云平台运营开发
1、腾讯云平台
- 阿里云有核心技术;2)阿里云操作面板的用户体验好;
- 腾讯云在售后方面做的比较好,有专门的客服;
- 腾讯云至今已经发生了数起数据丢失;
- 腾讯云价格更优惠;
- 单纯依赖跑分去选择产品,是非常片面的决断。是短期测量,不能代表长期的稳定性;
- 计算能力,cpu的计算能力,需要看高主频。采用提升IPC的方式,更具性价比。
- 稳定性,服务器CPU性能波动,vCPU的绑定,两个vCPU业务运行稳定;
- 简单总结一下,要获得更好的计算性能,核数比主频更具性价比。
- 对于企业级用户来说,优先选择vCPU绑定的实例,计算性能更稳定、可预期。
- 不绑定vCPU在闲时可获得更高的性能,但隔离性差,不可预期,有一定业务风险。
- 在最终选型上,还是要根据自己的业务形态来选择合适的实例。
- 同时,我们也需要有清醒的认识,对云服务器来说性能测试和实际应用会有偏差,比如vCPU的绑定与否就会影响性能测试结果。
个人看法,一款产品的设计或者特色都需要有针对性,像我一开始接项目开发的时候,做的都是个体小商户以及初创企业,对于他们来说关注的是价格和安全性,经常会问数据安全,以及长时间使用的价格,还有就是操作简易性。他们木有具体的技术进行运营维护,所以稳定性和简易性成为了必然要求。
而对于大企业,他们对服务器要求更高,主要在于并发量和计算能力。
还有就是各自的特色,例如阿里云的网站,企业网站、电子商务、金融保险等等行业,阿里云掌握主动权。以此为基础,他们开始深入比较重的工业化场景,例如医疗、工业、航空、电影渲染等等。所以我们看到了阿里巴巴近来很重视工业互联网!
腾讯云的小程序,以及基础承载,探索泛互联网、泛政府、传统企业等领域的智慧产业升级方案,进一步连接消费者与商业服务,提升社会的生产和商业效能。腾讯云副总裁曾佳欣表示,腾讯云要做“信息能源发动机”的定位。
2、Laas:
LaaS(基础设施) 出租计算、存储、网络、DNS等基础IT服务;软件即服务,简单来说就是把企业想要的功能开发好成应用软件,然后直接卖给用户使用。通俗点讲就是去饭店吃饭一样,什么都是店家的。 IaaS, 资源层面的灵活性。资源弹性
3、Paas:
PaaS(基础设施+系统平台—应用服务器应用框架 编程语言) 提供应用运行和开发环境 提供应用开发组件(邮件、消息、计费、支付);平台即服务,简单来说就是云计算平台提供硬件、编程语言、开发库等帮助用户更好更快的开发软件。通俗来说就是点外卖,使用时店家的,但是餐桌是自己的。用于管理资源以上的应用弹性的问题。其实大致分两部分,一部分我称为你自己的应用自动安装,一部分我称为通用的应用不用安装。要么是自动部署,要么是不用部署,总的来说就是应用层你也要少操心,这就是PaaS层的重要作用。
4、Saas:
基础设施+系统平台+软件应用)互联网Web2.0应用 企业应用(ERP/CRM等);基础设施即服务,简单来说就是云服务商提供企业所需要的服务器、存储、网络给企业用。通俗来说就是买菜买面,回家自己做饭。
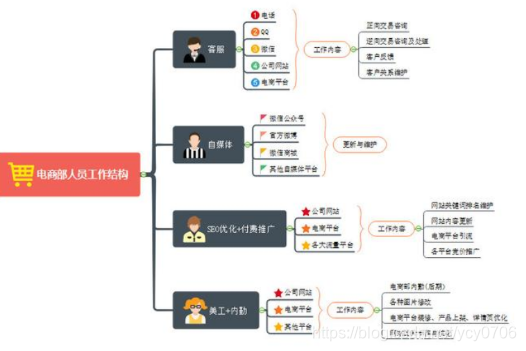
5、运营架构:
http://www.sohu.com/a/157167943_816085
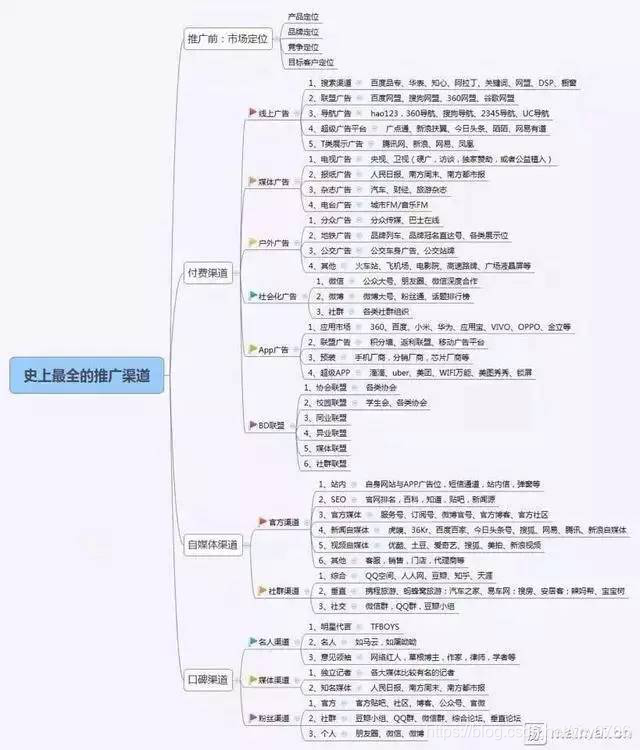
6、数据技术应用
市场和渠道分析优化;产品和服务优化;舆情分析;https://blog.csdn.net/garyond/article/details/81229199(1)产品优化,保单个性化。过去在没有精细化的数据分析和挖掘的情况下,保险公司把很多人都放在同一风险水平之上,客户的保单并没有完全解决客户的各种风险问题。但是,保险公司可以通过自有数据以及客户在社交网络的数据,解决现有的风险控制问题,为客户制定个性化的保单,获得更准确以及更高利润率的保单模型,给每一位顾客提供个性化的解决方案。(2)运营分析。基于企业内外部运营、管理和交互数据分析,借助大数据台,全方位统计和预测企业经营和管理绩效。基于保险保单和客户交互数据进行建模,借助大数据平台快速分析和预测再次发生或者新的市场风险、操作风险等。(3)代理人(保险销售人员)甄选。根据代理人员(保险销售人员)业绩数据、性别、年龄、入司前工作年限、其它保险公司经验和代理人人员思维性向测试等,找出销售业绩相对最好的销售人员的特征,优选高潜力销售人员。
7、推广拓展:
推广失败的原因:没有正确评估渠道是否适合自己的产品;没有熟悉渠道的规则和推广逻辑;没有搭建好转化场景;没有做数据监测来指导优化;步骤一:定义用户、入口与推广方式,找出潜在渠道;步骤二:评估渠道,熟悉渠道规则及推广逻辑;步骤三:搭建转化场景;步骤五:数据监测&优化;
8、运营架构平台
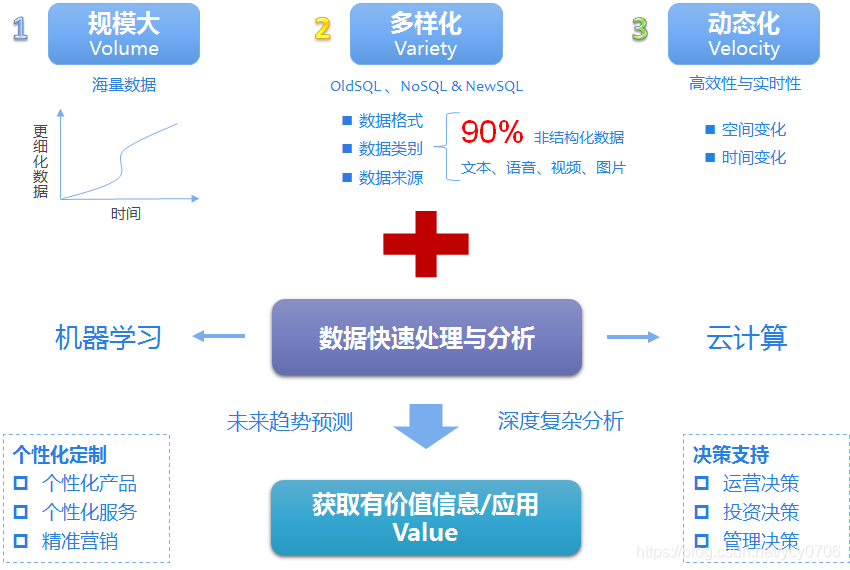
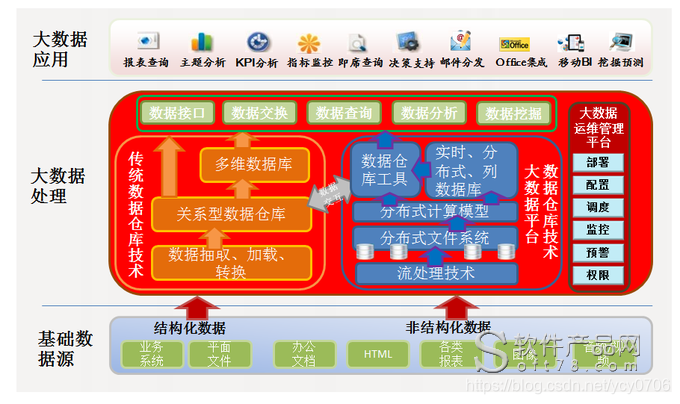
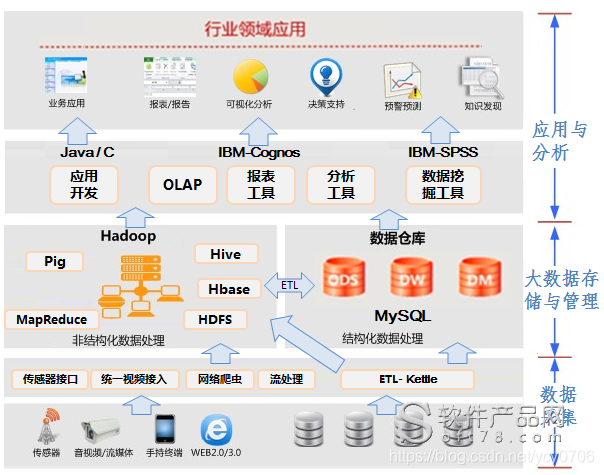
9、大数据
【十大经典数据挖掘算法】
C4.5:决策树(decision tree)算法基于特征属性进行分类,其主要的优点:模型具有可读性,计算量小,分类速度快。
K-Means:kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
SVM:是分类算法;线性可分(linear SVM in linearly separable case)的线性SVM、线性不可分的线性SVM、非线性(nonlinear)SVM。
Apriori:关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。
EM:EM算法(Expectation Maximization)是在含有隐变量(latent variable)的模型下计算最大似然的一种算法。所谓隐变量,是指我们没有办法观测到的变量。
PageRank:用来解决链接分析中网页排名的问题。
AdaBoost:集成学习(ensemble learning)通过组合多个基分类器(base classifier)来完成学习任务,颇有点“三个臭皮匠顶个诸葛亮”的意味。基分类器一般采用的是弱可学习(weakly learnable)分类器,通过集成学习,组合成一个强可学习(strongly learnable)分类器。所谓弱可学习,是指学习的正确率仅略优于随机猜测的多项式学习算法;强可学习指正确率较高的多项式学习算法。集成学习的泛化能力一般比单一的基分类器要好,这是因为大部分基分类器都分类错误的概率远低于单一基分类器的。
kNN:kNN算法的核心思想非常简单:在训练集中选取离输入的数据点最近的k个邻居,根据这个k个邻居中出现次数最多的类别(最大表决规则),作为该数据点的类别。
Naïve Bayes:朴素贝叶斯(Naïve Bayes)属于监督学习的生成模型,实现简单,没有迭代,学习效率高,在大样本量下会有较好的表现。但因为假设太强——假设特征条件独立,在输入向量的特征条件有关联的场景下并不适用。
CART:CART本质是对特征空间进行二元划分(即CART生成的决策树是一棵二叉树),并能够对标量属性(nominal attribute)与连续属性(continuous attribute)进行分裂。
数据分析工具:
1)大数据分析的最好工具:Hadoop是一个能够对大量数据进行分布式处理的软件框架。、HPCC高性能计算与通信、Storm是自由的开源软件,一个分布式的、容错的实时计算系统。Storm可以非常可靠的处理庞大的数据流,用于处理Hadoop的批量数据。、Apache Drill帮助支持广泛的数据源、数据格式和查询语言。、RapidMiner是世界领先的数据挖掘解决方案,在一个非常大的程度上有着先进技术。它数据挖掘任务涉及范围广泛,包括各种数据艺术,能简化数据挖掘过程的设计和评价。、Pentaho BI平台不同于传统的BI 产品,它是一个以流程为中心的,面向解决方案(Solution)的框架。其目的在于将一系列企业级BI产品、开源软件、API等等组件集成起来,方便商务智能应用的开发。
10、云计算:
云计算最初的目标是对资源的管理,管理的主要是计算资源,网络资源,存储资源三个方面。
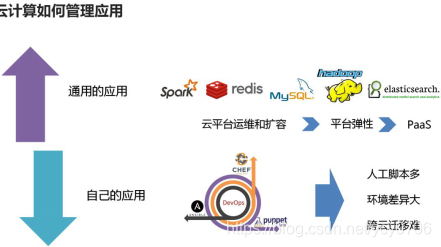
容器技术Docker,在PaaS层中一个复杂的通用应用就是大数据平台。
11、数据结构:
常用的数据结构有:数组:在内存中的分配也是连续的,数组中的元素通过数组下标进行访问,数组下标从0开始。,栈:仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作。,链表非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域 (内存空间),另一个是指向下一个结点地址的指针域。根据指针的指向,链表能形成不同的结构,例如单链表,双向链表,循环链表等。,队列队列可以在一端添加元素,在另一端取出元素,树:它是由n(n>=1)个有限节点组成一个具有层次关系的集合。,图:在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。,堆:可以被看做一棵树的数组对象,常见的堆有二叉堆、斐波那契堆等。,散列表:也叫哈希表,是根据关键码和值 (key和value) 直接进行访问的数据结构,通过key和value来映射到集合中的一个位置,这样就可以很快找到集合中的对应元素。等。
12、数据库原理
- 存储过程,常用的关系型数据库是MySQL,操作数据库的语言一般为SQL语句,SQL在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成某种特定功能的SQL语句集。
- 索引,索引(Index)是帮助MySQL高效获取数据的数据结构;在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,可以在这些数据结构上实现高级查找算法,提高查询速度,这种数据结构,就是索引。B-Tree 索引:最常见的索引类型,大部分引擎都支持B树索引。HASH 索引:只有Memory引擎支持,使用场景简单。R-Tree 索引(空间索引):空间索引是MyISAM的一种特殊索引类型,主要用于地理空间数据类型。Full-text (全文索引):全文索引也是MyISAM的一种特殊索引类型,主要用于全文索引,InnoDB从MySQL5.6版本提供对全文索引的支持。普通索引,UNIQUE索引,主键:PRIMARY KEY索引。在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为数据表增加索引。索引是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。
- B+ 树,非叶子节点不存储真实的数据,只存储指引搜索方向的数据项。
- 事务,事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,由一条或者多条sql语句组成,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。事务分为一下5类:扁平事务;带有保存点的扁平事务;链事务;嵌套事务;分布式事务。
- 视图,视图是一种虚拟的表,具有和物理表相同的功能,可以对视图进行增,改,查操作,视图通常是有一个表或者多个表的行或列的子集,对视图的修改不影响基本表,它使得我们获取数据更容易,相比多表查询。
- 超键 候选键 主键 外键,超键:在关系中能唯一标识元组(数据库中的一条记录)的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。候选键:是最小超键,即没有冗余元素的超键。主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合,用户选作元组标识的一个侯选键称为主键。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。外键:在一个表中存在的另一个表的主键称此表的外键,外键主要是用来描述两个表的关系。
- 三个范式,第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。第二范式(2NF):数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。第三范式(3NF):在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合第三范式。所谓传递函数依赖,指的是如 果存在”A → B → C”的决定关系,则C传递函数依赖于A。因此,满足第三范式的数据库表应该不存在如下依赖关系: 关键字段 → 非关键字段 x → 非关键字段y。
- E-R图,E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
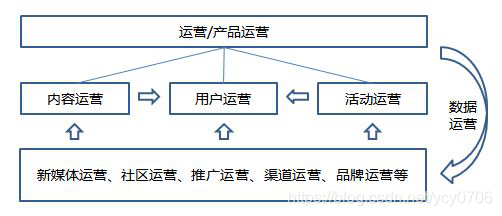
13、运营基础结构:
运营一定是围绕产品展开的;产品的发展生命周期(1、初创阶段:主要包括了:产品的创意,构思,调研,研发,生产,测试、面市、调整等并最终积累一定量客户的过程。2、成长阶段:通过初创阶段的摸索,找到了一个成功的模式,便会进入到快速的成长阶段,这个阶段其实也是最考研运营的一个阶段。3、成熟阶段:通过成长阶段的快速发展,随着这个行业本身的市场天花板以及外部竞争的涌入,慢慢进入到一个平稳的状态。4、衰退阶段:最后随着社会的进步,科技的发展,习惯的改变等原因,产品就会慢慢的呈衰退趋势,并最终退出舞台。运营, 即是在产品的各个发展阶段,去做各种各样的事情,来帮助产品进行成长。)内容运营、活动运营、用户运营 这三个维度几乎已经涵盖了运营的所有方面。

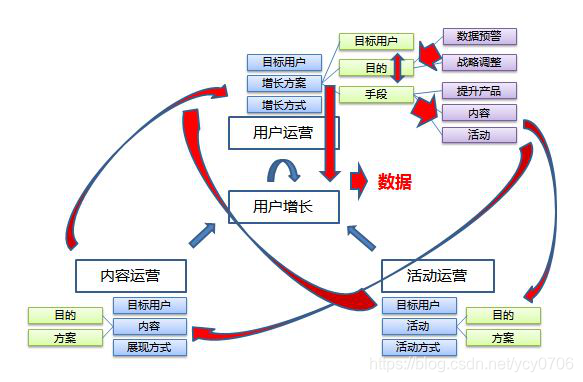
新媒体运营,一般是在 内容运营 → 展现内容这一条线下面的。
社区运营,一般是在 用户运营 → 留存、促活 这一条线下面的。
推广运营,一般是在 用户运营 → 拉新这一条线下面的。
渠道运营,一般是在 内容运营 → 扩散分发这一条线下面的。
品牌运营,其运营的手法也是通过这三种运营种类的集合。
数据运营,我们可以认为是用户运营的发展过程中,用数据对决策进行支持的一种手段。
用户运营: 拉新、留存、促活、转化;一切以数据为主要分析入口