Abstract
目标识别通常依赖于从大量真实图像中提取特征。但是,在现实场景中,为不断增长的新的类别收集足够的图像是不可能的。所以,提出新的Zero-shot learning (ZSL)框架,可以在没有真实图像的情况下,生成unseen class的视觉特征。采用所提出的Unseen Visual Data Synthesis (UVDS)算法,在训练阶段可以利用语义向量来生成视觉特征。从而,ZSL问题转化为传统的监督学习问题,也就是说生成的视觉特征可以直接输入到SVM等分类器中。
Motivation
现有的目标识别方法依赖于大量的训练样本来建立模型,但在现实场景中有很大局限:
1、高质量的人工标注数据很昂贵;
2、新的类别在不断增加,而且,细粒度任务使得现有类别更细分;
3、为稀有的类别收集数据很困难
ZSL旨在学习模型能够推广到unseen class。我们利用语义信息来生成高质量的视觉特征,从而将ZSL问题转化为传统的监督分类问题。该思想是受到人类想象力的启发,如图1。给定语义描述,我们可以联想到所熟悉的视觉属性,然后想象出近似的场景。因此,我们利用从语义信息生成视觉特征来代替从真实图像中提取特征。

Contributions
1、提出新的Zero-shot learning (ZSL)框架,可以在没有真实图像的情况下,利用语义信息来生成unseen class的视觉特征。该合成特征可以直接输入到传统分类器中,从而将ZSL问题转化为传统监督学习问题,并且在四个数据集上达到最佳性能。
2、我们发现在semantic-visual embedding过程中存在方差衰减(variance decay)问题,提出扩散正则化(Diffusion Regularisation),可以显示地让信息扩散到所合成特征的每个维度。我们通过正交旋转来实现信息扩散。并且提供了一个有效的优化策略来解决 orthogonal rotation 、structural difference and training bias problem。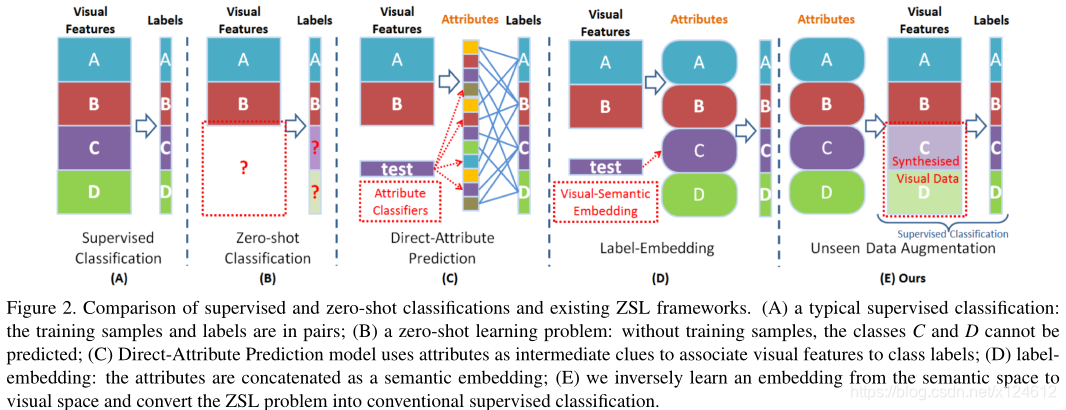
Method
可以利用从语义空间到视觉特征空间的映射来生成视觉特征: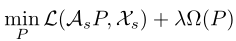
P是语义空间到视觉特征空间的映射矩阵,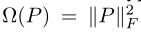 是正则化项
是正则化项
Visual-Semantic Structure Preservation
上述框架虽然简单,但存在两个问题:
1)Structural difference
视觉空间和语义空间存在很大的差异。为了使重构误差最小化,模型倾向于学习两个空间之间的主要成分。因此,对于ZSL任务,生成的数据没有足够的类间判别能力。
2)Training bias
unseen class的生成数据会偏向于seen class,与unseen class的真实数据分布有差异。这是因为基于回归的框架不能挖掘语义空间的内在结构,也不能捕获unseen class和seen class之间的关系。
于是,引入潜在空间V(V = [vnd] ∈ RN×D)来连接视觉空间和语义空间,来保留这两个空间的内在结构信息。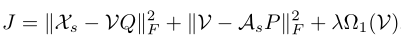
潜在空间V由视觉空间X分解得到,然后语义空间A由潜在空间V分解而来。Q = [qd′d] ∈ RD×D 和 P = [pmd] ∈ RM×D是映射矩阵。
Ω1是dual-graph。基于Local Invariance假设,利用 spectral Dual-Graph 来表示Ω1(V)。视觉空间X和语义空间A都表示成N个顶点的图。对于image-level,构建KNN图(每个顶点与最近的k个顶点之间才有连边,边的权重是1)。对于class-level,语义空间的权重WA变为wij = k/nc(只有顶点 i 和 j 来自同一类别时才有连边)。对于潜在空间V,我们希望如果在WX和WA两个图中顶点 i 和 j 都存在连边,那么潜在空间V中向量vi和向量vj应该尽可能接近。然而由于visual-semantic存在语义鸿沟(流形不一致),两个图的连边会不一致,所以潜在空间V中的权重表示为W = 1/2 (WX + WA )。Ω1(V)可以表示为: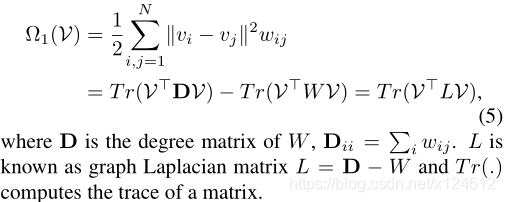
Diffusion Regularisation
另一个重要的问题是方差衰减(variance decay)。在将语义向量映射到视觉特征时(特别是通过P将A映射到V这一步时,维度D远大于维度M),导致算法会选择那些方差小的方向(信息量少的)。所生成特征的信息量集中在少数几个方向,其余维度存在显著的方差衰减,表明所学习的特征表示是严重冗余的。为了解决这个问题,我们期望可以通过旋转将重要信息扩散到所有维度上。因此,修改旋转矩阵Q,使其满足QQ⊤ = I (正交旋转能有效地保持语义空间的特性)。
省略证明正交旋转可以实现方差扩散。(见论文)
最终,损失函数为: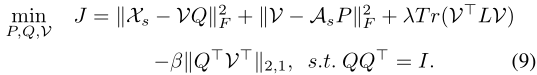
此目标函数能够减小语义向量到视觉特征的重构误差,保留数据结构信息,并且能将信息扩散到生成特征的所有维度上。
Optimisation
整个训练过程是交替优化的,具体步骤省略(见论文)
测试时,可以根据unseen class的语义向量和映射矩阵P、Q来生成视觉特征: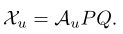
对于image-level,生成特征的数量和测试集大小相同。此时ZSL问题转化为分类问题(实验用了NN、SVM分类器)。对于class-level,一个类别只能生成一个特征,此时可以用few-shot learning方法或者NN分类器。
缺点:生成特征的数量有限制