- DAPs:Deep Action Proposals for Action Understanding

提出的目的:加快action proposal的速度,同时提高准确率
与之前方法的比较:由于action segments的长度不同,在之前的方法中需要设置不同的滑动窗口在多次扫描整个视频,在使用极大似然的方法找到最合适的segment,这种方法运行速度很慢。而DAPs只使用了一个滑窗就可以得到不同尺度的proposal,只对视频处理一遍。
方法:对于输入的整个视频先使用C3D网络来提取视频特征,在输入到LSTM网络来把这些特征串联起来,隐藏层h作为这个时间的特征,在使用滑动窗口来扫描整个特征序列,得到预测的action segment并且对每个segment打分。使用anchor机制,anchor的尺度使用K-means聚类来对实际的action segments处理,得到k种尺度的anchor,在得到不同尺度的segment。
缺点:生成的提议通常在时间边界上不够精确和灵活,无法覆盖不同持续时间的实际行动实例
2.SST: Single-Stream Temporal Action Proposals

提出的目的:在要求高的准确率和速度的基础上,加上了在尽量少的proposal上得到更准确的action segments。
与DAPs方法的比较:DAPs虽然可以使用一个滑动窗口得到不同尺度的segment,但是对每帧进行多次处理,找到最合适的尺度。SST方法可以只对每帧进行一次处理。
方法:对于输入的整个视频先使用C3D网络来提取视频特征,在输入到GRU网络来把这些特征串联起来(GRU比LSTM有更少的参数,因此速度更快),在提取proposal的过程中,对每个时间节点t,以计算以t为终点对多个尺度的区间置信度c,在使用阈值和非极大值抑制的方法找到最终的proposal。
缺点:生成的提议通常在时间边界上不够精确和灵活,无法覆盖不同持续时间的实际行动实例
3.TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals
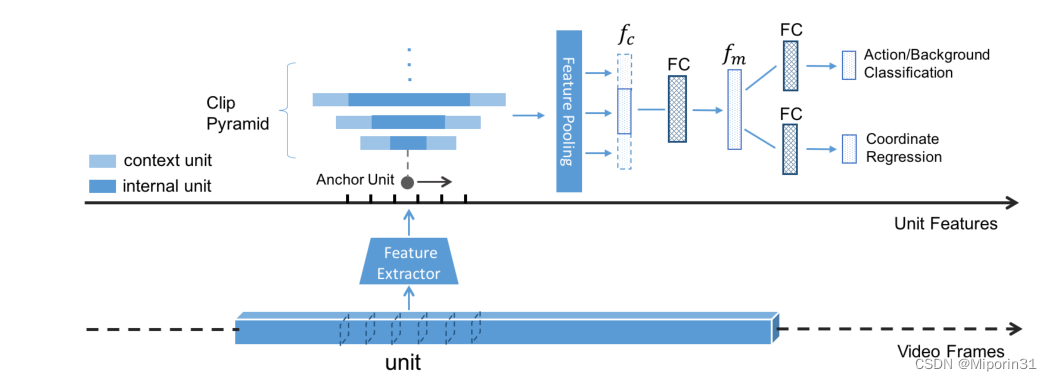
与之间方法的比较:通过时间坐标回归联合预测行为建议并细化时间边界;通过复用unit feature来实现快速计算。
方法:将输入的视频平均分为多个video units,将每一个unit送入visual encoder(C3D)中,提取unit-level的特征。以每一个unit为anchor unit,构造一个clip pyramid(剪辑金字塔)。每一个temporal window pyramid(深蓝色部分)由{1,2,4,…}个unit构成,然后在每个temporal window的前后加上一定数量的context unit(浅蓝色部分)构成clip。将每一个clip送入Feature Pooling,clip的最后一个特征fc是上下文特征和内部特征的串联。单元级时间坐标回归网络包含两个输出:第一个输出置信度评分判断clip中是否包含action,第二个输出时间坐标回归偏移量。
优点:TURN联合预测动作提议并通过时间坐标回归细化时间边界;单元特征重用实现了快速计算。
缺点:受到滑动窗口时间边界不精确的限制
4.CTAP: Complementary Temporal Action Proposal Generation
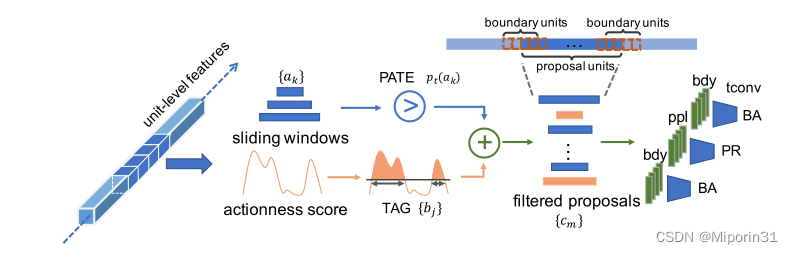
提出的目的:基于滑动窗口的方法均匀覆盖所有的视频片段,但时域边界不准确;基于动作性分数的方法边界更准确但当动作分数比较低的时候,也会漏掉一些提议。互补时间动作提议生成将动作分数与滑动窗口相结合,形成互补。
方法:初始proposal生成:输出actionness proposals和滑动窗口proposals;proposal互补滤波器:首先判断actionness方法是否可能漏掉某些proposal,并从滑动窗口proposals中收集过来,组成新的proposals;proposals排名与边界调整:设计了一个时域卷积调整与排序网络,时序排序信息。
优点:提出了互补时间行动建议生成器,利用行动建议和滑动窗口的互补特性生成高质量的提议。
缺点:只考虑了两种方法的互补性,而没有解决内在的困难
5.BSN: Boundary Sensitive Network for Temporal Action Proposal Generation
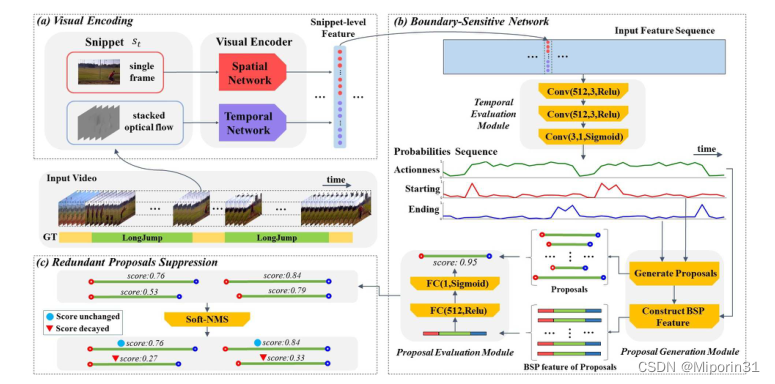
与之前方法的比较:采用“局部到全局”的方式。在局部,BSN首先定位高概率的时间边界,然后将这些边界直接组合为提议。在全局范围内,使用边界敏感提案功能,BSN通过评估提案是否包含其区域内的置信度来检索提案。
方法:视频特征编码:采用双流网络作为视觉编码器,包含两个分支-空间网络对单个RGB帧进行操作以捕获外观特征,时间网络对堆叠光流场进行操作以捕获运动信息。边界敏感网络:(1).temporal evaluation module:基于提取的视频特征序列,采用3层时序卷积层处理并评估每个时间位置的开始、结束和动作概率。(2).proposal generation module:生成具有高开始和结束概率的提议,并为每个提议构造边界敏感提议特征。(3).proposal evaluation module:使用BSP特征评估每个提案的置信度得分。
优点:BSN采用的“局部到全局”方式带来了更精确的边界和更好的检索质量;使用由提案内部和周围的行动评分组成的特征,BSN通过评估提案是否包含行动的置信度来检索提案,这些提议级特征提供了全局信息,以便更好地进行评估。
缺点:PEG模块对于候选proposal的特征构建和置信度评估是分开进行的,效率低;TEM模块对每个时刻采用局部上下文信息进行特征建模,proposal特征的构建缺少丰富的时序上下文信息;算法中包含多个处理步骤:视频特征提取、TEM、PGM、PEM等,是一个多阶段的算法模型,不是一个统一的网络模型。
6.Multi-granularity Generator for Temporal Action Proposal
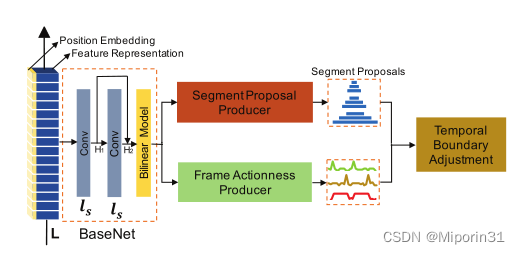
与之前方法的比较:提出了两个组件,段提议生成器和帧动作生成器被组合以在两个不同的粒度上执行时间动作提议的任务。SPP从一个粗略的角度生成分段提议,FAP对每个视频帧进行更精细的动作评估。
方法:首先,将不同波长的余弦和正弦函数实现的帧位置嵌入与视频帧特征相结合。组合的特征被馈送到MGG,以执行时间动作提议。具体而言,首先提出双线性匹配模型来利用视频序列丰富的局部信息。然后,将分段提议产生器和帧动作产生器耦合在一起,分别负责产生粗略的分段建议和评估精细的帧建议。SPP使用具有横向连接的U形架构来生成具有高召回率的不同时间跨度的候选提议。FAP密集的评估每一帧成为起点、终点和中间点的概率。利用时间边界调整模块,基于所计算的帧动作性来在时间上调整分段提议的边界,因此生成细化的精确动作提议。
优点:MGG可以同时生成分段建议和框架行动,这有助于在粗略和精细级别发现有关可能行动的信息;提出了一种双线性匹配模型,以利用视频序列中丰富的局部信息。
缺点:仅仅基于局部信息,而忽略了长期的上下文信息。
7.BMN: Boundary-Matching Network for Temporal Action Proposal Generation
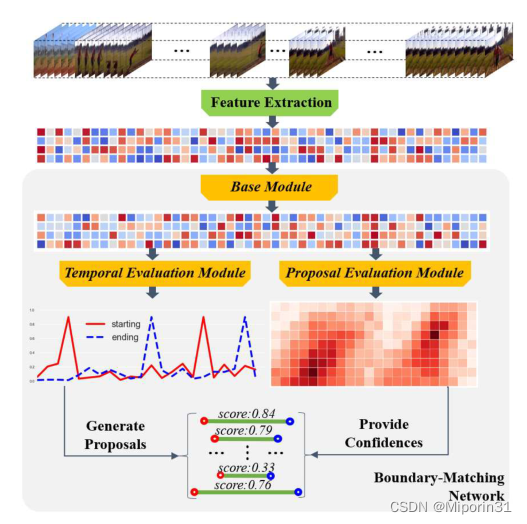
与BSN方法的比较:BMN算法是对BSN算法的改进,BSN算法的缺点:PEG模块对于候选proposal的特征构建和置信度评估是分开进行的,效率低;TEM模块对每个时刻采用局部上下文信息进行特征建模,proposal特征的构建缺少丰富的时序上下文信息;算法中包含多个处理步骤:视频特征提取、TEM、PGM、PEM等,是一个多阶段的算法模型,不是一个统一的网络模型。
方法:在BM机制中,首先定义一个BM层用来从输入的特征序列中生成BM特征图,在BM特征图中,包含每个proposal丰富的特征和上下文信息,然后对于BM特征图使用卷积层来计算得到BM置信度图。在特征提取完成后,利用BMN同时生成时间边界概率序列和BM置信度图,然后根据边界概率构造建议,从BM置信图中得到相应的置信度评分。
优点:引入了边界匹配机制来评估密集分布的建议的可信度分数,它可以很容易地嵌入到网络中;边界匹配网络能够同时生成具有明确时间边界和可靠置信度的提议,两个分支在一个统一的框架内联合训练。
缺点:丢弃了动作信息,仅采用边界匹配来捕获低层特征,不能处理复杂的活动和杂乱的场景;采用与BSN相同的方法来生成边界概率序列而不是图,缺乏对具有模糊边界和可变时间持续时间的动作提议的全局范围。
8.Fast Learning of Temporal Action Proposal via Dense Boundary Generator
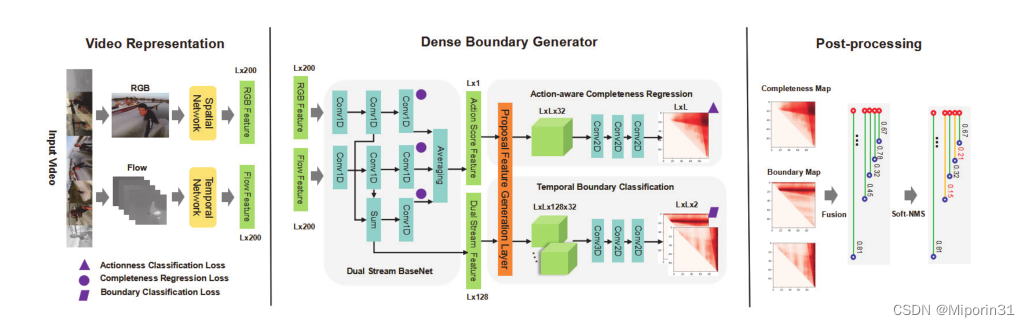
与之前方法的比较:提出了一种快速的、端到端的密集边界动作生成器(DBG),该生成器能够对所有的动作提名估计出密集的边界置信图;设计一种高效的提议特征生成层,该层能够有效捕获动作的全局特征,便于后面的分类和回归模块。
方法:在视频表示阶段,利用时空网络对视频内容进行编码。双流网络的输出分数分别用作RGB和流特征,并被输入到密集边界生成器中。DSB可以被视为DBG的骨干,以利用视频序列中丰富的局部行为。DSB将生成两种类型的特征:低级双流特征和高级动作评分特征。建议特征生成(PFG)层将这两种类型的序列特征转换成类似矩阵的特征。ACR将采取行动评分特征作为输入,为密集提案生成行动完整性评分图。TBC将根据双流特征生成时间边界置信图。最后,后处理步骤通过得分图融合和软NMS生成具有边界和置信度的密集建议。
优点:提出密集边界生成器使用全局提议特征预测边界图,并探索用于动作完整性分析的动作感知特征。设计了一个高效的提议特征生成层,为后续回归和分类模块捕获全局提议特征。
缺点:尽管在定位动作边界和预测动作评分中是有用的,但是仅仅基于局部信息,而忽略了长期的上下文信息。
9.Accurate Temporal Action Proposal Generation with Relation-Aware Pyramid Network
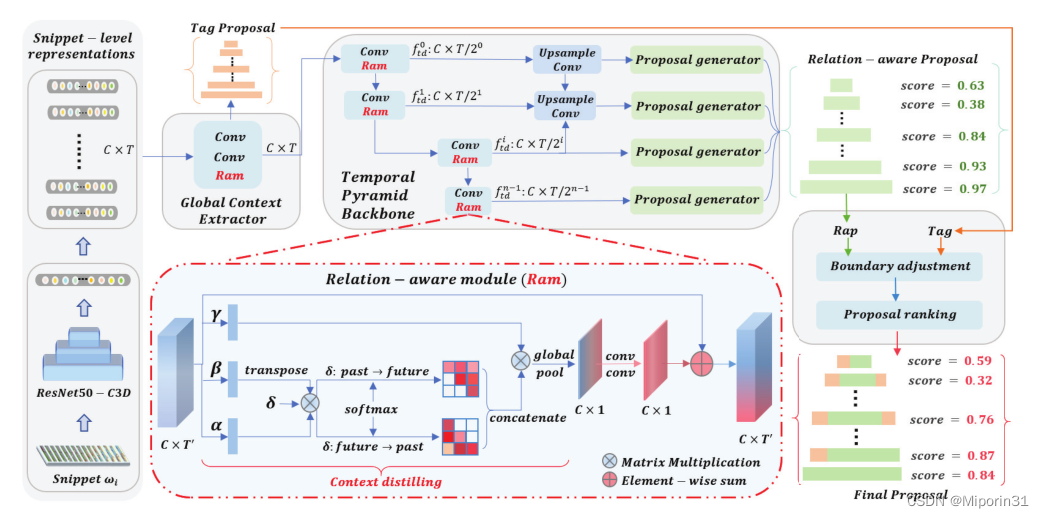
与之前方法的比较:之前的自下向上的方法,尽管在定位动作边界和预测动作评分中是有用的,但是仅仅基于局部信息,而忽略了长期的上下文信息,本方法引入了一个新的关系感知模块来利用大范围的上下文信息。
方法:首先,ResNet50-C3D用于片段级视频表示。然后,全局上下文提取器捕获远程依赖性,以根据动作头预测每个片段的动作概率。下面的时间金字塔主干使用关系感知模块进行增强,通过锚头分别生成不同持续时间的候选实例。最后,将关系感知建议与候选标签相结合,调整边界,并通过建议排序来测量置信度得分进行检索。引入了一个新的关系感知模块(RAM)来提取远程上下文。然后,全局上下文提取器使用RAM来捕获整体信息,以增强完整的局部特征。下面的时间金字塔主干也被RAM增强,以执行多个时间尺度的行动建议。
优点:通过构建一个自下向上的特征金字塔集解决同时定位具有不同持续时间的动作实例问题;引入了一个新的关系感知模块,利用局部特征之间的双向长程关系进行上下文提取以捕捉高精度边界的信息内容。
缺点:生成的提案的边界和评分机制在未来的工作中还有待完善。