基础语法
变量声明
var
Go 语言引入了关键字 var,并且将类型信息放在变量名之后,此外,变量声明语句不需要使用分号作为结束符
//单定义
var varib int
//多变量定义
var (
varib1 int
varib2 string
)
//省略写法
varib3 := 14
//变量数据类型
var v1 int // 整型
var v2 string // 字符串
var v3 bool // 布尔型
var v4 [10]int // 数组,数组元素类型为整型
var v5 struct { // 结构体,成员变量 f 的类型为64位浮点型
f float64
}
var v6 *int // 指针,指向整型
var v7 map[string]int // map(字典),key为字符串类型,value为整型
var v8 func(a int) int // 函数,参数类型为整型,返回值类型为整型
常量和枚举
常量
通过 const 关键字定义常量时,可以指定常量类型,也可以省略(底层会自动推导)
//定义常量数据类型
const Pi float64 = 3.1415926
//省略常量类型
const Pi1 = 3.1415926
//通过一个 const 关键字定义多个常量,和 var 类似
const(
Pi3 int
Pi4 = 3
)
// u = 0.0, v = 3.0,常量的多重赋值
const u, v float32 = 0, 3
// a = 3, b = 4, c = "foo", 无类型整型和字符串常量
const a, b, c = 3, 4, "foo"
预定义常量
Go 语言预定义了这些常量:true、false 和 iota,iota 比较特殊,可以被认为是一个可被编译器修改的常量,在每一个 const 关键字出现时被重置为 0,然后在下一个 const 出现之前,每出现一次 iota,其所代表的数字会自动增 1。
const ( // iota 被重置为 0
c0 = iota // c0 = 0
c1 = iota // c1 = 1
c2 = iota // c2 = 2
)
const (
u = iota * 2; // u = 0
v = iota * 2; // v = 2
w = iota * 2; // w = 4
)
const x = iota; // x = 0
const y = iota; // y = 0
两个 const 的赋值语句的表达式是一样的,那么还可以省略后一个赋值表达式
const (
c0 = iota
c1
c2
)
const (
u = iota * 2
v
w
)
枚举
Go 语言并不支持其他语言用于表示枚举的 enum 关键字,而是通过在 const 后跟一对圆括号定义一组常量的方式来实现枚举。
const (
Sunday = iota
Monday
Tuesday
Wednesday
Thursday
Friday
Saturday
numberOfDays
)
常量的作用域
- 和函数体外声明的变量一样,以大写字母开头的常量在包外可见,类似于 public 修饰的类属性。
- 以小写字母开头的常量只能在包内访问,类似于通过 protected 修饰的类属性。
- 函数体内声明的常量只能在函数体内生效。
数据类型
布尔类型
关键字为 bool,可赋值且只可以赋值为预定义常量 true 和 false
//定义
var v1 bool
v1 = true
// v2 也会被推导为 bool 类型
v2 := (1 == 2)
// 打印结果为Result: true
fmt.Println("Result:", v2)
//第二种写法 推导
var b bool
// 编译正确
b = (1!=0)
// 打印结果为Result: true
fmt.Println("Result:", b)
整型
整型是所有编程语言里最基础的数据类型,Go 语言默认支持如下这些整型类型
| 类型 | 长度 | 说明 | 值范围 | 默认 |
|---|---|---|---|---|
| int8 | 1 | 带符号8位整型 | -128~127 | 0 |
| uint8 | 1 | 无符号8位整型,与 byte 类型等价 | 0~255 | 0 |
| int16 | 2 | 带符号16位整型 | -32768~32767 | 0 |
| uint16 | 2 | 无符号16位整型 | 0~65535 | 0 |
| int32 | 4 | 带符号32位整型,与 rune 类型等价 | -2147483648~2147483647 | 0 |
| uint32 | 4 | 无符号32位整型 | 0~4294967295 | 0 |
| int64 | 8 | 带符号64位整型 | -9223372036854775808~9223372036854775807 | 0 |
| uint64 | 8 | 无符号64位整型 | 0~18446744073709551615 | 0 |
| int | 32位或64位 | 与具体平台相关 | 与具体平台相关 | 0 |
| uint | 32位或64位 | 与具体平台相关 | 与具体平台相关 | 0 |
| uintptr | 与对应指针相同 | 无符号整型,足以存储指针值的未解释位 | 32位平台下为4字节,64位平台下为8字节 | 0 |
//定义
var i1 int32 = -45
var (
i2 uint32 = 666
i3 int64 = 888
)
//多赋值
var i4,i5,i6 int64 = 123,456,789
浮点类型
Go 语言中的浮点数采用IEEE-754 标准的表达方式,定义了两个类型:float32 和 float64
- Float32,可以精确到小数点后 7 位。
- Float64,可以精确到小数点后 15 位。
//定义
var fat float32
//赋值
fat = 14
//省略写法,如果不加小数点,会被推导为整型而不是浮点型。
fat2 := 3.1415926 //其类型将被自动设置为 float64
//下面的赋值将导致编译错误,float64不能赋值float32。
fat = fat2
//强制类型转换才可以
fat = float32(fat2)
复数类型
复数是实数的延伸,可以通过两个实数(在计算机中用浮点数表示)构成,一个表示实部(real),一个表示虚部(imag)
- complex64(32位实部和虚部)
- complex128(64位实部和虚部)
//定义
var comp1 complex64
comp1 = 1.10 + 10i // 由两个 float32 实数构成的复数类型
comp2 := 1.10 + 10i //和浮点型一样,默认自动推导的实数类型是 float64,所以 comp2 是 complex128
//读取实数
real(comp1) //获得该复数的实部
//读取虚数
imag(comp2)
字符串
在 Go 语言中,字符串是一种基本类型,默认是通过 UTF-8 编码的字符序列,当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节,比如中文编码通常需要 3 个字节。
//声明和初始化
var str1 string
// 变量初始化
str1 = "Hello Golang"
//省略写法
str2 := "你好,明哥哥"
//截取字符串
str[开始|结束]
ch1 := str1[0] // 取字符串的第一个字符
ch2 := str1[:5] //获取索引5之前的字符串
ch3 := str1[5:] //获取索引5之后的字符串
ch4 := str1[3:6] //获取3-6之间的字符串
//字符串长度len
ch5 := len(str2)
//字符串连接
str1 = str1 + "emmmm"
str1 += ",2333333" //简写为这样,效果完全一样
//字符串遍历
n := len(str1)
for i := 0; i < n; i++ {
ch := str1[i] // 依据下标取字符串中的字符,类型为byte
fmt.Println(i, ch)
}
字符类型
- byte(实际上是 uint8 的别名),代表 UTF-8 字符串的单个字节的值。
- rune,代表单个 Unicode 字符
rune 相关的操作,可查阅 Go 标准库的 unicode 包。 另外 unicode/utf8 包也提供了 UTF-8 和 Unicode 之间的转换。
复合类型
指针(pointer)
变量的本质对一块内存空间的命名,可以通过引用变量名来使用这块内存空间存储的值,而指针的含义则指向存储这些变量值的内存地址。
a := 100
var ptr *int
ptr = &a
fmt.Println(ptr)
fmt.Println(*ptr)
//如上,ptr 就是一个指针类型,表示指向存储 int 类型值的指针。我们可以通过 *ptr 获取指针指向内存地址存储的变量值(我们通常将这种引用称作「间接引用」),ptr 本身是一个内存地址值(通过 &a 可以获取变量 a 所在的内存地址),
//所以上述代码打印结果是:
0xc0000a2000
100
- 通过指针传值
通过指针传值就类似于 PHP 中通过引用传值,这样做的好处是节省内存空间,此外还可以在调用函数中实现对变量值的修改,因为直接修改的是指针指向内存地址上存储的变量值,而不是值拷贝。
func swap(a, b *int) {
*a, *b = *b, *a
fmt.Println(*a, *b)
}
func main() {
a := 1
b := 2
swap(&a, &b)
fmt.Println(a, b)
}
//上述代码的打印结果是:
// 2 1
// 2 1
数组(array)
Go 语言中,数组是固定长度的、同一类型的数据集合。数组中包含的每个数据项被称为数组元素,一个数组包含的元素个数被称为数组的长度。
- 常见的数组声明方法
var a [8]byte // 长度为8的数组,每个元素为一个字节
var b [3][3]int // 二维数组(9宫格)
var c [3][3][3]float64 // 三维数组(立体的9宫格)
var d = [3]int{1, 2, 3} // 声明时初始化
var e = new([3]string) // 通过 new 初始化
//:= 对数组进行声明和初始化:
f := [5]int{1,2,3,4,5}
//语法糖省略数组长度的声明:
g := [...]int{1, 2, 3} //Go 会在编译期自动计算出数组长度
- 访问数组元素
可以使用数组下标来访问 Go 语言数组中的元素,数组下标默认从 0 开始,len(arr)-1 表示最后一个元素的下标。
arr := [5]int{1,2,3,4,5}
a1, a2 := arr[0], arr[len(arr) - 1]
//a1 的值是 1,a2 的值是 5。
- 遍历数组
1. for 循环遍历所有数组元素:
for i := 0; i < len(arr); i++ {
fmt.Println("Element", i, "of arr is", arr[i])
}
2. range,用于快速遍历数组中的元素:
for i, v := range arr {
fmt.Println("Element", i, "of arr is", v)
}
- 多维数组
多维数组的操作与一维数组一样,只不过每个元素可能是个数组,在进行循环遍历的时候需要多层嵌套循环
// 通过二维数组生成九九乘法表
var multi [9][9]string
for j := 0; j < 9; j++ {
for i := 0; i < 9; i++ {
n1 := i + 1
n2 := j + 1
if n1 < n2 { // 摒除重复的记录
continue
}
multi[i][j] = fmt.Sprintf("%dx%d=%d", n2, n1, n1 * n2)
}
}
// 打印九九乘法表
for _, v1 := range multi {
for _, v2 := range v1 {
fmt.Printf("%-8s", v2) // 位宽为8,左对齐
}
fmt.Println()
}
切片(slice)
数组切片是一个新的数据类型,与数组最大的不同在于,切片的类型字面量中只有元素的类型,没有长度
//定义
var slice []string = []string{"a", "b", "c"}
- 基于数组
数组切片可以基于一个已存在的数组创建
// 先定义一个数组
months := [...]string{
"January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November", "December"
}
// 基于数组创建数组切片
q2 := months[3:6] // 第二季度
summer := months[5:8] // 夏季
//打印
fmt.Println(q2)
fmt.Println(summer)
/**
结果:
[April May June]
[June July August]
*/
- 基于数组切片
类似于数组切片可以基于一个数组创建,数组切片也可以基于另一个数组切片创建
firsthalf := months[:6]
q1 := firsthalf[:3] // 基于firsthalf的前3个元素构建新数组切片
- 直接创建
Go 语言提供的内置函数 make() 可以用于灵活地创建数组切片。
// 创建一个初始元素个数为 5 的数组切片,元素类型为整型,初始值为 0,容量为 5
mySlice1 := make([]int, 5)
//创建一个初始元素个数为 5 的整型数组切片,初始值为 [0 0 0 0 0],并预留 10 个元素的存储空间(容量为10)
mySlice2 := make([]int, 5, 10)
//直接创建并初始化包含 5 个元素的数组切片
mySlice3 := []int{1, 2, 3, 4, 5}
- 遍历数组切片
//range 关键字可以让遍历代码显得更简洁,range 表达式有两个返回值,第一个是索引,第二个是元素的值
for i, v := range summer {
fmt.Println("summer[", i, "] =", v)
}
//for 传统的元素遍历方法
for i := 0; i < len(summer); i++ {
fmt.Println("summer[", i, "] =", summer[i])
}
- 动态增加元素
切片比数组更强大之处在于支持动态增加元素,甚至可以在容量不足的情况下自动扩容。在切片类型中,元素个数和实际可分配的存储空间是两个不同的值,元素的个数即切片的实际长度,而可分配的存储空间就是切片的容量。
Go 语言内置的 cap() 函数和 len() 函数来获取某个切片的容量和实际长度
//定义
var oldSlice = make([]int, 5, 10)
//打印
fmt.Println("len(oldSlice):", len(oldSlice))
fmt.Println("cap(oldSlice):", cap(oldSlice))
通过 append() 函数向切片追加新元素
//新切片赋值给 newSlice,此时 newSlice 的长度是 8,容量是 10
newSlice := append(oldSlice, 1, 2, 3)
//值
[0 0 0 0 0 1 2 3]
- 内容复制
Go 语言的另一个内置函数 copy(),用于将元素从一个数组切片复制到另一个数组切片。如果加入的两个数组切片不一样大,就会按其中较小的那个数组切片的元素个数进行复制
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
// 复制 slice1 到 slice 2
copy(slice2, slice1) // 只会复制 slice1 的前3个元素到 slice2 中
// 复制 slice2 到 slice 1
copy(slice1, slice2) // 只会复制 slice2 的 3 个元素到 slice1 的前 3 个位置
- 动态删除元素
切片除了支持动态增加元素之外,还可以动态删除元素,在切片中动态删除元素可以通过多种方式实现(其实是通过切片实现的「伪删除」)
slice3 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 删除 slice3 尾部5个元素
slice3 = slice3[:len(slice3) - 5]
// 删除 slice3 头部 5 个元素
slice3 = slice3[5:]
通过上述介绍的 append 函数和 copy 函数实现切片元素的「删除」
slice3 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
//
slice4 := append(slice3[:0], slice3[3:]...) // 删除开头三个元素
slice5 := append(slice3[:1], slice3[4:]...) // 删除中间三个元素
slice6 := append(slice3[:0], slice3[:7]...) // 删除最后三个元素
slice7 := slice3[:copy(slice3, slice3[3:])] // 删除开头前三个元素
字典(map)
字典,其实就是存储键值对映射关系的集合,只不过对于强类型的 Go 语言来说,与 PHP 关联数组的不同之处在于需要在声明时指定键和值的类型,此外 Go 字典是个无序集合,底层不会像 PHP 那样按照元素添加顺序维护元素的存储顺序。
- 字典声明
//定义
var maps map[int]string
//初始化
maps = map[int]string{
0:"a",
1:"b",
2:"c",
}
//读取map
v,ok:=maps[2]
if ok {
fmt.println(v)
}else{
fmt.println("Not found!")
}
//省略写法
mapss := map[int]string{
1:"Hi",
2:"How",
3:"Are",
4:"You",
}
//make创建字典
var mapsss = make(map[string]int)
//元素赋值
mapsss["a"]=0 //类似于PHP的关联数组
mapsss["b"]=1
//也可以选择是否在创建时指定该字典的初始存储能力(超出会自动扩容)
testMap = make(map[string]int, 100)
- 字典初始化
可以通过先声明再初始化的方式进行初始化,就像上面示例代码做的那样,也可以通过 := 将声明和初始化合并为一条语句
//第一种
var maps map[int]string
maps = map[int]string{
0:"a",
1:"b",
2:"c",
}
//第二种
mapss := map[int]string{
1:"Hi",
2:"How",
3:"Are",
4:"You",
}
//第三种
var mapsss = make(map[string]int)
mapsss["a"]=0
mapsss["b"]=1
- 元素赋值
和 PHP 关联数组的赋值操作一致
mapsss["b"] = 4
- 查找元素
Go 语言中,字典的查找功能设计得比较精巧,要从字典中查找一个特定的键对应的值
v,ok := mapsss["c"]
if ok != true{
fmt.println("Not Found!")
}
- 删除元素
Go 语言提供了一个内置函数 delete(),用于删除容器内的元素,我们可以通过这个函数来实现字典元素的删除
delete(mapsss,"c")
//上面的代码将会从 mapsss中删除键为「c」的键值对。如果「c」这个键不存在或者字典尚未初始化,这个调用也不会有什么副作用
php也有类似的语句 unset()
unset($arr[3]);
- 字典遍历
可以像遍历数据那样对字段类型数据进行遍历
// range
for v,k := range mapss{
fmt.println(k,v)
}
php也有类似的语句 foreach
foreach(mapss as $key=>$value){
echo $key.'='.$value;
}
- 字典排序
Go 语言的字典不同于 PHP 的关联数组,是一个无序集合,如果你想要对字典进行排序,可以通过分别为字典的键和值创建切片,然后通过对切片进行排序来实现
keys := make([]string, 0)
for k, _ := range mpass{
keys = append(keys, k)
}
sort.Strings(keys) // 对键进行排序
fmt.Println("Sorted map by key:")
for _, k := range keys {
fmt.Println(k, mpass[k])
}
通道(chan)
- 通道声明和初始化
可以通过 chan 类型关键字来声明通道类型变量
与其他数据类型不同,通道类型变量除了声明通道类型本身外,还要声明通道中传递数据的类型,比如这里我们指定这个数据类型为 int
var ch chan int
#我们还可以通过如下方式声明通道数组、切片、字典,以下声明方式表示 chs 中的元素都是 chan int 类型的通道
var chs [10]chan int
var chs []chan int
var chs map[string]chan int
#不过,实际编码时,我们更多使用的是下面这种快捷方式同时声明和初始化通道类型
ch := make(chan int)
#在 Go 语言中,通道也是引用类型(和切片、字典一样),所以可以通过 make 函数进行初始化,在通过 make 函数初始化通道时,还可以传递第二个参数,表示通道的容量
ch := make(chan int, 10)
非缓冲通道
make(chan int),第二个参数是可选的,用于指定通道最多可以缓存多少个元素,默认值是 0,此时通道可以被称作非缓冲通道
缓冲通道
make(chan int,10),当缓存值大于 0 时,通道可以称作缓冲通道,即使通道元素没有被接收,也可以继续往里面发送元素,直到超过缓冲值,显然设置这个缓冲值可以提高通道的操作效率
#只是切片中的元素类型是通道,这个时候第二个参数是切片的初始容量,而不是通道的
chs := make([]chan int, 10)
- 通道操作符
通道类型变量只支持发送和接收操作,即往通道中写入数据和从通道中读取数据,对应的操作符都是 <-,我们判断是发送还是接收操作的依据是通道类型变量位于 <- 左侧还是右侧,位于左侧是发送操作,位于右侧是接收操作
ch <- 1 // 往通道中写入数据 1
x := <-ch // 从通道中读取数据并赋值给变量
- 使用缓冲通道提升性能
当然,上面这种情况发生在非缓冲通道中,对于缓冲通道,情况略有不同,假设 ch 是通过 make(chan int, 10) 进行初始化的通道,则其缓冲区大小是 10,这意味着,在没有被任何其他协程接收的情况下,我们可以一直往 ch 通道中写入 10 个数据,超过 10 个数据才会阻塞当前协程,直到通道被其他协程读取,显然,合理设置缓冲区可以提高通道的操作效率,尤其是在需要持续传输大量数据的场景
package main
import (
"fmt"
"time"
)
func test(ch chan int) {
#并且在子协程中发送数据到通道
for i := 0; i < 100; i++ {
ch <- i
}
#子协程执行完毕后,调用 close(ch) 显式关闭通道,这一行不能漏掉,否则主协程不知道子协程什么时候执行完毕
close(ch)
}
func main() {
start := time.Now()
#主协程中初始化了一个带缓冲的通道,缓冲大小是 20,然后将其传递到子协程
ch := make(chan int, 20)
go test(ch)
#从一个空的通道接收数据会报运行时错误(死锁)
#回到主协程,我们通过 i := range ch 循环从通道中读取数据,并将其打印出来
for i := range ch {
fmt.Println("接收到的数据:", i)
}
end := time.Now()
consume := end.Sub(start).Seconds()
fmt.Println("程序执行耗时(s):", consume)
}
- 双向通道
既可以往管道发送数据,也可以从管道接收数据
- 单向通道
限制只能往管道发送数据,或者只能从管道接收数据
通道本身还是要支持读写的,如果某个通道只支持写入操作,那么即便数据写进去了,不能被读取也毫无意义,同理,如果某个通道只支持读取操作,不能写入数据,那么通道永远是空的,从一个空的通道读取数据会导致协程的阻塞,无法执行后续代码
因此,Go 语言支持的单向管道,实际上是在使用层面对通道进行限制,而不是语法层面:即我们在某个协程中只能对通道进行写入操作,而在另一个协程中只能对该通道进行读取操作。从这个层面来说,单向通道的作用是约束在生产协程中只能发送数据到通道,而在消费协程中只能从通道接收数据,从而让代码遵循「最小权限原则」,避免误操作和通道使用的混乱,让代码更加稳健。
#当我们将一个通道类型变量传递到一个函数时(通常是在另外一个协程中执行),如果这个函数只能发送数据到通道,可以通过如下将其指定为单向只写通道(发送通道)
func test(ch chan<- int)
//test 函数中只能写入 int 类型数据到通道 ch
#我们将一个通道类型变量传递到一个只允许从该通道读取数据的函数,可以通过如下方式将通道指定为单向只读通道(接收通道)
func test(ch <-chan int)
单向通道的初始化和双向通道一样:
ch1 := make(chan int)
ch2 := make(chan<- int) //只能写入
ch3 := make(<-chan int) //只能读取
我们可以通过单向通道来约束上面的示例代码中子协程对通道的单向写入操作
package main
import (
"fmt"
"time"
)
#约束通道只能写入
func test(ch chan<- int) {
for i := 0; i < 100; i++ {
ch <- i
}
close(ch)
}
func main() {
start := time.Now()
ch := make(chan int, 20)
go test(ch)
for i := range ch {
fmt.Println("接收到的数据:", i)
}
end := time.Now()
consume := end.Sub(start).Seconds()
fmt.Println("程序执行耗时(s):", consume)
}
我们也可以定义一个返回值类型为单向只读通道的函数,以便得到该返回值的代码只能从通道中接收数据
func test() <-chan int {
ch := make(chan int, 20)
for i := 0; i < 100; i++ {
ch <- i
}
close(ch)
return ch
}
显然,合理使用单向通道,可以有效约束不同业务对通道的操作,避免越权使用和滥用,此外,也提高了代码的可读性,一看函数参数就可以判断出业务对通道的操作类型
流程控制
条件语句
对应的关键字有 if、else 和 else if
//if
if condition {
}
//if else
if condition {
}else{
}
//if else if
if condition {
}else if condition {
}else {
}
//在 if 之后,条件语句之前,可以添加变量初始化语句,使用 ; 间隔。如下:
if score := 100; score > 90 {
}
分支语句
对应的关键字有 switch、case 和 select
- switch
//go语言中,没有break跳出
switch condition {
case condition1:
...
case condition2:
...
default:
...
}
//分数评级案例
score := 100
switch {
case score >= 90:
fmt.Println("Grade: A")
case score >= 80 && score < 90:
fmt.Println("Grade: B")
case score >= 70 && score < 80:
fmt.Println("Grade: C")
case score >= 60 && score < 70:
fmt.Println("Grade: D")
default:
fmt.Println("Grade: F")
}
需要注意以下几点:
- 和条件语句一样,左花括号 { 必须与 switch 处于同一行;
- 单个 case 中,可以出现多个结果选项(通过逗号分隔);
- 与其它语言不同,Go 语言不需要用 break 来明确退出一个 case;
- 只有在 case 中明确添加 fallthrough 关键字,才会继续执行紧跟的下一个 case;
- 可以不设定 switch 之后的条件表达式,在这种情况下,整个 switch 结构与多个 if…else… 的逻辑作用等同。
- select
Go 语言还支持通过 select 分支语句选择指定分支代码执行,select 语句和之前介绍的 switch 语句语法结构类似,不同之处在于 select 的每个 case 语句必须是一个通道操作,要么是发送数据到通道,要么是从通道接收数据,此外 select 语句也支持 default 分支
select {
case <-chan1:
// 如果从 chan1 通道成功接收数据,则执行该分支代码
case chan2 <- 1:
// 如果成功向 chan2 通道成功发送数据,则执行该分支代码
default:
// 如果上面都没有成功,则进入 default 分支处理流程
}
注:Go 语言的 select 语句借鉴自 Unix 的 select() 函数,在 Unix 中,可以通过调用 select() 函数来监控一系列的文件句柄,一旦其中一个文件句柄发生了 IO 动作,该 select() 调用就会被返回(C 语言中就是这么做的),后来该机制也被用于实现高并发的 Socket 服务器程序。Go 语言直接在语言级别支持 select 关键字,用于处理并发编程中通道之间异步 IO 通信问题。
循环语句
对应的关键字有 for 和 range
- for
Go 语言中的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构
sum := 0
for i := 1; i <= 100; i++ {
sum += i
}
fmt.Println(sum)
- 无限循环
通过不带循环条件的 for 语句实现
sum := 0
for {
sum ++
if sum > 100 {
break
}
}
- 多重赋值
for 循环条件表达式中也支持多重赋值
a := []int{1, 2, 3, 4, 5, 6}
for i, j := 0, len(a) – 1; i < j; i, j = i + 1, j – 1 {
a[i], a[j] = a[j], a[i]
}
fmt.Println(a)
//上述代码的打印结果是 [6 5 4 3 2 1]
- 嵌套循环
通过嵌套循环对多维数组进行遍历
参考九九乘法表
- for-range
Go 语言还支持通过 for-range 结构对其进行循环遍历
for k, v := range a {
fmt.Println(k, v)
}
- 基于条件判断进行循环
sum := 0
i := 0
for i < 100 {
i++
sum += i
}
fmt.Println(sum)
注意以下几点
- 和条件语句、分支语句一样,左花括号 { 必须与 for 处于同一行;
- 不支持 whie 和 do-while 结构的循环语句;
- 可以通过 for-range 结构对可迭代集合进行遍历;
- 支持基于条件判断进行循环迭代;
- 与 PHP 一样,都允许在循环条件中定义和初始化变量,且支持多重赋值;
- Go 语言的 for 循环同样支持 continue 和 break 来控制循环,但是它提供了一个更高级的 break,可以选择中断哪一个循环。如下:
for j := 0; j < 5; j++ {
for i := 0; i < 10; i++ {
if i > 5 {
break JLoop
}
fmt.Println(i)
}
}
JLoop:
// ...
跳转语句
对应的关键字有 goto、continue、break、标签
- break
break 的默认作用范围是该语句所在的最内部的循环体
arr := [][]int{{1,2,3},{4,5,6},{7,8,9}}
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
break
}
fmt.Println(num)
}
}
- continue
continue 则用于忽略剩余的循环体而直接进入下一次循环的过程
arr := [][]int{{1,2,3},{4,5,6},{7,8,9}}
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 2 {
continue
}
fmt.Println(num)
}
}
- 标签
Go 语言的 break 和 contine 与 PHP 的不同之处在于支持与标签结合跳转到指定的标签语句,从而改变这两个语句的默认跳转逻辑,标签语句通过标签+「:」进行声明
arr := [][]int{{1,2,3},{4,5,6},{7,8,9}}
//标签 ITERATOR1
ITERATOR1:
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
break ITERATOR1 //条件满足 则跳转到 标签 ITERATOR1位置
}
fmt.Println(num)
}
}
- goto
goto 语句被多数语言学者所反对,告诫大家不要使用,因为很容易造成代码逻辑混乱,容易导致不易发现的 bug。但 Go 语言仍然支持 goto 关键字,goto 语句的语义非常简单,就是跳转到本函数内的某个标签
arr := [][]int{{1,2,3},{4,5,6},{7,8,9}}
for i := 0; i < 3; i++ {
for j := 0; j < 3; j++ {
num := arr[i][j]
if j > 1 {
goto EXIT //跳出循环,到标签位置 EXIT
}
fmt.Println(num)
}
}
//标签
EXIT:
fmt.Println("Exit.")
//所以上述代码的输出是:1,2,Exit.
面向过程
函数定义和调用
在 Go 语言中,函数的基本组成为:关键字 func、函数名、参数列表、返回值、函数体和返回语句,作为强类型语言,无论是参数还是返回值,在定义函数时,都要声明其类型。
//主函数
func main(){
//函数调用,如果再同一个包,直接调用即可。如果不再用一个包,需要载入包,才能调用
fmt.println(add(1,2))
//打印结果:3
}
//示例
func add(a, b int) int { //关键字func 函数名 参数列表,参数类型 返回结果,返回结果类型
return a + b //返回结果
}
在跨包调用时,只有首字母大写的函数才可以被调用,这个涉及到包的可见性
按值传参和引用传参
- 值传参
Go 语言默认使用按值传参来传递参数,也就是传递参数的一个副本,函数接收该参数后,可能在处理过程中对参数值做调整,但这不会影响原来的变量值
示例:
func add(a, b int) int {
//a,b参数是副本,对其修改不会影响到原有的变量值 x,y
a *= 2
b *= 3
return a + b
}
func main() {
x, y := 1, 2
z := add(x, y)
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
//打印结果 1 2 8
}
当我们把 x、y 变量作为参数传递到 add 函数时,这两个变量会拷贝出一个副本赋值给 a、b 变量作为参数,因此,在 add 函数中调整 a、b 变量的值并不会影响原变量 x、y 的值
- 引用传参
实现在函数中修改参数值可以同时修改原变量,此时传递给函数的参数是一个指针,而指针代表的是原变量的地址,修改指针指向的值即修改变量地址中存储的值,所以原变量的值也会被修改(这种情况下,传递的是变量地址值的拷贝,所以从本质上来说还是按值传参)
//*a,*b指向x,y的值
func add(a, b *int) int {
//a,b变量的值修改,直接作用于下,y
*a *= 2
*b *= 3
return *a + *b
}
func main() {
x, y := 1, 2
//传递x,y的内存地址,
z := add(&x, &y)
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
//打印结果 2 6 8
}
- 多返回值及返回值命名
Go 语言函数与其他编程语言一大不同之处在于支持多返回值,这在处理程序出错的时候非常有用。
#多返回值
func add1(a, b *int) (int, error) {
if (*a < 0 || *b < 0) {
err = errors.New("只支持非负整数相加")
return
}
*a *= 2
*b *= 3
c = *a + *b
return
}
#返回值命名
func add2(a, b *int) (c int, err error) {
if (*a < 0 || *b < 0) {
err = errors.New("只支持非负整数相加")
return
}
*a *= 2
*b *= 3
c = *a + *b
return
}
func main(){
x, y := -1, 2
z, err := add1(&x, &y)
if (err != nil) {
fmt.Println(err.Error())
return
}
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
}
这种机制避免了每次进行 return 操作时都要关注函数需要返回哪些返回值,为开发者节省了精力,尤其是在复杂的函数中。
变长参数
- 任意数量参数
Go 语言中的变长参数的用法,和 PHP 类似,只是把( … )作用到类型上,这样就可以约束变长参数的类型
func main(){
Args1([]int{1, 2, 3, 4, 5})
Args2(1, "1", [1]int{1}, true)
}
func Args1(number ...int){
for _,v := range number {
fmt.println(v)
}
}
- 任意类型的变长参数
指定变长参数类型为 interface{},空接口类型可以用于表示任意类型。
func Args2(args ...interface{}){
for _, arg := range args {
switch reflect.TypeOf(arg).Kind() {
case reflect.Int:
fmt.Println(arg, "is an int value.")
case reflect.String:
fmt.Printf("\"%s\" is a string value.\n", arg)
case reflect.Array:
fmt.Println(arg, "is an array type.")
default:
fmt.Println(arg, "is an unknown type.")
}
}
}
匿名函数(闭包)
Go 语言的匿名函数是一个闭包(Closure)
所谓闭包指的是引用了自由变量(未绑定到特定对象的变量,通常在匿名函数外定义)的函数,被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的上下文环境也不会被释放(比如传递到其他函数或对象中)。或者通俗点说,「闭」的意思是「封闭外部状态」,即使外部状态已经失效,闭包内部依然保留了一份从外部引用的变量。
闭包的价值在于可以作为函数对象或者匿名函数,对于类型系统而言,这意味着不仅要表示数据还要表示代码。支持闭包的多数语言都将函数作为第一类对象(firt-class object,有的地方也译作第一级对象,第一类公民等),就是说这些函数可以存储到变量中作为参数传递给其他函数,能够被函数动态创建和返回。
//定义匿名函数
fun := func(){ //通过把这个函数变量赋值给 fun,fun 就成为了一个闭包。
fmt.println("匿名函数")
}
//给匿名函数传参
funct:=func(a,b int){
fmt.Println(a + b)
}
//第三种写法
func(a,b int){
fmt.fmt.Println(a % b)
}(4,8) //这种写法相当于 直接调用,不需要通过变量调用
//引用
fun()
funct(1,6)
系统内置函数
Go 语言提供了一些不需要导入任何包就可以直接使用的内置函数。我们把这些内置函数做一个简单的分类
| 名称 | 说明 |
|---|---|
| close | 用于在管道通信中关闭一个管道 |
| len、cap len | 用于返回某个类型的长度(字符串、数组、切片、字典和管道),cap 则是容量的意思,用于返回某个类型的最大容量(只能用于数组、切片和管道) |
| new、make | new 和 make 均用于分配内存,new 用于值类型和用户自定义的类型(类),make 用于内置引用类型(切片、字典和管道)。它们在使用时将类型作为参数:new(type)、make(type)。new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的指针,也可以用于基本类型:v := new(int)。make(T) 返回类型 T 的初始化之后的值,所以 make 不仅分配内存地址还会初始化对应类型。 |
| copy、append | 分别用于切片的复制和动态添加元素 |
| panic、recover | 两者均用于错误处理机制 |
| print、println | 打印函数,在实际开发中建议使用 fmt 包 |
| complex、real、imag | 用于复数类型的创建和操作 |
递归函数与性能优化
- 递归
写递归函数时,这个递归一定要有终止条件,否则就会无限调用下去,直到内存溢出。所以我们可以归纳出递归函数的编写思路:抽象出递归模型(可以被复用到子问题的模式/公式),同时找到终止条件。
斐波那契数列求解:
//递归
func fibonacci(n int) int {
if n == 1 {
return 0
}
if n == 2 {
return 1
}
return fibonacci(n-1) + fibonacci(n-2)
}
func main(){
n := 9
start := time().Now()
//递归
num := fibonacci(n)
end := time().Now()
consume := end.Sub(start).Seconds()
fmt.Printf("The %dth number of fibonacci sequence is %d\n", n, num)
fmt.Println("用时:",consume)
}
递归函数是层层递归嵌套执行的,如果层级不深,比如上面这种,很快就会返回结果,但如果传入一个更大的序号,比如50,就会明显感觉到延迟
- 性能优化
通过缓存中间计算结果,减少重复递归次数,实现性能优化。
//定义长度为50的数组
const MAX = 50
var fibs [MAX]int
func fibonacci(n int) int {
if n == 1 {
return 0
}
if n == 2 {
return 1
}
//查找数组是否存有当前索引的值
index := n-1
if fibs[index]!=0{
return fibs[index]
}
num := fibonacci(n-1) + fibonacci(n-2)
//写入数组
fibs[index] = num
return num
}
func main(){
n := 9
start := time().Now()
num := fibonacci(n)
end := time().Now()
consume := end.Sub(start).Seconds()
fmt.Printf("The %dth number of fibonacci sequence is %d\n", n, num)
fmt.Println("用时:",consume)
}
面向对象
类
定义和初始化
Go 语言并没有沿袭传统面向对象编程中的诸多概念,比如类的继承、接口的实现、构造函数和析构函数、隐藏的 this 指针等,也没有 public、protected、private 之类的可见性修饰符。
没有 class、extends、implements 之类的关键字和相应的概念,而是借助结构体来实现类的声明
定义一个学生类
//类名 Student
type Student struct {
id uint //属性id 类型 uint
name string //属性name 类型 string
male bool //属性male 类型 bool
score float64 //属性score 类型 float64
}
Go 语言中也不支持构造函数、析构函数,取而代之地,可以通过定义形如 NewXXX 这样的全局函数(首字母大写)作为类的初始化函数
初始化函数,在Go中首字母大写同时表示公共方法,类似于public,小写表示不能再类外使用,类似于private、protected
在这个函数中,我们通过传入的属性字段对 Student 类进行初始化并返回一个指向该类的指针,除此之外,还可以初始化指定字段
#在 Go 语言中,未进行显式初始
func NewStudent(id uint, name string, score float64) *Student {
return &Student{id: id, name:name, score:score}
}
#然后我们可以在 main() 函数中调用这个 NewStudent 函数对 Student 类进行初始化
func main(){
student := NewStudent(1, "明哥哥", 100)
fmt.Println(student)
}
//打印结果 &{1 明哥哥 false 100}
化的变量都会被初始化为该类型的零值,例如 bool 类型的零值为 false,int 类型的零值为 0,string 类型的零值为空字符串,float 类型的零值为 0.0。
成员方法
由于 Go 语言不支持 class 这样的代码块,要为 Go 类添加成员方法,需要在 func 和方法名之间添加方法所属的类型声明(有的地方将其称之为接收者声明)
#以 Student 类为例,要为其添加返回 name 值的方法
func (stu Student) GetName() name string{
return stu.name
}
#上述方法是一个只读方法,如果我们要在外部通过 Student 类暴露的方法设置 name 值
func (stu *Student) SetName(name string){ //Student 类型设置成了指针类型
stu.name = name
return true
}
func main(){
stu := NewStudent(1, "明哥哥", 100)
fmt.Println("Name:", stu.GetName())
stu.SetName("啊哈")
fmt.Println("Name:", stu.GetName())
}
Go 语言面向对象编程不像 PHP、Java 那样支持隐式的 this 指针,所有的东西都是显式声明的,在 GetName 方法中,由于不需要对类的成员变量进行修改,所以不需要传入指针,而 SetName 方法需要在函数内部修改成员变量的值,并且作用到该函数作用域以外,所以需要传入指针类型
结构体是值类型,不是引用类型,所以需要显式传入指针
PHP、Java 支持默认调用类的 toString 方法以字符串格式打印类的实例,Go 语言也有类似的机制,只不过这个方法名是 String
以上面这个 Student 类型为例,我们为其编写 String 方法如下:
func (s Student) String() string {
return fmt.Sprintf("{id: %d, name: %s, male: %t, score: %f}",
s.id, s.name, s.male, s.score)
}
#然后我们可以在 main 方法中这样调用来打印类实例:
func main(){
student := NewStudent(1, "明哥哥", 100)
fmt.Println(student)
}
#无需显式调用 String 方法,Go 语言会自动调用该方法来打印,结果如下:
{id: 1, name: 明哥哥, male: false, score: 100.000000}
为基本数据类型添加成员方法
在 Go 语言中,你可以给任意类型(包括基本类型,但不包括指针类型)添加成员方法,但是如果是基本类型的话,需要借助 type 关键字对类型进行再定义
type Integer int
func (a Integer) Equal(b Integer) bool {
return a == b
}
我们定义了一个新类型 Integer,它和 int 没有本质不同,只是它为内置的 int 类型增加了个新方法 Equal()。 这样一来,就可以让基本类型的整型像一个普通的类一样使用
func main() {
var a Integer = 2
if a.Equal(2) {
fmt.Println(a, "is equal to 2")
}
}
继承
Go 语言不是像 PHP 等传统面向编程实现那样通过 extends 关键字来显式定义子类与父类之间的继承关系,而是通过组合方式实现类似功能,显式定义继承关系的弊端有两个:一个是导致类的层级复杂,另一个是影响了类的扩展性,设计模式里面推荐的也是通过组合来替代继承提高类的扩展性。
例子:
//定义Animal类
type Animal struct {
name string
}
func (a Animal) Call() string {
return "旺旺"
}
//组合
type Dog struct{
Animal
}
func (d Dog) FavorFood() string {
return "骨头"
}
//初始化
func main(){
animal := Animal{"狗"}
dog := Dog{animal}
fmt.Println("叫声:", dog.Call(), "喜爱的食物:", dog.FavorFood())
}
我们在 Dog 结构体中,引入了 Animal 这个类型,这样一来,我们就可以在 Dog 类中访问所有 Animal 类型包含的属性和方法(如果两个类不在同一个包中,只能访问父类中首字母大写的公共属性和方法),比如这里我们可以在 Dog 实例上直接访问 Animal 类的 Call方法。
方法重写
还可以通过在子类中定义同名方法来覆盖父类的实现
//定义Animal类
type Animal struct {
name string
}
func (a Animal) Call() string {
return "旺旺"
}
//组合
type Dog struct{
Animal
}
func (d Dog) FavorFood() string {
return "骨头"
}
//重写Animal 的方法Call
func (d Dog) Call()string {
return "人旺财旺身体旺,旺上加旺"
}
//初始化
func main(){
animal := Animal{"狗"}
dog := Dog{animal}
fmt.Println("叫声:", dog.Call(), "喜爱的食物:", dog.FavorFood())
}
//打印的结果 叫声: 人旺财旺身体旺,旺上加旺 喜爱的食物: 骨头
在 Go 语言中,你还可以以指针方式继承某个类型的属性和方法
type Dog struct {
*Animal // 指针
}
#这种情况下,除了传入 animal 实例的时候要传入指针引用之外,其它调用无需修改
func main(){
animal := Animal{"狗"}
dog := Dog{&animal} // &引用
fmt.Println("叫声:", dog.Call(), "喜爱的食物:", dog.FavorFood())
}
结构体是值类型,如果传入值字面量的话,实际上传入的是结构体值的副本,对内存耗费更大,所以传入指针性能更好。
Go 语言没有类似 PHP 的 parent 关键字,我们可以把组合进来的类型当做子类的一个匿名字段,直接通过引用类型名调用父类被重写的方法或属性
fmt.Println("叫声:", dog.Animal.Call(), "喜爱的食物:", dog.FavorFood())
#也可以将其作为一个类型为其指定一个属性名称来调用对应的方法和属性
type Dog struct {
name string
animal *Animal
}
fmt.Println(dog.name, "叫声:", dog.animal.Call())
属性和方法的可见性
Go 语言的自定义类来说,属性和方法的可见性根据其首字母大小写来决定,如果属性名或方法名首字母大写,则可以在其他包中直接访问这些属性和方法,否则只能在包内访问,所以 Go 语言中的可见性都是包一级的,而不是类一级的
接口
定义与实现
接口在 Go 语言中有着至关重要的地位,如果说 goroutine 和 channel 是支撑起 Go 语言并发模型的基石,那么接口就是 Go 语言整个类型系统的基石
Go 语言通过关键字 type 和 interface 来声明接口,花括号内包含都是待实现的方法集合
Go 语言中,接口实现和类的继承一样,并没有通过关键字显示声明实现了哪个接口,一个类只要实现了某个接口要求的所有方法,我们就说这个类实现了该接口
//接口
type FileInterface interface{
Read(buf []byte) (n int, err error)
Write(buf []byte) (n int, err error)
Seek(off int64, whence int) (pos int64, err error)
Close() error
}
//File实现FileInterface 接口所有方法
type File struct{
...
}
func (f File) Read(buf []byte)(n int,err error){
...
}
func (f *File) Write(buf []byte)(n int,err error){
...
}
func (f File) Seek(off int64, whence int) (pos int64, err error){
...
}
func (f File) Close() error{
...
}
我们把 Go 语言的这种接口称作非侵入式接口,因为类与接口的实现关系不是通过显式声明,而是系统根据两者的方法集合进行判断。
这样做有两个好处:
- 其一,Go 语言的标准库不需要绘制类库的继承/实现树图,在 Go 语言中,类的继承树并无意义,你只需要知道这个类实现了哪些方法,每个方法是干什么的就足够了。
- 其二,实现类的时候,只需要关心自己应该提供哪些方法即可,不用再纠结接口需要拆得多细才合理,也不需要为了实现某个接口而引入接口所在的包,接口由使用方按需定义,不用事先设计,也不用考虑之前是否有其他模块定义过类似接口。
赋值实现接口与类的映射
Go 语言的接口不支持直接实例化,只能通过实现类实现接口声明的所有方法,不过不同之处在于 Go 语言接口支持赋值操作,从而快速实现接口与实现类的映射
接口赋值在 Go 语言中分为如下两种情况:
- 将实现接口的对象实例赋值给接口;
- 将一个接口赋值给另一个接口。
只要两个接口拥有相同的方法列表(与顺序无关),那么它们就是等同的,可以相互赋值
type Number1 interface {
Equal(i int) bool
LessThan(i int) bool
MoreThan(i int) bool
}
type Number2 interface {
Equal(i int) bool
MoreThan(i int) bool
LessThan(i int) bool
}
// Number 实现了上面的接口
type Number int;
func (n Number) Equal(i int) bool {
return int(n) == i
}
func (n Number) LessThan(i int) bool {
return int(n) < i
}
func (n Number) MoreThan(i int) bool {
return int(n) > i
}
//两者都定义五个相同的方法,只是顺序不同而已。在 Go 语言中,这两个接口实际上并无区别。
func main(){
var num1 Number = 1
var num2 Number1 = num1
var num3 Number2 = num2
}
接口赋值并不要求两个接口完全等价(方法完全相同)。如果接口 A 的方法列表是接口 B 的方法列表的子集,那么接口 B 可以赋值给接口 A
#假设 Number2 接口定义
type Number2 interface {
Equal(i int) bool
MoreThan(i int) bool
LessThan(i int) bool
Add(i int)
}
#Number 类
func (n *Number) Add(i int) {
*n = *n + Number(i)
}
#接口赋值语句改写如下即可
func main(){
var num1 Number = 1
var num2 Number2 = &num1 // 指针Number类实现了所有方法
var num3 Number1 = num2 // 值Number类没有 指针方法 *Add()
}
接口类型查询及转化
以上篇教程介绍的 Number 类、Number1 和 Number2 接口为例,在 Go 语言中,要查询接口 Number2 指向的对象实例 num2 是否属于接口 Number1
var num1 Number = 1;
var num2 Number2 = &num1;
if num3, ok := num2.(Number1); ok {
fmt.Println(num3.Equal(1))
}
我们通过 num2.(Number1) 这个表达式判断 num2 是否是 Number1 的实例,如果是,则返回转化为 Number1 接口类型的实例 num3,ok 值为 true,然后执行 if 语句块中的代码;否则 ok 值为 false,不执行 if 语句块中的代码。所以 num2.(Number1) 做了两件事情,一个是做接口查询,将查询结果作为第二个返回值,另一个是对类型进行转化,转化后的类型是圆括号中对应的查询接口。
需要注意的是,接口查询是否成功要在运行期才能够确定,它不像接口赋值,编译器只需要通过静态类型检查即可判断赋值是否可行
类型查询和转化
Go 语言的类型查询实现语法和接口查询一样,我们以前面类的继承教程中定义的 Animal、Dog 类为例
由于接口/类型查询语法左侧的变量类型必须是接口类型,所以我们需要在包中新增一个 IAnimal 接口(首字母大写才能在包外可见,这一点和类名、方法名、变量名、属性字段名一样)
type IAnimal interface {
Call() string
FavorFood() string
}
var animal = Animal{"小狗"}
var ianimal IAnimal = Dog{animal}
if dog, ok := ianimal.(Dog); ok {
fmt.Println(dog.Call())
}
需要注意的是,在 Go 语言类型查询时,归属于子类的实例并不归属于父类,因为类与类之间的「继承」是通过组合实现的,并不是 PHP/Java 语言中的那种父子继承关系,比如上述代码中我们把 ianimal.(Dog) 替换成 ianimal.(Animal) 则查询结果 ok 值为 false。
类型查询并不经常使用,它更多是个补充,需要配合接口查询使用,此外,还可以利用反射进行类型查询
#reflect.TypeOf()
fmt.Println(reflect.TypeOf(ianimal));
#打印的类型值都是 Dog
对于基本数据类型,比如 int、string、bool 这些,不必通过反射,直接通过 type 关键字即可获取对应的类型值
fmt.println(arg.(type))
Go 语言标准库中的 Println() 函数底层就是基于类似的类型查询对传入参数值进行打印的。
接口组合实现接口继承
Go 语言也支持类似的「接口继承」,但是由于不支持 extends 关键字,所以其实现和类的继承一样,是通过组合来完成的
type A interface{
Foo()
}
//组合
type B interface{
A
Bar()
}
//定义类
type T struct{}
//定义方法
func (t T) Foo(){
fmt.Println("interface A.")
}
func (t T) Bar(){
fmt.Println("interface B.")
}
//接口赋值
var t T = T{} //实现了接口B、A
var a B = t //如果只实现了接口A 没有实现接口B,那么这就会报错
a.Foo()
a.Bar()
空接口
在 Go 语言中类型与接口的实现关系是通过类所实现的方法来在编译期推断出来的,如果我们定义一个空接口的话,那么显然所有的类型都实现了这个接口,然后我们就可以通过这个空接口来指向任意类型,从而实现类似 Java 中 Object 类所承担的功能,而且显然 Go 的空接口实现更加简洁,通过一个简单的 interface{} 字面量即可完成,并且可以声明基本类型,而同样的功能在 Java 中还要通过装箱转化才可以
#基本类型
var v1 interface{} = 1 // 将 int 类型赋值给 interface{}
var v2 interface{} = "明哥哥" // 将 string 类型赋值给 interface{}
var v3 interface{} = true // 将 bool 类型赋值给 interface{}
#复合类型
var v4 interface{} = &v2 // 将 *interface{} 类型(指针)赋值给 interface{}
var v5 interface{} = []int{1, 2, 3} // 将切片类型赋值给 interface{}
var v6 interface{} = struct{ // 将自定义类型赋值给 interface{}
id int
name string
}{1, "明哥哥"}
#变长参数,使用空接口表示支持所有数据类型
func GetParam(...interface{}){}
空接口 interface{} 最典型的使用场景就是用于声明函数支持任意类型的参数,比如 Go 语言标准库 fmt 中的打印函数就是这样实现的:
func Printf(fmt string, args ...interface{})
func Println(args ...interface{})
另外,有的时候你可能会看到空的结构体类型定义:struct{},表示没有任何属性和方法的空类,该类型的实例值只有一个,那就是 struct{}{},这个值在 Go 程序中永远只会存一份,并且占据的内存空间是 0,当我们在并发编程中,将通道(channel)作为传递简单信号的介质时,使用 struct{} 类型来声明最好不过。
错误和异常处理
Error
- 错误处理机制
Go 语言错误及异常处理机制要简单明了的多,不需要学习了解那么多复杂的概念、函数和类型,Go 语言为错误处理定义了一个标准模式,即 error 接口,该接口的定义非常简单
type error interface {
Error() string
}
于大多数函数或类方法,如果要返回错误,基本都可以定义成如下模式 —— 将错误类型作为第二个参数返回:
func errs(n int) (n int,err error){
// 自定义错误信息
err = errors.New("错误")
return
}
func main(){
n, err := Foo(0)
if err != nil {
// 错误处理
} else {
// 使用返回值 n
}
}
- 错误消息返回及处理
func add(a, b *int) (c int, err error) {
if (*a < 0 || *b < 0) {
err = errors.New("只支持非负整数相加")
return
}
*a *= 2
*b *= 3
c = *a + *b
return
}
func main(){
x, y := 1, 2
z, err := add(&x, &y)
if err != nil {
fmt.Println(err)
} else {
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
}
}
注意到我们在打印错误信息时,直接传入了 err 对象实例,因为 Go 底层会自动调用 err 实例上的 Error() 方法返回错误信息并将其打印出来,就像普通类的 String() 方法一样
此外我们还可以通过 fmt.Errorf() 格式化方法返回 error 类型错误,其底层调用的其实也是 errors.New 方法:
func Errorf(format string, a ...interface{}) error {
return errors.New(Sprintf(format, a...))
}
Defer
defer表示最后执行。当程序体执行完,最后才会执行defer。
关键字defer,当执行到该条语句时,函数和参数表达式得到计算,但直到包含该defer语句的函数执行完毕时,defer后的函数才会被执行,不论包含defer语句的函数是通过return正常结束,还是由于panic导致的异常结束。你可以在一个函数中执行多条defer语句。
defer语句经常被用于处理成对的操作,如打开、关闭、连接、断开连接、加锁、释放锁。通过defer机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。
一个函数/方法中可以存在多个 defer 语句,defer 语句的调用顺序遵循先进后出的原则,即最后一个 defer 语句将最先被执行,相当于「栈」结构,如果在循环语句中包含了 defer 语句,则对应的 defer 语句执行顺序依然符合先进后出的规则。
由于 defer 语句的执行时机和调用顺序,所以我们要尽量在函数/方法的前面定义它们,以免在后面执行时漏掉,尤其是运行时抛出错误会中断后面代码的执行,也就感知不到后面的 defer 语句。
func main(){
#defer下面的程序体执行完,最后执行defer打印sum。
defer fmt.println(sum)
sum :=0
for i:=0;i<10;i++{
sum = i
}
}
Panic和Recover
- panic
Go的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等。这些运行时错误会引起painc异常。
除了由 Go 语言底层抛出 panic,我们还可以在代码中显式抛出 panic,以便对错误和异常信息进行自定义。
func main(){
TestPanic()
fmt.println("Welcome")
}
func TestPanic() {
for i := 0; i < 10; i++ {
if i%2 == 0 {
//报出错误或异常,并中断程序
panic("能被2整除")
}
}
}
由于panic会引起程序的崩溃,因此panic一般用于严重错误,如程序内部的逻辑不一致
- recover
我们还可以通过 recover() 函数对 panic 进行捕获和处理,从而避免程序崩溃然后直接退出,实现类似 PHP 中 try…catch…finally 的功能,由于执行到抛出 panic 的问题代码时,会中断后续其他代码的执行,所以,显然这个 panic 的捕获和其他代码的恢复执行需要放到 defer 语句中完成。
func main(){
TestPanic()
fmt.println("Welcome")
}
func TestPanic() {
//捕获错误异常
defer func() {
//捕获异常,避免程序崩溃然后直接退出
if err := recover(); err != nil {
//捕获到的错误信息: panic("能被2整除)
fmt.Println(err)
}
}()
for i := 0; i < 10; i++ {
if i%2 == 0 {
//报出错误或异常,并中断程序
panic("能被2整除")
}
}
}
如果没有通过 recover() 函数捕获 panic 的话,程序会直接崩溃退出,并打印错误和堆栈信息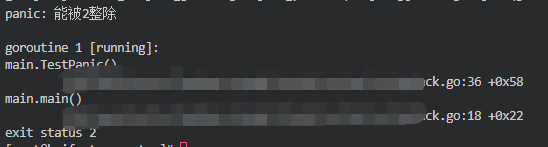
当程序运行过程中抛出 panic 时我们可以通过 recover() 函数对其进行捕获和处理,如果没有抛出则什么也不做,从而确保了代码的健壮性。
并发编程
Go 语言在语言级别支持协程,称之为 goroutine。Go 语言标准库提供的所有系统调用操作(当然也包括所有同步 IO 操作),都有协程的身影。协程间的切换管理不依赖于系统的线程和进程,也不依赖于 CPU 的核心数量,这让我们在 Go 语言中通过协程实现并发编程变得非常简单。
Go 语言的协程系统是基于「消息传递系统」实现的,在 Go 语言的编程哲学中,创始人 Rob Pike 推介「Don’t communicate by sharing memory, share memory by communicating(不要通过共享内存来通信,而应该通过通信来共享内存)」,这正是「消息传递系统」的精髓所在。Go 语言中的 goroutine 和用于传递协程间消息的 channel 一起,共同构筑了 Go 语言协程系统的基石。
协程
Go 语言的协程实现被称之为 goroutine,由 Go 运行时管理
go关键字
通过关键字 go 启用多个协程,然后在不同的协程中完成不同的子任务,这些用户在代码中创建和维护的协程本质上是用户级线程,Go 语言运行时会在底层通过调度器将用户级线程交给操作系统的系统级线程去处理,如果在运行过程中遇到某个 IO 操作而暂停运行,调度器会将用户级线程和系统级线程分离,以便让系统级线程去处理其他用户级线程,而当 IO 操作完成,需要恢复运行,调度器又会调度空闲的系统级线程来处理这个用户级线程,从而达到并发处理多个协程的目的
func add(a,b int){
fmt.Println(a+b)
}
func main(){
//关键字 go 定义协程
go add(1,2)
//并发执行示例
for i := 0; i < 10; i++ {
go add(1, i+2)
}
}
协程通信实现
- 共享内存
import (
"fmt"
"runtime"
"sync"
)
var counter int = 0
func add(a, b int, lock *sync.Mutex) {
c := a + b
//引入互斥锁,实现同步阻塞方式串行执行
lock.Lock()
counter++
fmt.Printf("%d: %d + %d = %d\n", counter, a, b, c)
lock.Unlock()
}
func main() {
start := time.Now()
//互斥锁
lock := &sync.Mutex{}
//并发
for i := 0; i < 10; i++ {
go add(1, i, lock)
}
for {
//避免 counter 值被污染,引入互斥锁
lock.Lock()
c := counter
lock.Unlock()
//让出cpu时间片
runtime.Gosched()
if c >= 10 {
break
}
}
end := time.Now()
consume := end.Sub(start).Seconds()
fmt.Println("程序执行耗时(s):", consume)
}
如果到处都要加锁、解锁,显然对开发者和维护者来说都是噩梦
Go 语言并发编程实践中,使用的都是基于消息传递的方式实现协程之间的通信。
- 通过 channel 进行消息传递
Go 语言推荐使用消息传递实现并发通信,这种消息通信机制被称为 channel,中文译作「通道」,可理解为传递消息的通道。
通道是 Go 语言在语言级别提供的协程通信方式,它是一种数据类型,本身是并发安全的,我们可以使用它在多个 goroutine 之间传递消息,而不必担心通道中的值被污染。
需要注意的是,通道是进程内的通信方式,因此通过通道传递对象的过程和调用函数时的参数传递行为一致,也可以传递指针。如果需要跨进程通信,建议通过分布式系统的方法来解决,比如使用 Socket 或者 HTTP 等通信协议,Go 语言对于网络方面也有非常完善的支持
func add(a,b int,ch chan int){
//管道写入
ch <- b
fmt.Println(a+b)
}
func main(){
chs := make([]chan int,10)
for i:=0;i<10;i++{
go add(1,i,chs[i])
}
//遍历管道
for _,ch:=range chs{
//读取
<-ch
}
}
//通道没有数据,不能被读取,这时主协程会被挂起,直到写入数据才会被激活
//通道写入数据,不能被读取,时主协程会被挂起,直到写入完数据才会被激活读取
//通道读取数据,不能写入,时主协程会被挂起,直到读取完才会被激活写入
首先定义了一个包含 10 个通道类型的切片 chs,并把切片中的每个通道分配给 10 个不同的协程。在每个协程的 add() 函数业务逻辑完成后,我们通过 ch <- 1 语句向对应的通道中发送一个数据。在所有的协程启动完成后,我们再通过 <-ch 语句从通道切片 chs 中依次接收数据(不对结果做任何处理,相当于写入通道的数据只是个标识而已,表示这个通道所属的协程逻辑执行完毕),直到所有通道数据接收完毕,然后打印主程序耗时并退出
同一时间同一个进程内的所有协程对某个通道只能执行发送或接收操作,两者不可能同时进行,这样就保证了并发的安全性,数据不可能被污染。
互斥锁
其他语言中主流的并发编程都是通过共享内存实现的,共享内存必然涉及并发过程中的共享数据冲突问题,而为了解决数据冲突问题,Go 语言沿袭了传统的并发编程解决方案 —— 锁机制,这些锁都位于 sync 包中。
一旦数据被多个线程共享,那么就很可能会产生争用和冲突的情况,这种情况也被称为竞态条件(race condition),这往往会破坏共享数据的一致性。
在这种情况下,我们就需要采取一些措施来协调它们对共享数据的修改,这通常就会涉及到同步操作。一般来说,同步的用途有两个,一个是避免多个线程在同一时刻操作同一个数据块,另一个是协调多个线程避免它们在同一时刻执行同一个代码块。但是目的是一致的,那就是保证共享数据原子操作和一致性。
- sync.Mutex
sync 包中的 Mutex 就是与其对应的类型,该类型的值可以被称为互斥锁。
import (
"sync"
"runtime"
)
var counter int = 0
func add(a, b int, lock *sync.RWMutex) {
c := a + b
lock.Lock()
counter++
fmt.Printf("%d: %d + %d = %d\n", counter, a, b, c)
lock.Unlock()
}
func main(){
lock := &sync.Mutex{}
for i := 0; i < 10; i++ {
go add(1, i, lock)
}
for {
lock.RLock()
c := counter
lock.RUnlock()
runtime.Gosched()
if c >= 10 {
break
}
}
}
- 条件变量 sync.Cond
sync 包还提供了一个条件变量类型 sync.Cond,它可以和互斥锁或读写锁(以下统称互斥锁)组合使用,用来协调想要访问共享资源的线程。
条件变量 sync.Cond 的主要作用并不是保证在同一时刻仅有一个线程访问某一个共享资源,而是在对应的共享资源状态发送变化时,通知其它因此而阻塞的线程。条件变量总是和互斥锁组合使用,互斥锁为共享资源的访问提供互斥支持,而条件变量可以就共享资源的状态变化向相关线程发出通知,重在「协调」。
//sync.Cond 提供了三个方法:
// 等待通知
func (c *Cond) Wait(){}
// 单发通知
func (c *Cond) Signal() {}
// 广播通知
func (c *Cond) Broadcast() {}
案例:
package main
import (
"bytes"
"fmt"
"io"
"sync"
"time"
)
// 数据 bucket
type DataBucket struct {
buffer *bytes.Buffer //缓冲区
mutex *sync.RWMutex //互斥锁
cond *sync.Cond //条件变量
}
func NewDataBucket() *DataBucket {
buf := make([]byte, 0)
db := &DataBucket{
buffer: bytes.NewBuffer(buf),
mutex: new(sync.RWMutex),
}
db.cond = sync.NewCond(db.mutex.RLocker())
return db
}
// 读取器
func (db *DataBucket) Read(i int) {
db.mutex.RLock() // 打开读锁
defer db.mutex.RUnlock() // 结束后释放读锁
var data []byte
var d byte
var err error
for {
//每次读取一个字节
if d, err = db.buffer.ReadByte(); err != nil {
if err == io.EOF { // 缓冲区数据为空时执行
if string(data) != "" { // data 不为空,则打印它
fmt.Printf("reader-%d: %s\n", i, data)
}
db.cond.Wait() // 缓冲区为空,通过 Wait 方法等待通知,进入阻塞状态
data = data[:0] // 将 data 清空
continue
}
}
data = append(data, d) // 将读取到的数据添加到 data 中
}
}
// 写入器
func (db *DataBucket) Put(d []byte) (int, error) {
db.mutex.Lock() // 打开写锁
defer db.mutex.Unlock() // 结束后释放写锁
//写入一个数据块
n, err := db.buffer.Write(d)
db.cond.Signal() // 写入数据后通过 Signal 通知处于阻塞状态的读取器
return n, err
}
func main() {
db := NewDataBucket()
go db.Read(1) // 开启读取器协程
go func(i int) {
d := fmt.Sprintf("data-%d", i)
db.Put([]byte(d)) // 写入数据到缓冲区
}(1) // 开启写入器协程
time.Sleep(100 * time.Millisecond)
}
#打印结果: reader-1: data-1
原子操作
原子操作通常是 CPU 和操作系统提供支持的,由于执行过程中不会中断,所以可以完全消除竞态条件,从而绝对保证并发安全性,此外,由于不会中断,所以原子操作本身要求也很高,既要简单,又要快速。Go 语言的原子操作也是基于 CPU 和操作系统的,由于简单和快速的要求,只针对少数数据类型的值提供了原子操作函数,这些函数都位于标准库代码包 sync/atomic 中。这些原子操作包括加法(Add)、比较并交换(Compare And Swap,简称 CAS)、加载(Load)、存储(Store)和交换(Swap)
- 加减法*
var i int32 = 1
atomic.AddInt32(&i, 1)
fmt.Println("i = i + 1 =", i)
atomic.AddInt32(&i, -1)
fmt.Println("i = i - 1 =", i)
- 比较并交换
var a int32 = 1
var b int32 = 2
var c int32 = 2
atomic.CompareAndSwapInt32(&a, a, b)
atomic.CompareAndSwapInt32(&b, b, c)
fmt.Println("a, b, c:", a, b, c)
- 加载
var x int32 = 100
y := atomic.LoadInt32(&x)
fmt.Println("x, y:", x, y)
- 存储
var x int32 = 100
var y int32
atomic.StoreInt32(&y, atomic.LoadInt32(&x))
fmt.Println("x, y:", x, y)
- 交换
var j int32 = 1
var k int32 = 2
j_old := atomic.SwapInt32(&j, k)
fmt.Println("old,new:", j_old, j)
- 原子类型
为了扩大原子操作的适用范围,Go 语言在 1.4 版本发布的时候向 sync/atomic 包中添加了一个新的类型 Value,此类型的值相当于一个容器,可以被用来「原子地」存储和加载任意的值
var v atomic.Value
v.Store(100)
fmt.Println("v:", v.Load())
sync.WaitGroup
sync.WaitGroup 类型是开箱即用的,也是并发安全的。该类型提供了三个方法:
| 方法 | 说明 |
|---|---|
| Add | WaitGroup 类型有一个计数器,默认值是0,我们可以通过 Add 方法来增加这个计数器的值,通常我们可以通过个方法来标记需要等待的子协程数量; |
| Done | 当某个子协程执行完毕后,可以通过 Done 方法标记已完成,该方法会将所属 WaitGroup 类型实例计数器值减一,通常可以通过 defer 语句来调用它; |
| Wait | Wait 方法的作用是阻塞当前协程,直到对应 WaitGroup 类型实例的计数器值归零,如果在该方法被调用的时候,对应计数器的值已经是 0,那么它将不会做任何事情。 |
func add_num(a, b int, deferFunc func()) {
defer func() {
deferFunc()
}()
c := a + b
fmt.Printf("%d + %d = %d\n", a, b, c)
}
func main() {
//定义
var wg sync.WaitGroup
//添加监听协程数量
wg.Add(10)
for i := 0; i < 10; i++ {
go add_num(i, 1, wg.Done)
}
//等待
wg.Wait()
}
sync.Once
sync.Once 类型也是开箱即用和并发安全的,其主要用途是保证指定函数代码只执行一次,类似于单例模式,常用于应用启动时的一些全局初始化操作。它只提供了一个 Do 方法,该方法只接受一个参数,且这个参数的类型必须是 func(),即无参数无返回值的函数类型。
案例:
import (
"sync"
)
func dosomething(o *sync.Once) {
fmt.Println("Start:")
//只执行一次
o.Do(func() {
fmt.Println("Do Something...")
})
fmt.Println("Finished.")
}
func main() {
//定义
o := &sync.Once{}
go dosomething(o)
go dosomething(o)
time.Sleep(time.Second * 1)
}
结果:
上下文 context
- context.Context
上下文 context.Context 是用来设置截止日期、同步信号,传递请求相关值的结构体
| 方法 | 说明 |
|---|---|
| Deadline | 返回 context.Context 被取消的时间,也就是完成工作的截止日期; |
| Done | 返回一个 Channel,这个 Channel 会在当前工作完成或者上下文被取消之后关闭,多次调用 Done 方法会返回同一个 Channel; |
| Err | 返回 context.Context 结束的原因,它只会在 Done 返回的 Channel 被关闭时才会返回非空的值;如果 context.Context 被取消,会返回 Canceled 错误;如果 context.Context 超时,会返回 DeadlineExceeded 错误; |
| Value | 从 context.Context 中获取键对应的值,对于同一个上下文来说,多次调用 Value 并传入相同的 Key 会返回相同的结果,该方法可以用来传递请求特定的数据; |
代码演示:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
Context 同步信号:
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
go handle(ctx, 500*time.Millisecond)
select {
case <-ctx.Done():
fmt.Println("main", ctx.Err())
}
}
func handle(ctx context.Context, duration time.Duration) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(duration):
fmt.Println("process request with", duration)
}
}
- context.Background
- context.TODO
- context.WithDeadline
- context.WithValue
并行计算
「并发」一般是由 CPU 内核通过时间片或者中断来控制的,遇到 IO 阻塞或者时间片用完时会交出线程的使用权,从而实现在一个内核上处理多个任务,而「并行」则是多个处理器或者多核处理器同时执行多个任务,同一时间有多个任务在调度,因此,一个内核是无法实现并行的,因为同一时间只有一个任务在调度。
多进程、多线程以及协程显然都是属于「并发」范畴的,可以实现程序的并发执行,至于是否支持「并行」,则要看程序运行系统是否是多核,以及编写程序的语言是否可以利用 CPU 的多核特性。
- 启用多核
在 Go 语言中通过调用 runtime.NumCPU() 方法获取 CPU 核心数
import (
"runtime"
)
func main(){
// 最大 CPU 核心数
cpus:=runtime.NumCPU()
//开启多核计算
runtime.GOMAXPROCS(cpus)
}
使用多核比单核整体运行速度快了4倍左右,查看系统 CPU 监控也能看到所有内核都被打满,这在 CPU 密集型计算中带来的性能提升还是非常显著的,不过对于 IO 密集型计算可能没有这么显著,甚至有可能比单核低,因为 CPU 核心之间的切换也是需要时间成本的,所以 IO 密集型计算并不推荐使用这种机制,什么是 IO 密集型计算?比如数据库连接、网络请求等。
另外,需要注意的是,目前 Go 语言默认就是支持多核的,所以如果上述示例代码中没有显式设置 runtime.GOMAXPROCS(cpus) 这行代码,编译器也会利用多核 CPU 来执行代码,其结果是运行耗时和设置多核是一样的。