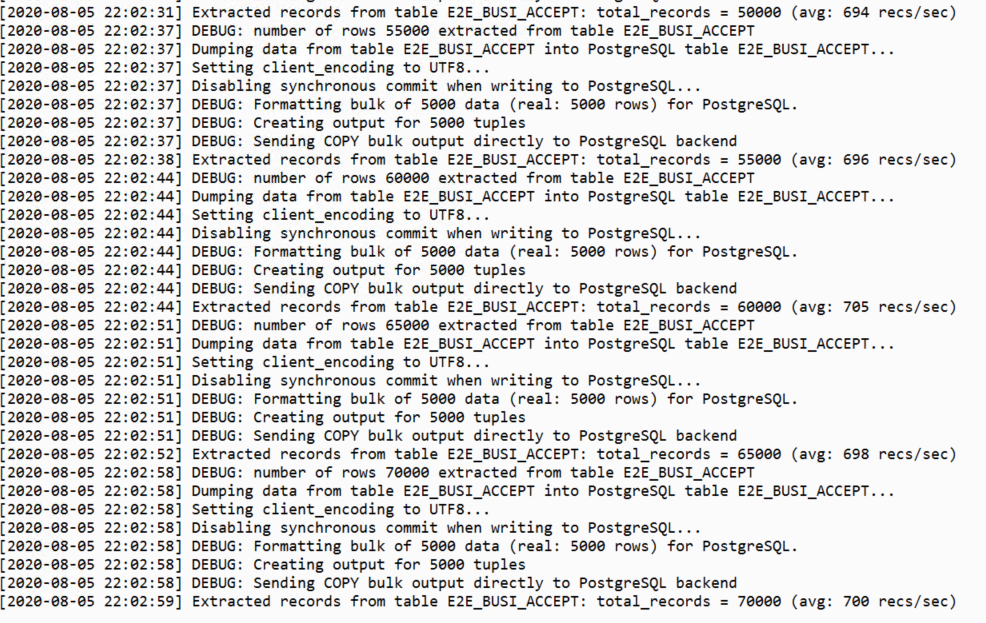
可以看到速度非常慢,只能达到700行/秒,这张表的数据量大概是6000多万。而在迁移其他小表或者字段没有LOB的表的时候,性能最高是可以达到20万行/秒。
而且该Ora2PG配置参数也是经过优化,设置了以下参数:
-P| --parallel num: Number of parallel tables to extract at the sametime.
-j| --jobs num : Number of parallel process to send data to PostgreSQL.
-J| --copies num : Number of parallel connections to extract data fromOracle.
BLOB_LIMIT 5000
由此可见,使用Ora2PG迁移带有LOB的大表,速度不理想。
测试DataX。DataX软件安装非常简单,直接下载软件包,解压到指定的目录,建议是速度快的硬盘上。
然后到datax/bin目录下,先要配置一个json文件。
具体可以参考官方给出的示例:
Oracle读取
https://github.com/alibaba/DataX/blob/master/oraclereader/doc/oraclereader.md
PostgreSQL写入
https://github.com/alibaba/DataX/blob/master/postgresqlwriter/doc/postgresqlwriter.md
按照官方文档配置的JSON文件如下:
{
"job":{
"setting":{
"speed":{
"channel":32
}
},
"content":[
{
"reader":{
"name":"oraclereader",
"parameter":{
"username":"********* ",
"password":"********",
"column":[
"area_code",
"system_code",
"session_id",
"virtual_order_id",
"page_id",
"staff_id",
"cust_order_nbr",
"channel_nbr",
"cust_id",
"cust_cert_nbr",
"cust_cert_type",
"order_flow_code",
"oper_code",
"step_code",
"evt_time",
"server_time",
"event_type",
"id",
"name",
"json_data",
"create_date"
],
"splitPk":" PAGE_ID",
"connection":[
{
"table":[
"hb_e2e.E2E_BUSI_ACCEPT"
],
"jdbcUrl":[
"jdbc:oracle:thin:@133.0.xxx.xxx:1521/hbe2e"
]
}
]
}
},
"writer":{
"name":"postgresqlwriter",
"parameter":{
"username":"********",
"password":"********",
"column":[
"area_code",
"system_code",
"session_id",
"virtual_order_id",
"page_id",
"staff_id",
"cust_order_nbr",
"channel_nbr",
"cust_id",
"cust_cert_nbr",
"cust_cert_type",
"order_flow_code",
"oper_code",
"step_code",
"evt_time",
"server_time",
"event_type",
"id",
"name",
"json_data",
"create_date"
],
"preSql":[
"truncatetable hb_e2e.E2E_BUSI_ACCEPT"
],
"connection":[
{
"jdbcUrl":"jdbc:postgresql://133.0.xxx.xxx:5432/hbe2e",
"table":[
"hb_e2e.E2E_BUSI_ACCEPT"
]
}
],
"batchSize":512
}
}
}
]
}
}
向上滑动查看更多内容配置好后,就可以使用python脚本调用起来了。
nohuppython datax.py a1.json > a1.log &
然后我们可以通过日志来观察。执行速度。还有是否出错。
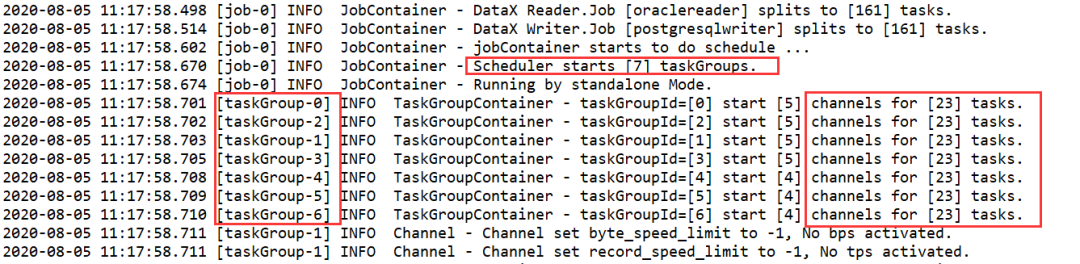
可以看到,我的Channel配置为32,且使用了"splitPk":"id"。它在后台自动开了7个任务组。
JobContainer- Scheduler starts [7] taskGroups.
7个TaskGroup,每个下面又包含了23个task任务。
[taskGroup-0]INFO TaskGroupContainer - taskGroupId=[0] start [5] channels for[23] tasks.
[taskGroup-2]INFO TaskGroupContainer - taskGroupId=[2] start [5] channels for[23] tasks.
[taskGroup-1]INFO TaskGroupContainer - taskGroupId=[1] start [5] channels for[23] tasks.
[taskGroup-3]INFO TaskGroupContainer - taskGroupId=[3] start [5] channels for[23] tasks
[taskGroup-4]INFO TaskGroupContainer - taskGroupId=[4] start [4] channels for[23] tasks
[taskGroup-5]INFO TaskGroupContainer - taskGroupId=[5] start [4] channels for[23] tasks
[taskGroup-6]INFO TaskGroupContainer - taskGroupId=[6] start [4] channels for[23] tasks
我们仔细观察,可以发现每个TaskGroup开启了channel数量不太一样,有的开启了5个,有的开启了4个,但是他们的任务都是23个。所以总共是161个任务。
那么这161个任务他们是怎么样取数的呢?通过日志我们可以发现,它在做任务之前,执行了下面的SQL,对数据进行了分片。
SingleTableSplitUtil- split pk [sql=SELECT * FROM ( SELECT PAGE_ID FROMhb_e2e.E2E_BUSI_ACCEPT SAMPLE (0.1) WHERE (PAGE_ID IS NOT NULL) ORDER BY DBMS_RANDOM.VALUE) WHERE ROWNUM <= 160 ORDER by PAGE_IDASC] is running
我们把这个SQL拿到Oracle中执行,发现数据查出来是160个Page_ID的值。
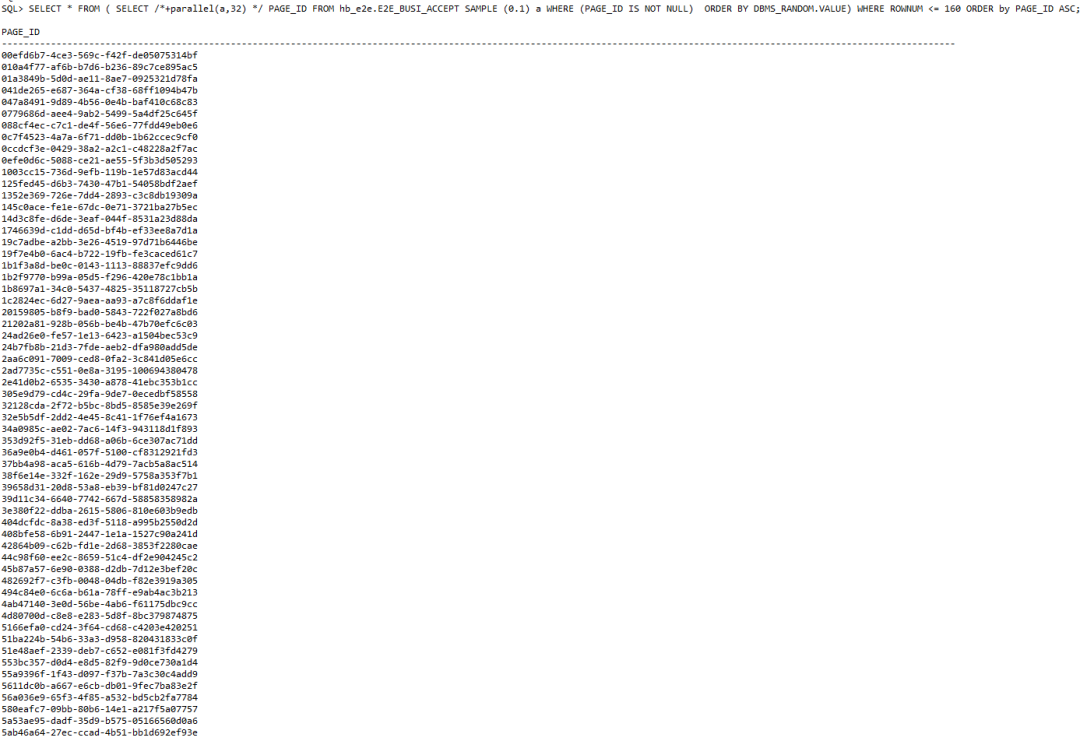
再继续看程序日志,你会发现每个任务对应的SQL语句如下。
[taskGroup-1]INFO TaskGroupContainer - taskGroup[1] taskId[155] attemptCount[1]is started
INFO CommonRdbmsReader$Task - Begin to read record by Sql: [selectarea_code,system_code,session_id,virtual_order_id,page_id,staff_id,cust_order_nbr,channel_nbr,cust_id,cust_cert_nbr,cust_cert_type,order_flow_code,oper_code,step_code,evt_time,server_time,event_type,id,name,json_data,create_datefrom hb_e2e.E2E_BUSI_ACCEPT where ('f3f9ec73-4e88-2f7d-ab51-cfde34852856' <= PAGE_ID AND PAGE_ID

每一片数据都是这个where条件。
'f3f9ec73-4e88-2f7d-ab51-cfde34852856'<= PAGE_ID AND PAGE_ID < 'f4c81a28-7088-91a2-fe91-305ec26d6624'
至此数据被分成了160份,然后160个任务有条不紊的并行运行,所以速度自然会提上来。
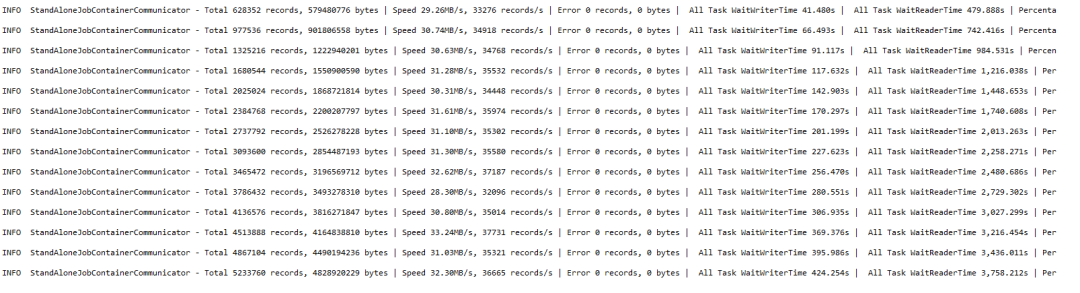
我们可以看到每秒大概能每秒能复制35000行记录。大概复制的速度是30.64多MB/S。
当整个任务完成之后,会显示速度,读出的记录数,失败的记录数。
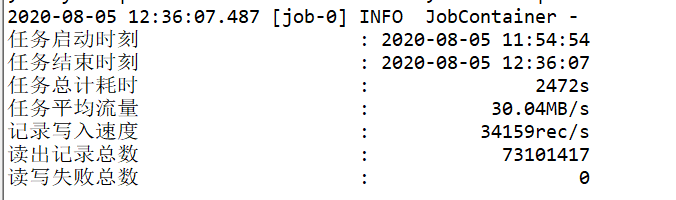
最后不得不吐槽一句,虽然DataX工具好用,速度也很快,但是每一个表都需要配置一个json文件,配置工作比较繁琐。所以需要自行开发脚本来批量生成json文件,目前我们在开发类似的脚本。