describe()函数可以查看DataFrame中数据的基本情况
参数:
- include:包含哪类数据。默认只包含连续值,不包含离散值;include = ‘all’ 设置全部类型
- percentiles:设置输出的百分位数,默认为[.25,.50,.75],返回第25,50,75百分位数

原数据:
data = pd.read_table(path)
data.head()

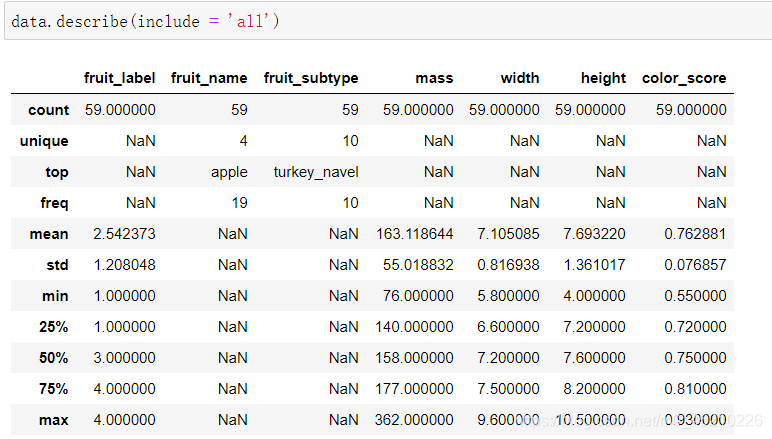
使用describe函数之后:
data.describe(include = 'all')

分析:
对连续值来说:
- count:每一列非空值的数量
- mean: 每一列的平均值
- std:每一列的标准差
- min:最小值
- 25%:25%分位数,排序之后排在25%位置的数
- 50%:50%分位数
- 75%:75%分位数
- max:最大值
对离散值来说特有的:
- unique:不重复的离散值数目,去重之后的个数
- top: 出现次数最多的离散值
- freq: 上述的top出现的次数
也可以对单列进行分析
data['mass'].describe()

data['fruit_name'].describe()

版权声明:本文为m0_45210226原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。