微服务架构设计模式笔记--第六章 使用事件溯源开发业务逻辑
1. 使用事件溯源开发业务逻辑概述
事件溯源是构建业务逻辑和持久化聚合的另一种选择。它将聚合以一系列事件的方式持久化保存。每个事件代表聚合的一次状态变化。应用程序通过重放(replaying)事件来重新创建聚合的当前状态。
事件溯源有几个重要的好处。例如,它保留了聚合的历史记录,这对于实现审计和监管的功能非常有帮助。它可靠地发布领域事件,这在微服务架构中特别有用。事件溯源也有弊端。它有一定的学习曲线,因为这是一种完全不同的业务逻辑开发方式。此外,查询事件存储库通常很困难,这需要你使用第7章中描述的CQRS模式。
1.1 传统持久化技术的问题
- 对象与关系的“阻抗失调”
所谓的对象与关系的“阻抗失调”是一个古老的问题。关系型数据的表格结构模式,与领域模型及其复杂关系的图状结构之间,存在基本的概念不匹配问题。 - 缺乏聚合的历史
传统持久化的另一个限制是它只存储聚合的当前状态。聚合更新后,其先前的状态将丢失。实现聚合历史记录机制是非常耗时的一项工作,其中还会涉及复制那些必须与业务逻辑保持同步的代码。 - 实施审计功能将非常烦琐且容易出错
实施审计是一项耗时的工作,负责记录审计日志的代码可能会和业务逻辑代码发生偏离,从而导致各种错误。 - 事件发布是凌驾于业务逻辑之上
传统持久化的另一个限制是它通常不支持发布领域事件。
1.2 什么是事件溯源
事件溯源是一种以事件为中心的技术,用于实现业务逻辑和聚合的持久化。聚合作为系列事件存储在数据库中。每个事件代表聚合的状态变化。聚合的业务逻辑围绕生成和使用这些事件的要求而构建。
事件溯源通过事件来持久化聚合
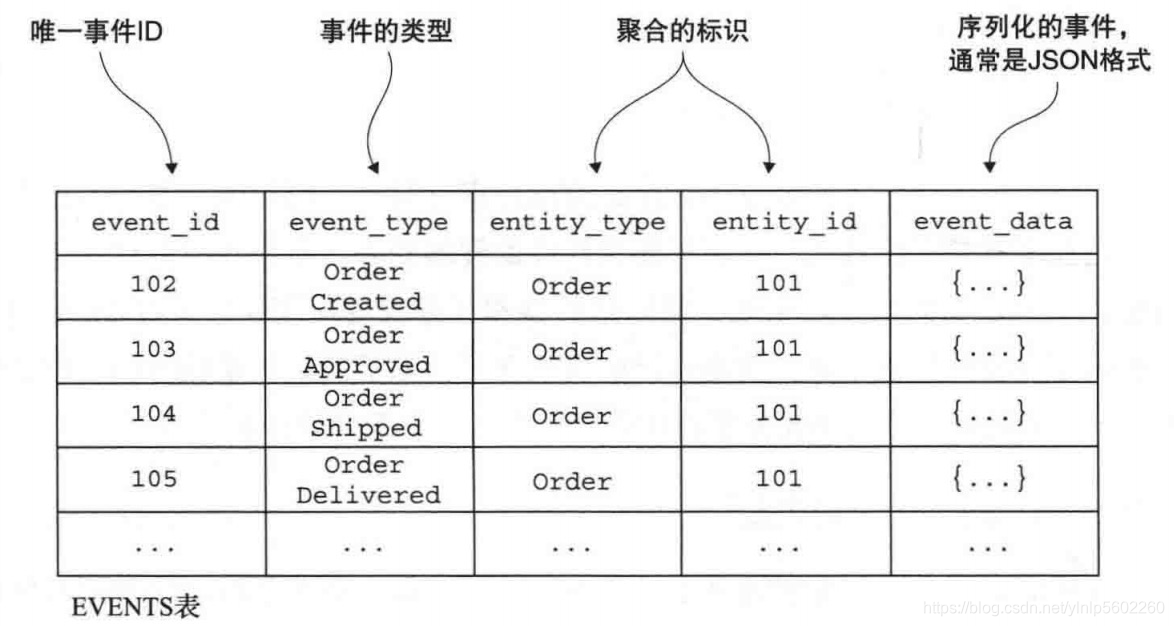
传统持久化技术将聚合的字段映射到数据库表的列,将聚合的实例映射到数据库表的行。事件溯源采用基于领域事件的概念来实现聚合的持久化,它将每个聚合持久化为数据库中的系列事件,称之为事件存储。
当应用程序创建或更新聚合时,它会将聚合发出的事件插入到 EVENTS表中。应用程序通过从事件存储中检索并重放事件来加载聚合。具体来说,加载聚合包含以下三个步骤:
- 加载聚合的事件。
- 使用其默认构造函数创建聚合实例
- 调用 apply()方法遍历事件。
例如,Eventuate Client框架使用类似于以下的代码来重建聚合:
Class aggregateClass = ...;
Aggregate aggregate aggregateClass = newInstance();
for (Event event : events){
aggregate = aggregate.applyEvent(event);
}
// use aggregate
事件代表状态的改变

事件中必须包含聚合执行状态变化所需的数据。如图所示,聚合的当前状态是S,新状态是S’。表示状态更改的事件E必须包含必要的数据,以便当 Order处于状态S时,调用order.apply(E)可以将订单更新为状态S’。
聚合方法都和事件相关

创建聚合的步骤如下:
- 使用聚合的默认构造函数实例化聚合根。
- 调用 process()以生成新事件。
- 遍历新生成的事件并调用apply()来更新聚合的状态。
- 将新事件保存在事件存储库中。
更新聚合的步骤如下:
- 从事件存储库加载聚合事件。
- 使用其默认构造函数实例化聚合根。
- 遍历加载的事件,并在聚合根上调用 apply()方法。
- 调用其 process()方法以生成新事件
- 遍历新生成的事件并调用apply()来更新聚合的状态。
- 将新事件保存在事件存储库中。
1.3 使用乐观锁处理并发更新
UPDATE AGGREGATE_ROOT_TABLE
SET VERSION = VERSION + 1 ...
WHERE VERSION = <original version>
事件存储库也可以使用乐观锁来处理并发更新。每个聚合实例都有一个与事件一起读取的版本号。当应用程序插入事件时,事件存储会验证版本是否未更改。
1.4 事件溯源和发布事件
严格来说,事件溯源将聚合作为事件进行持久化,并从这些事件中重建聚合的当前状态。你还可以将事件溯源作为可靠的事件发布机制。在事件存储库中保存事件本质上是一个原子化的操作。我们需要实现一种机制,将这些持久化保存的事件传递给所有感兴趣的消费者。
- 使用轮询发布事件
事件发布方将使用以下过程:
- 通过执行此SELECT语句查找未发布的事件:SELECT * FROM EVENTS WHERE PUBLISHED = 0 ORDER BY event id ASC。
- 将事件发布到消息代理。
- 将事件标记为已发布:UPDATE EVENTS SET PUBLISHED=1 WHERE EVENT_ID in。
- 使用事务日志拖尾技术来可靠地发布事件
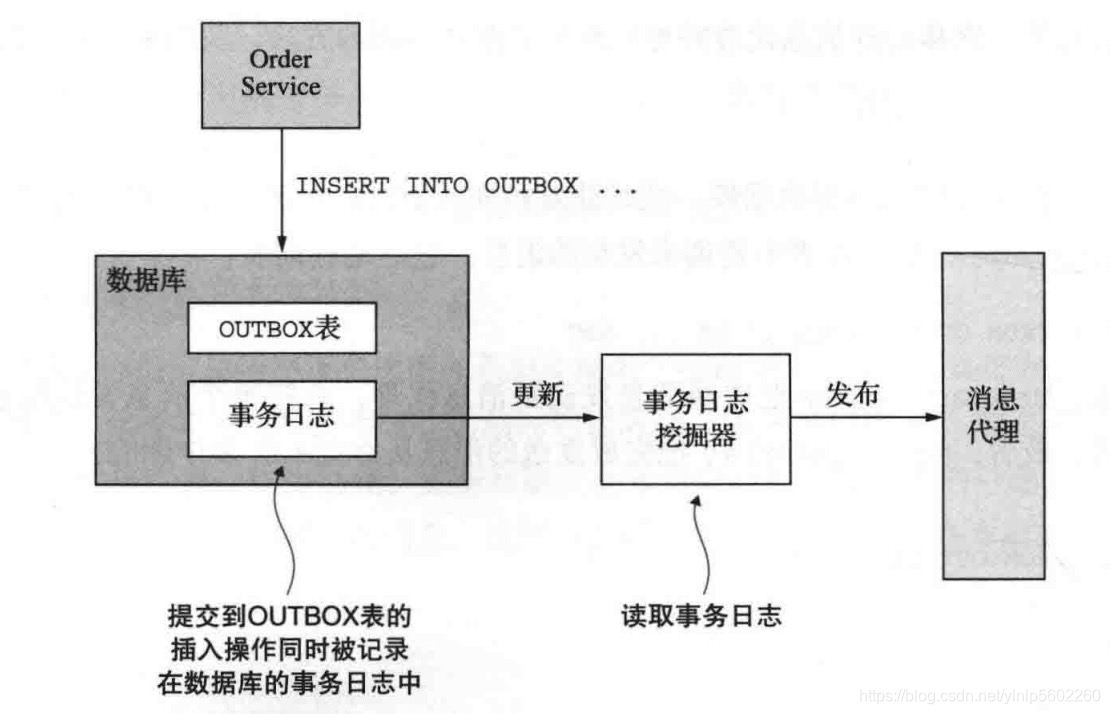
服务通过挖掘数据库的事务日志来发布插入到OUTBOX表中的消息。
1.5 使用快照提升性能

使用快照可以避免加载聚合的所有事件,从而提高性能。应用程序只需要加载快照以及之后发生的事件。
1.6 幂等方式的消息处理
- 基于关系型数据库事件存储库的幂等消息处理
如果应用程序使用基于关系型数据库的事件存储库,则可以将消息ID插入PROCESSED_MESSAGES表,作为插入EVENTS表的事件的事务的一部分来检测和丢弃重复消息。 - 基于非关系型数据库事件存储库的幂等消息处理
消息消费者把消息的ID存储在处理它时生成的事件中。通过验证聚合的所有事件中是否包含该消息ID来做重复检测。
1.7 领域事件的演化
通过向上转换来管理结构的变化:向事件添加字段不太可能影响接收方。因为接收方会忽略那些未知的字段。但是,其他更改不向后兼容。例如,更改事件名称或字段名称,都需要更改该事件类型的消费者。
1.8 事件溯源的好处和弊端
好处:
- 可靠地发布领域事件。
- 保留聚合的历史。
- 最大限度地避免对象与关系的“阻抗失调”问题。
- 为开发者提供一个“时光机”。
弊端:
- 这类编程模式有一定的学习曲线。
- 基于消息传递的应用程序的复杂性。
- 处理事件的演化有一定难度。
- 删除数据存在一定难度。
- 查询事件存储库非常有挑战性。
2 实现事件存储库
2.1 Eventuate Local 事件存储库的工作原理

Eventuate Local的架构包含一个存储事件的事件数据库(如MySQL)、一个向订阅者传递事件的事件代理(如Apache Kafka),以及一个将事件数据库中存储的事件发布到事件代理的事件中继。
- events:存储事件。
数据库结构中最核心的表是events表。
create table events(
event_id varchar(1000)PRIMARY KEY,
event_type varchar(1000),
event_data varchar(1000)NOT NULL,
entity_type VARCHAR(1000)NOT NULL,
entity_id VARCHAR(1000)NOT NULL,
triggering_event VARCHAR(1000)
);
- entities:每个实体一行。
entities表存储每个实体的当前版本。它用于实现乐观锁。
create table entities(
entity_type VARCHAR(1000),
entity_id VARCHAR(1000),
entity_version VARCHAR(1000)NOT NULL,
PRIMARY KEY(entity_type,entity_id)
);
# 更新sql语句
UPDATE entities SET entity_version=?
WHERE entity_type=?and entity_id=?and entity_version=?
- snapshots:存储快照。
snapshots表存储每个实体的快照。
create table snapshots(
entity_type VARCHAR(1000),
entity_id VARCHAR(1000),
entity_version VARCHAR(1000),
snapshot_type VARCHAR(1000)NOT NULL
snapshot_json VARCHAR(1000)NOT NULL,
triggering_events VARCHAR(1000),
PRIMARY KEY(entity_type,entity_id,entity_version)
);
2.2 Eventuate 的 Java 客户端框架

- 通过ReflectiveMutableCommandProcessingAggregate类定义聚合
public class Order extends ReflectiveMutableCommandProcessingAggregate<Order, OrderCommand> {
public List<Event> process (CreateOrderCommand command){......}
public void apply (OrderCreatedEvent event) {....}
}
- 定义聚合的命令
public interface OrderCommand extends Command {}
public class CreateOrderCommand implements OrderCommand { ... }
- 定义领域事件
interface OrderEvent extends Event {}
public class OrderCreated extends OrderEvent { ... }
- 使用AggregateRepository类创建、查找和更新聚合
public class OrderService {
private AggregateRepository<Order, OrderCommand> orderRepository;
public OrderService(AggregateRepository<Order, OrderCommand> orderRepository){
this.orderRepository = orderRepository;
}
public EntityWithIdAndversion<Order> createOrder(OrderDetails orderDetails){
return orderRepository.save(new CreateOrder(orderDetails));
}
}
- 订阅领域事件
@EventSubscriber(id="orderServiceEventHandlers")
public class OrderServiceEventHandlers {
@EventHandlerMethod
public void creditReserved(EventHandlerContext<CreditReserved> ctx){
CreditReserved event = ctx.getEvent();
...
}
}
3 同时使用Saga和事件溯源
3.1 创建编排式Saga
Saga编排器由服务的方法创建。服务的方法,例如OrderService.createOrder(),会执行两项操作:创建或更新聚合,并创建Saga编排器。该服务必须以保证方法的第一个和第二个操作会在同一个事务的范围内完成,也就是说,如果第一个操作执行成功了,必须确保第二个操作也要执行成功。服务如何确保这一点,取决于它使用的事件存储库的类型。
当非关系型数据库作为事件存储库时,使用基于关系型数据库的事件存储库的服务也可以使用相同的事件驱动方法来创建Saga。这种方法的一个好处是它可以保证松藕合,因为OrderService之类的服务不再明确地实例化Saga。
3.2 实现基于事件溯源的Saga参与方
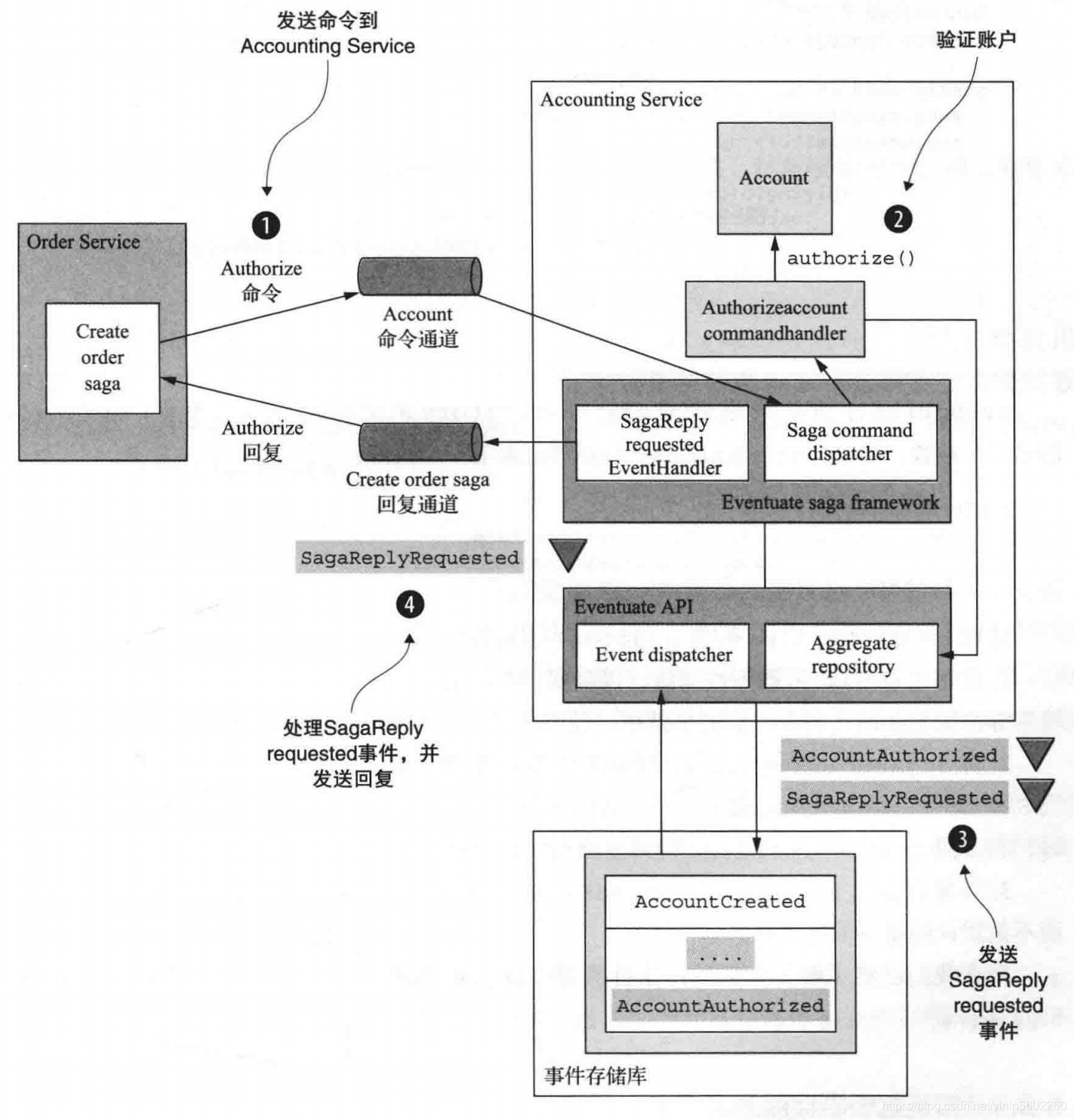
3.3 实现基于事件溯源的 Saga 编排器
- 使用事件溯源持久化Saga编排器
一个Saga编排器的生命周期非常简单。首先,它被创建,然后它被更新,用以响应来自Saga参与方的回复。因此,我们可以使用以下事件持久化Saga:
- SagaOrchestratorCreated:Saga编排器已创建。
- SagaOrchestratorUpdated:Saga编排器已更新。
- 可靠地发送命令式消息

Saga编排器使用两步过程发送命令:
- 一个Saga编排器为它想要发送的每个命令发出一个SagaCommandEvent。
SagaCommandEvent包含发送命令所需的所有数据,例如目标通道和命令对象。这些事件存储在事件存储库中。 - 事件处理程序处理这些SagaCommandEvents并将命令式消息发送到目标消息通道。
这种两步法可确保命令至少发送一次。
- 确保只处理一次回复消息
Saga编排器还需要检测并丢弃重复的回复消息,它可以使用前面描述的机制来完成。编排器将回复消息的ID存储在处理回复时发出的事件中。然后,它可以轻松地确定消息是否重复。
如你所见,事件溯源是实现Saga的良好基础。事件溯源拥有众多好处,例如数据更改时可靠地生成事件、可靠的审计日志记录以及执行历史状态查询的能力。但是,事件溯源同样也不是包治百病的“银弹”。它的学习曲线比较陡峭。演化事件结构并不总是轻而易举的。但是,尽管有这些缺点,事件溯源仍然在微服务架构中发挥着重要作用。
想尝试事件溯源可以试试Axon Framework框架。