字符数组的存储方式
public static void main(String[] args){
char[] arr = new char[]{'1','1'};
while(true);
}
数组是运行时数据(动态数据只有在运行的时候才会生成)
klass模型或者说元空间模型
oop模型
一个char数组对应一个TypeArrayKlass(TypeArrayKlass是c++的类)一个char数组对象对应一个typeArrayOopDesc

hsdb工具查看类的元信息(c++中的java类)hsdb是jvm源码带的下载了源码 会有hsdb这个工具

还有一个oop模型 oop模型指的是一个java类对象在jvm中的数据结构

字符串常量池
字符串常量池即String Pool 但是jvm中对应的类是StringTable 底层实现为hashtable
hashtable就是一个数组加链表的结构
hashtable就是数据结构就是下面那样 然后数据1到数据4的数据类型 箭头就表示一个链子指向数据
下图当下标为0的数组有了新数据的样子 旧数据被新数据所指向形成数组加链表
上面的情况如果数据很大那么链表就会很长 java做了优化rehash 如果链表的长度超过100就会触发rehash 这个rehash就是把数组变大把之前数组中的数据全部重新放进这个变大之后的数组中 触发rehash可能会让cpu疯了 而这就是字符串常量池的数据结构 这个hashtable结构的key是一个int值(就是哈希值进行抹除得出一个下标)是一个将Java的String类的实例instanceOopDesc封装成HashtableEntry类型 HashtableEntry类型什么样马上画
前置知识结束开始正题
字符串常量池
下图对应代码 String str1 = “11” 它底层会创建一个String对象实例 然后char会指向oop模型的typeArrayOopDesc(c++类)然后会把这个String封装成一个HashtableEntry它的value就是String的char数组然后把HashtableEntry放入常量池中或者可以理解为底层创建了一个String对象实例 然后又创建了一个HashtableEntry的c++对象 这个HashtableEntry的value会指向String对象实例中char数组然后str1指向这个String对象实例 然后HashtableEntry是放在字符串常量池中 字符串常量池可以理解为是一个list集合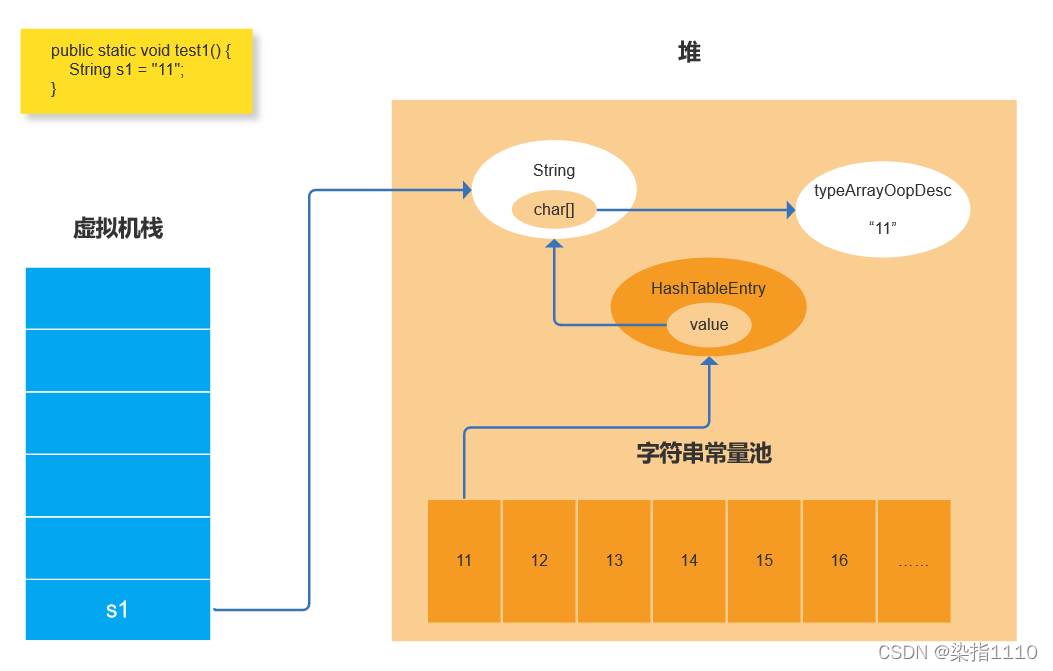
下面的代码对应String str2 = new String(“11”)这里"11"创建了一个char数组并创建了一个String对象实例 然后我们又new了一个String所以我们new的这个String会指向"11"生成的哪个String对象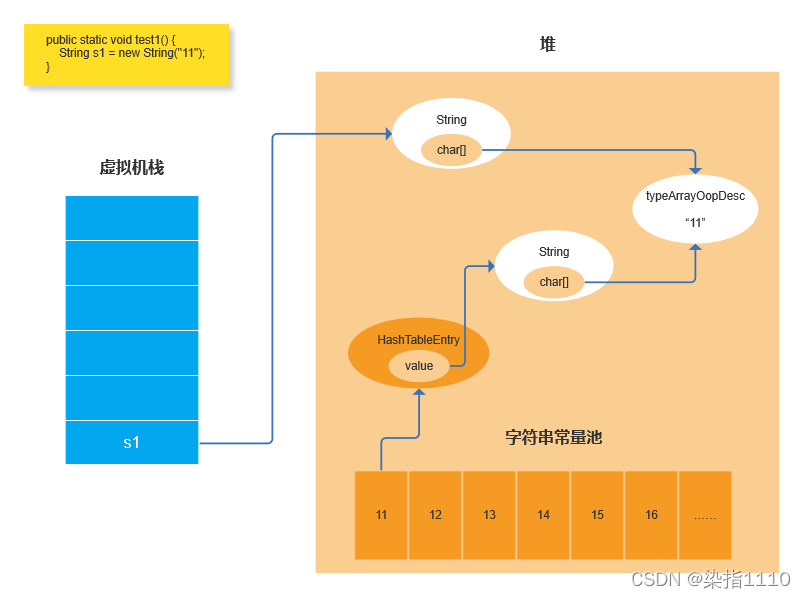
两个双引号的String 会如果值是一样的会共享
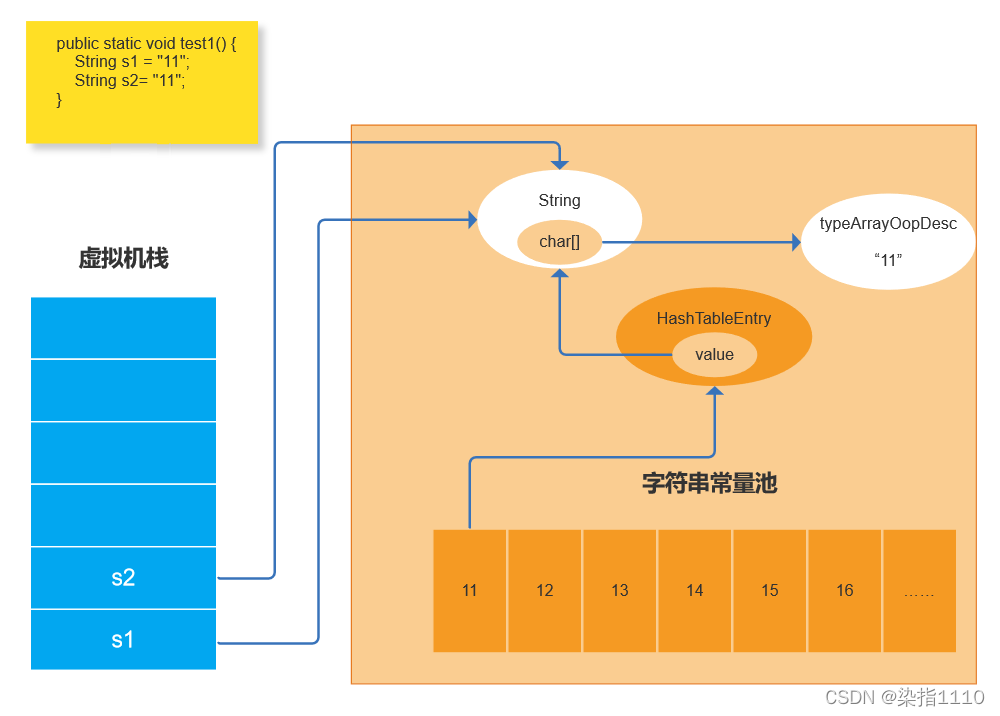
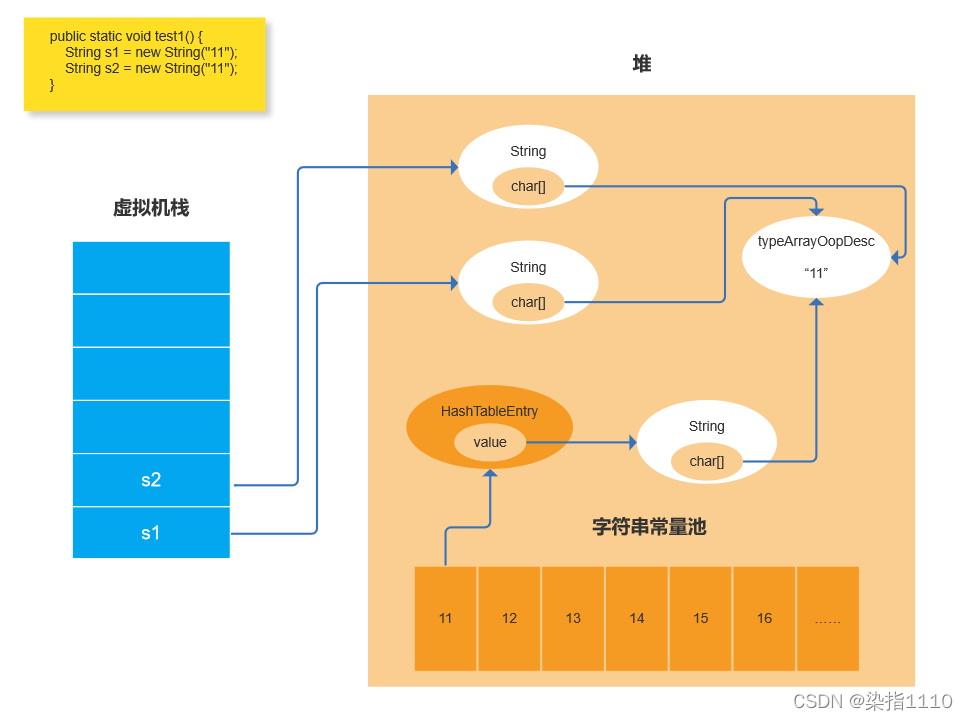
new 两个String也会共享相同的数据
字符串拼接
两个引号 它会在编译的时候把"1"+“1"变成"11”
两个引号不同变量
public static void test2() {
String s1 = “1”;
String s2 = “1”;
String s = s1 + s2;
}

通过字节码文件可以看出编译器给我把拼接字符串编译成了创建一个StringBuilder对象调用它的append方法最后调用toString方法实现的

它调用的toString是创建了一个String执行的是三个参数的String的构造方法 这个构造方法创建的字符串是不会把字符串放入字符串常量池中的 可以调用intern方法强行放入常量池
双引号加String对象拼接
public static void test2() {
String s1 = "1";
String s2 = new String("1");
String s = s1 + s2;
}





字节码的指令不熟悉可以安装idea的差距jcalsslib点一下不知道的指令会打开一个页面然后页面中的内容就是指令的介绍
字符串常量池有就返回没有就创建

jdk9的字符串去重
字符串去重的条件必须是G1垃圾收集器并且此字符串经历过三次gc
开启g1垃圾收集器:-XX:+UseG1GC
开启字符串去重功能: -XX:+UseStringDeduplication
字符串去重原理
两个字符串内存地址不一样但是内容一样
优缺点
优点减少内存开销
缺点cpu会很忙