往 colab 里面 加载 kaggle 的数据
好像只要小于 60 g 的 数据,你都可以这样干
- 先去 kaggle 申请api key
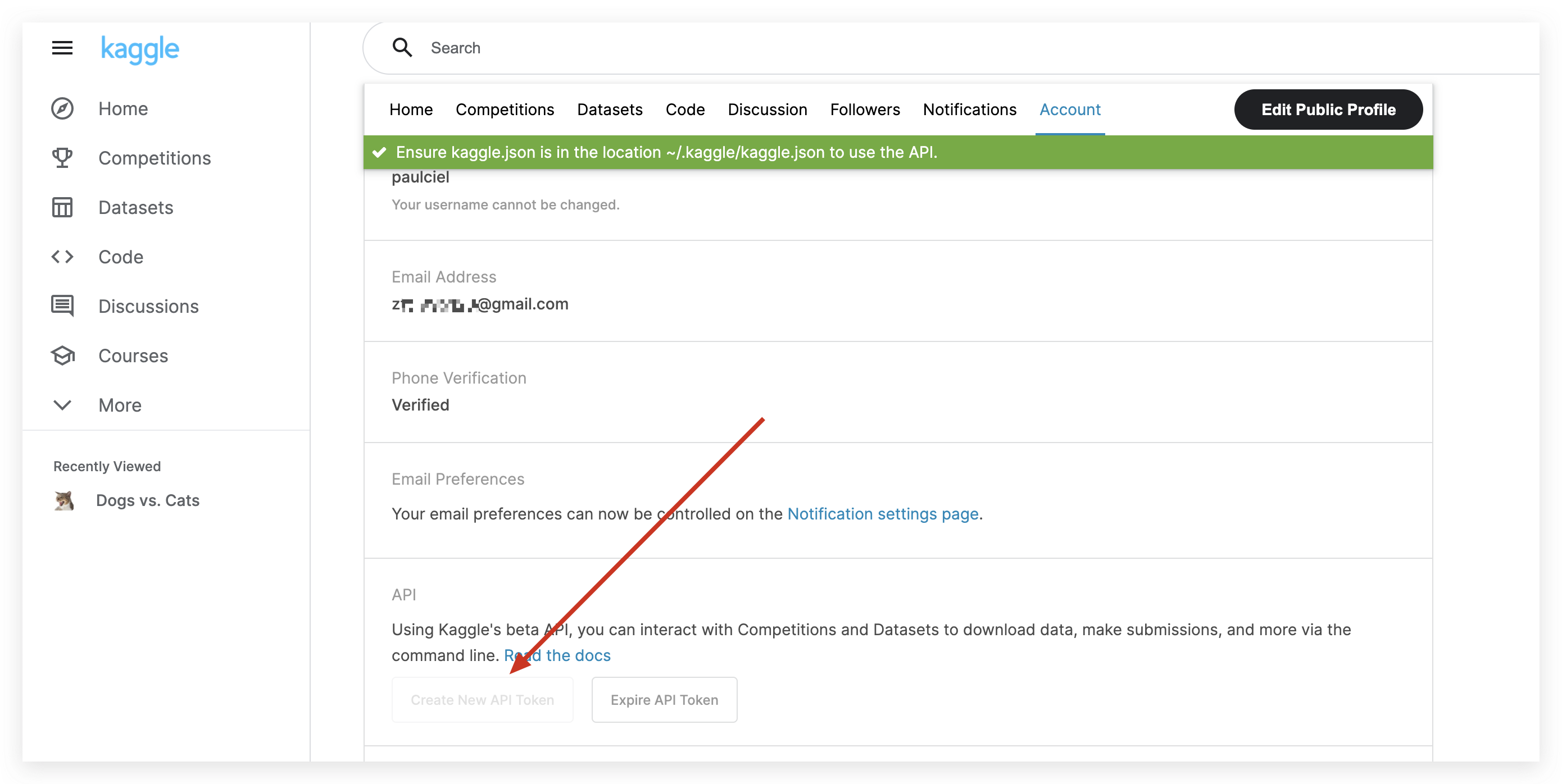
- 得到一个 kaggle.json

- 在 colab 安装 kaggle
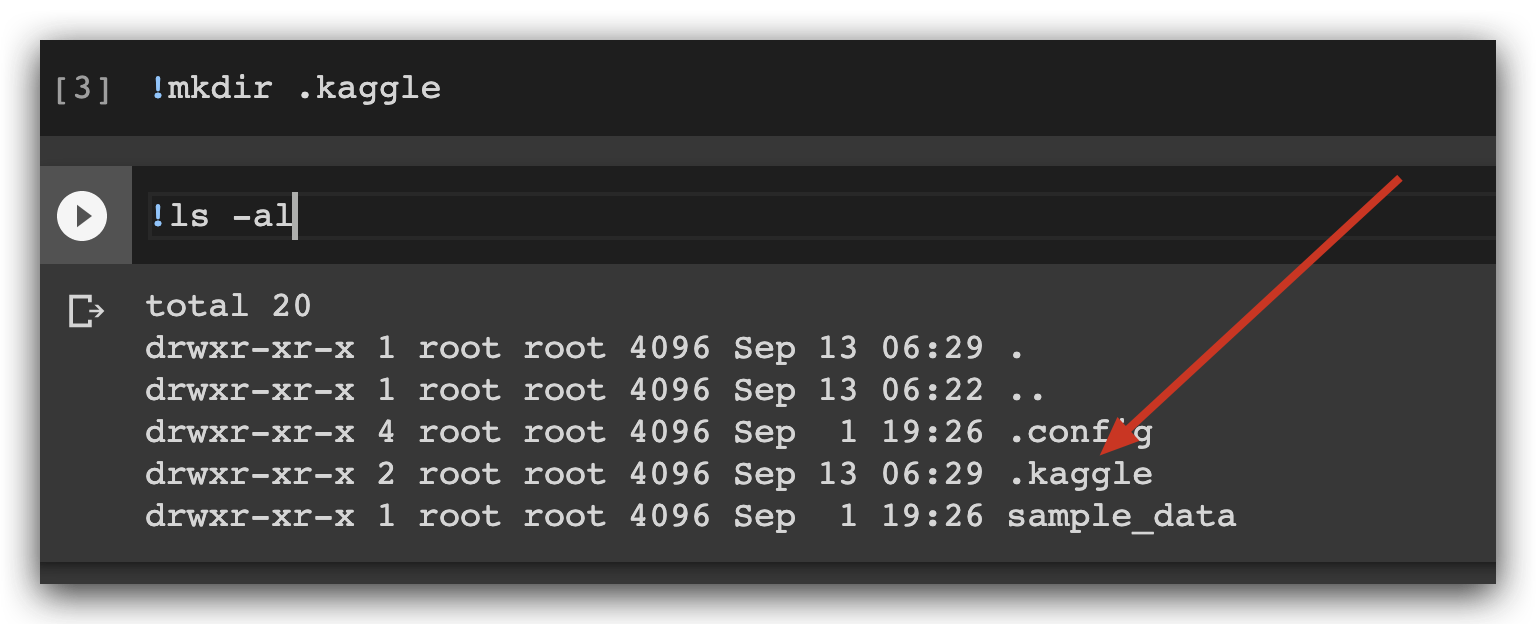
- 建立 kaggle 文件夹
- 将之前下载 的 kaggle json 写入 colab
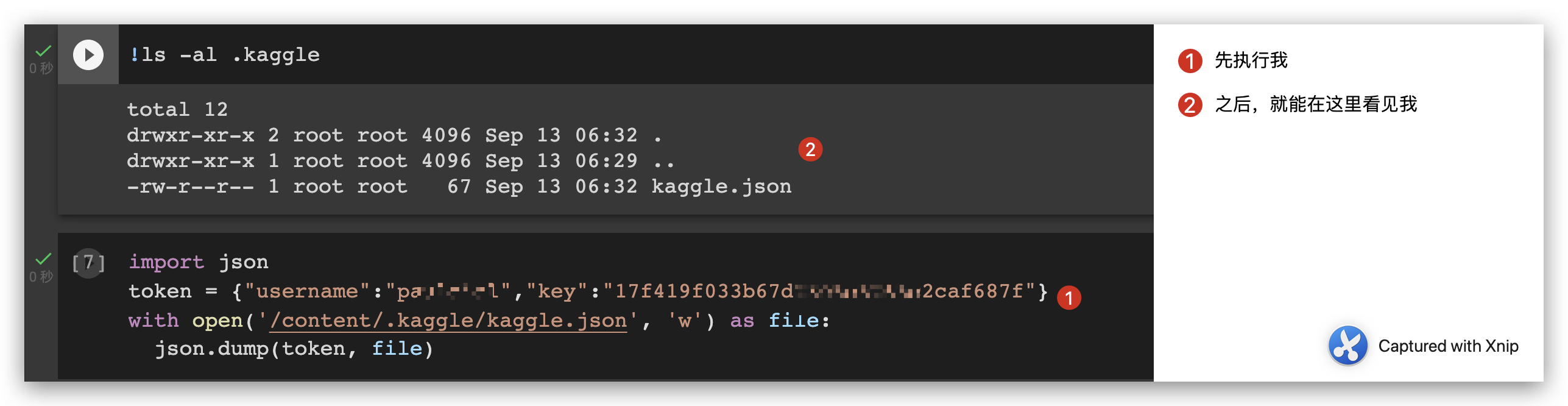
- 继续 配置 kaggle
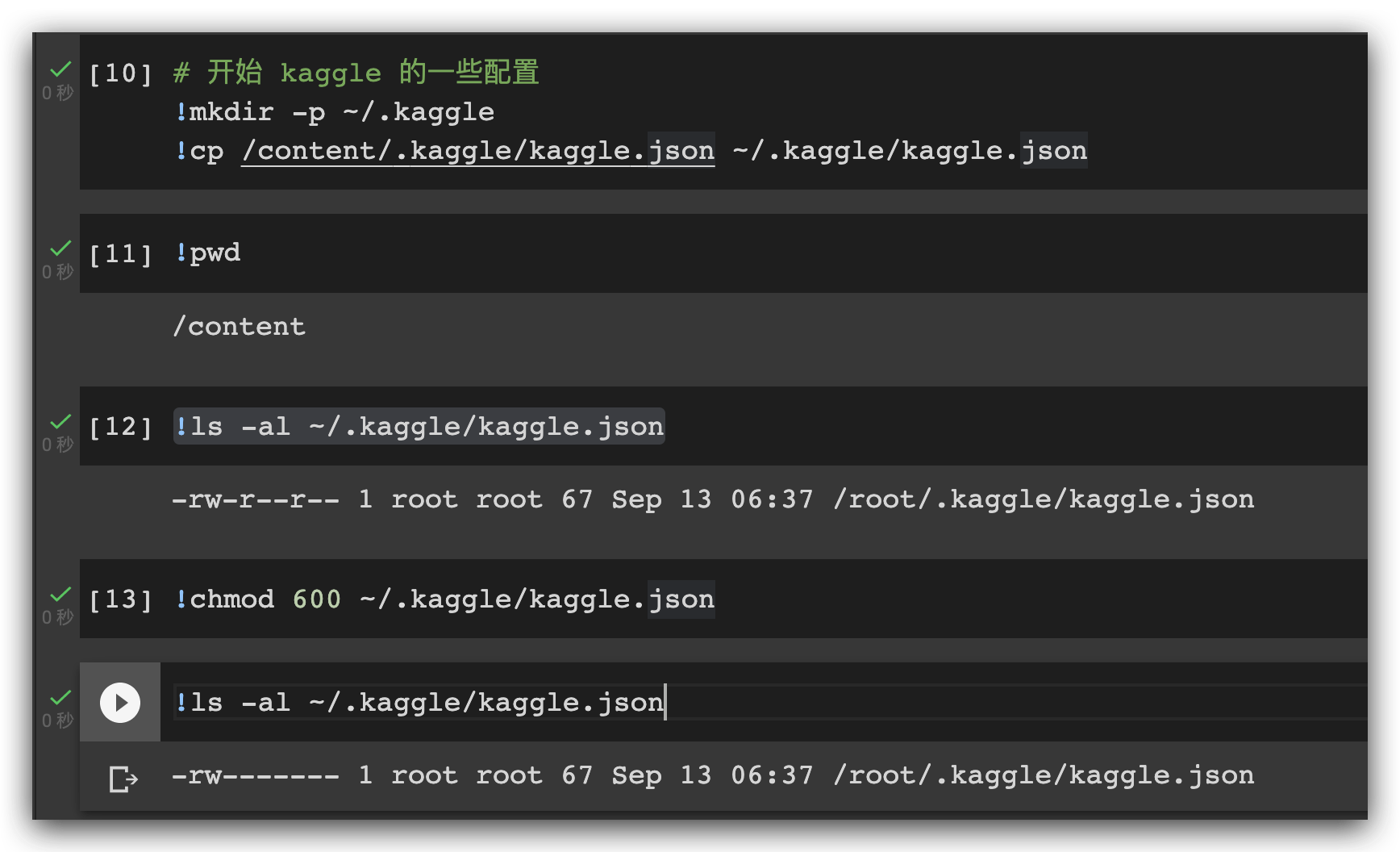
- 指定kaggle数据集保存的位置
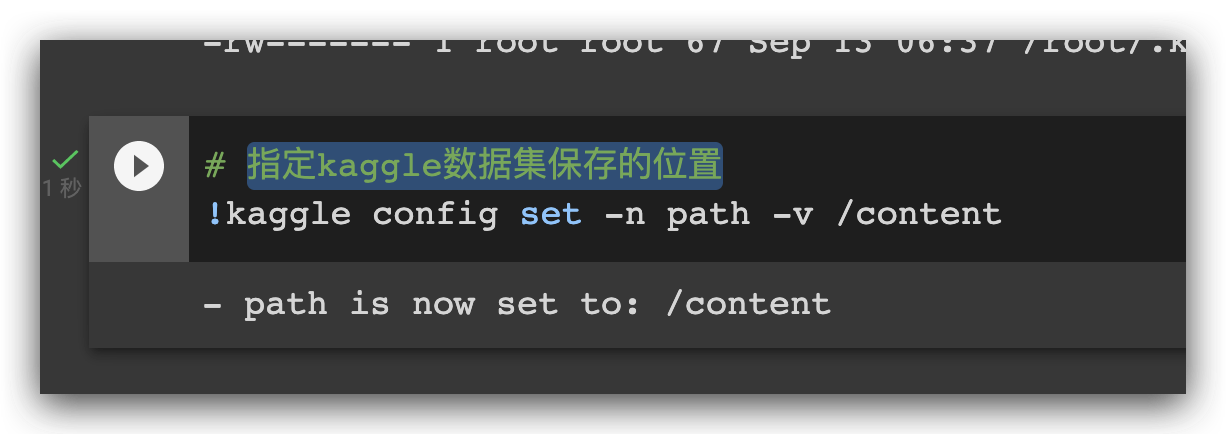
- 执行下列语句查看 Kaggle datasets
下载猫狗数据集 的 示范
数据集 位于: https://www.kaggle.com/c/dogs-vs-cats/data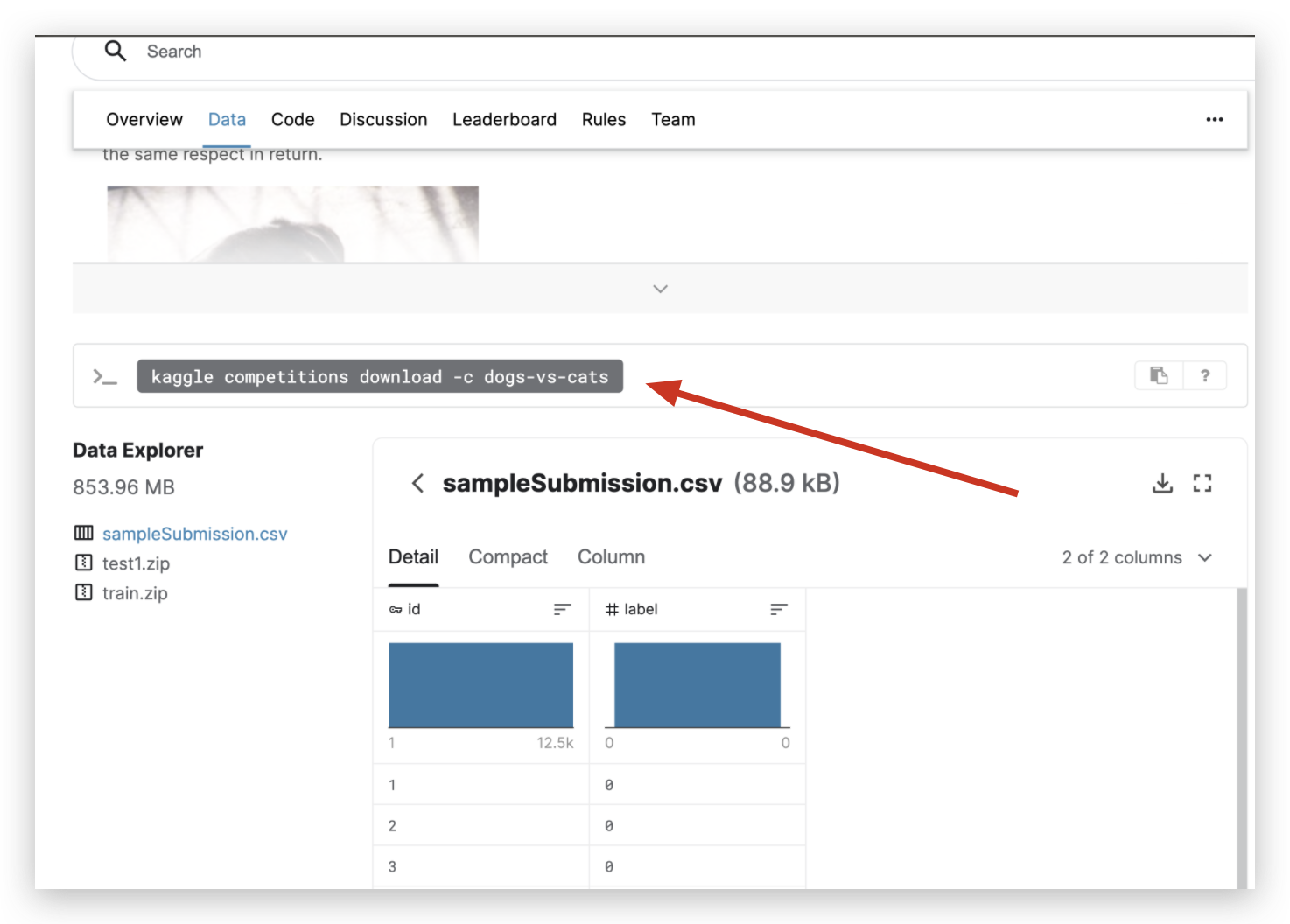
所以:
kaggle competitions download -c dogs-vs-cats
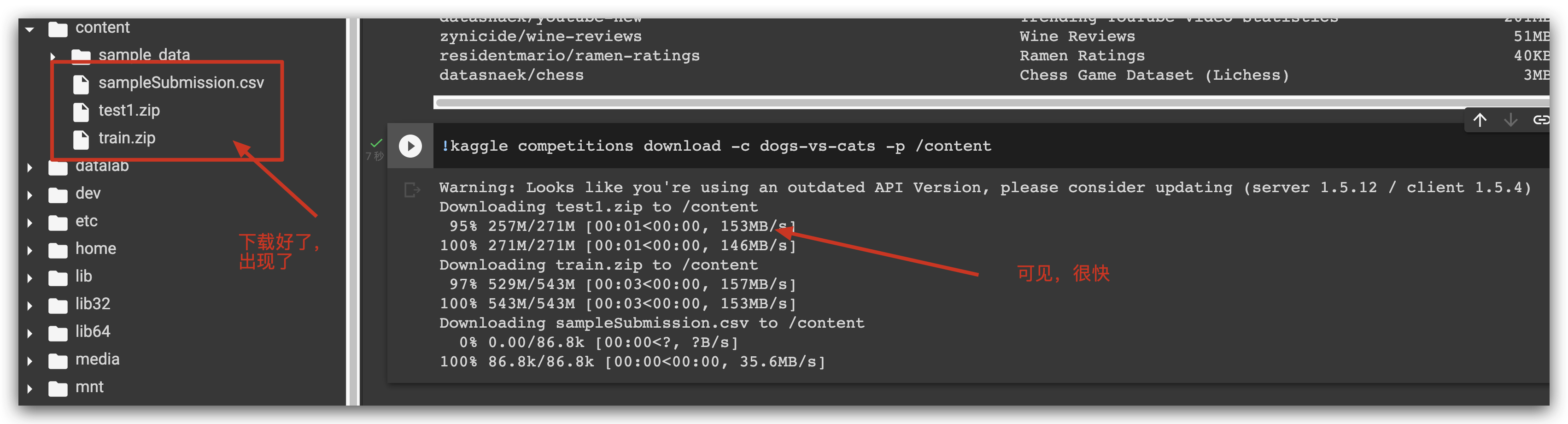
如果你有解压的需求:
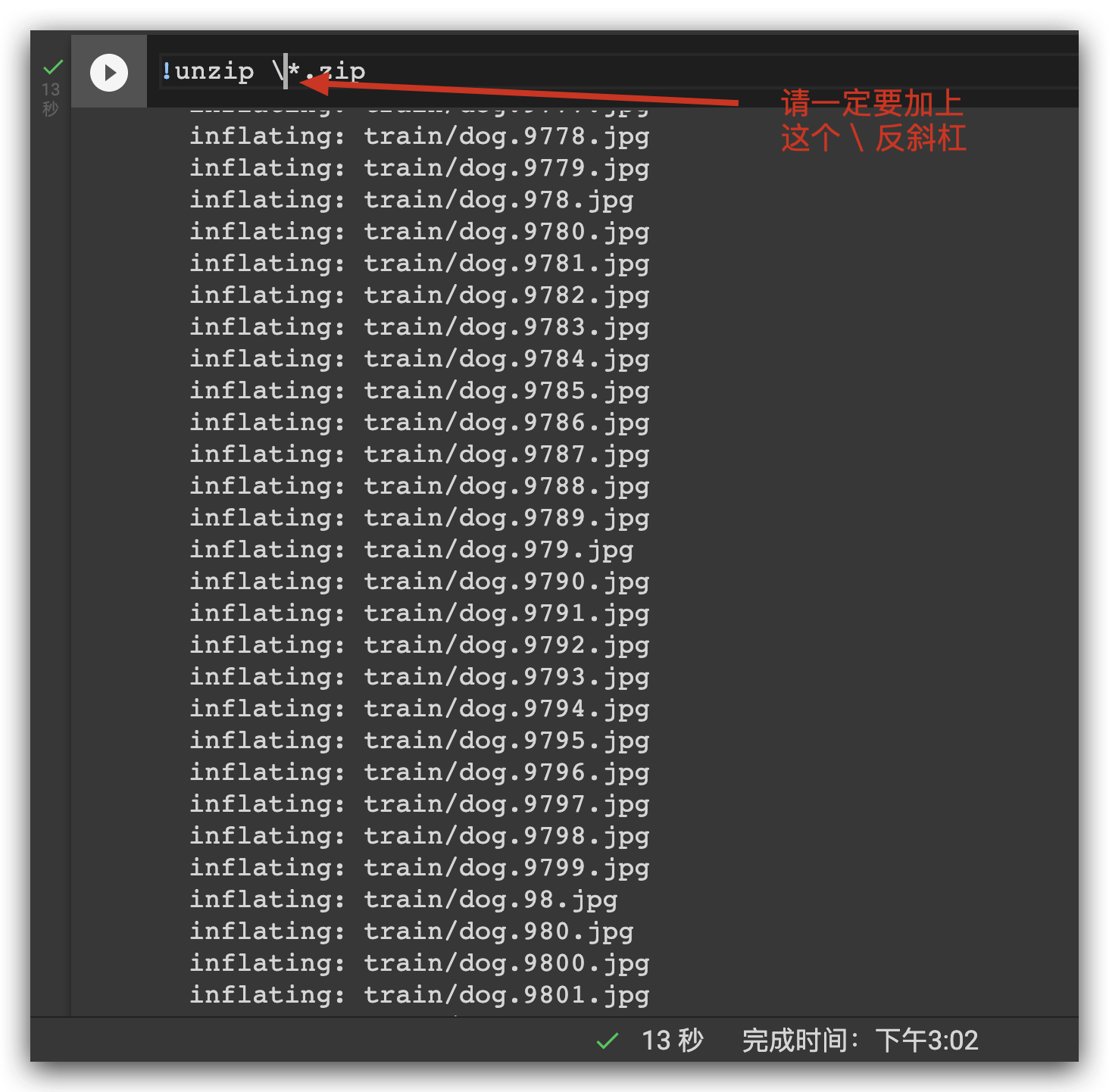
!unzip \*.zip
你就得到: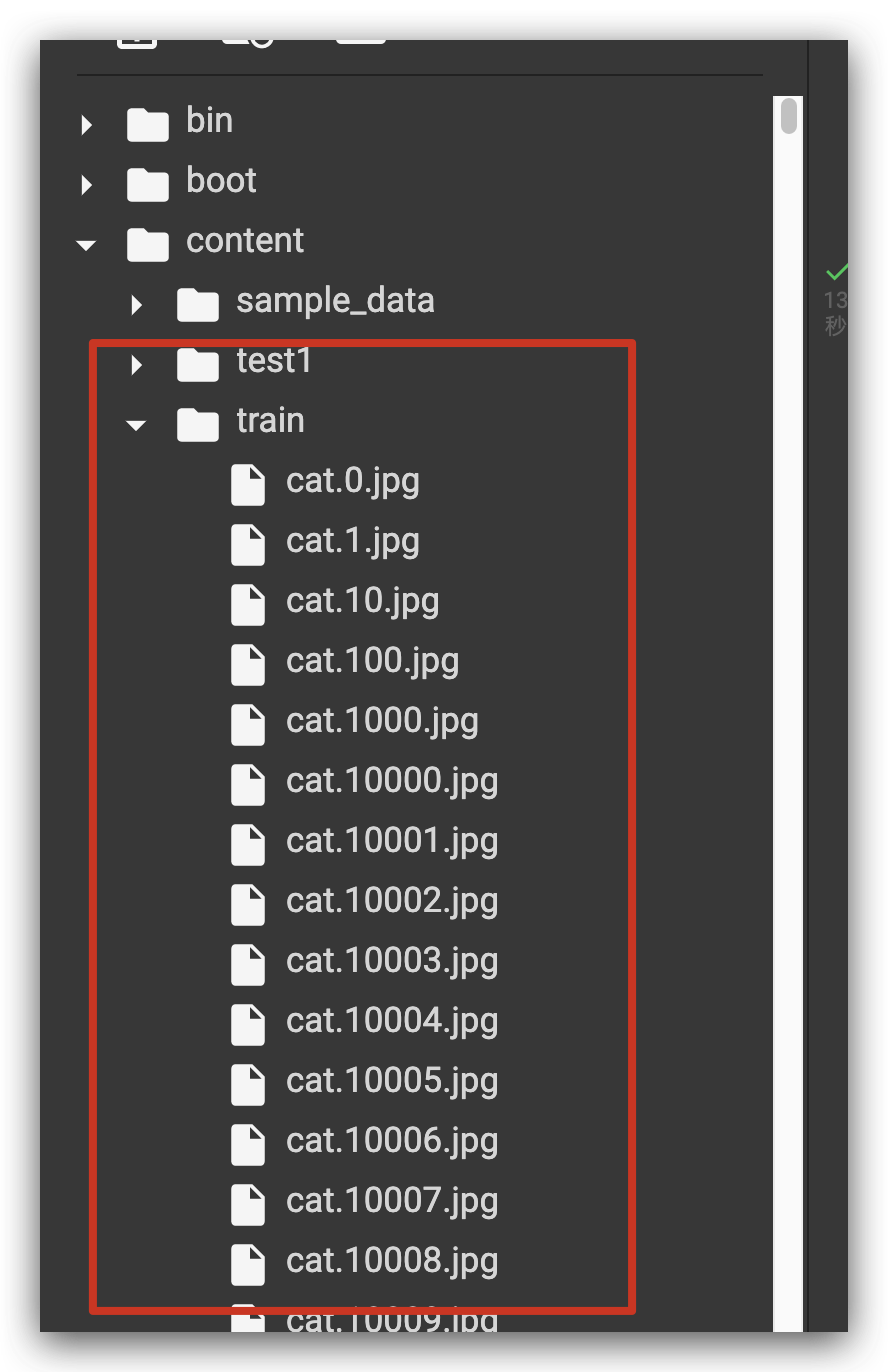
工程文件结构
他的
她然后移动到这里: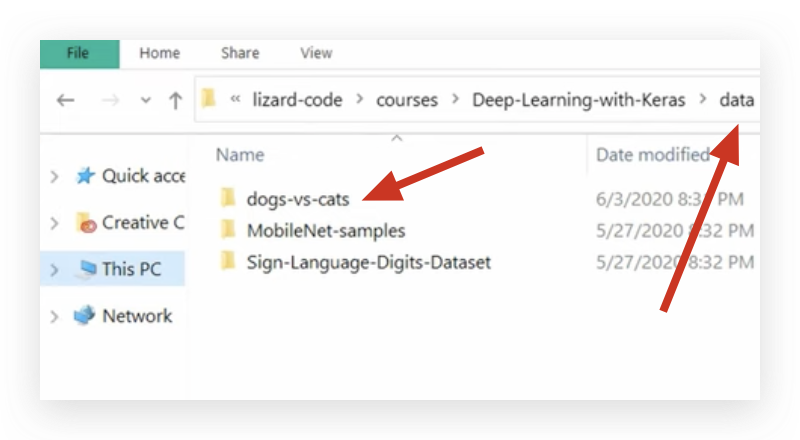
后记,这个有点坑,她在视频里面没说清的事情
所有的 图片 直接存在 dogs-vs-cats 这个文件夹 下, 而不是 nested 的 train 文件夹下。
而我 一开始 以为是 在 nested 的 train 文件夹下; aka : dogs-vs-cats/train/manyImage.jpg
实际上 ,应该: dogs-vs-cats/manyImage.jpg
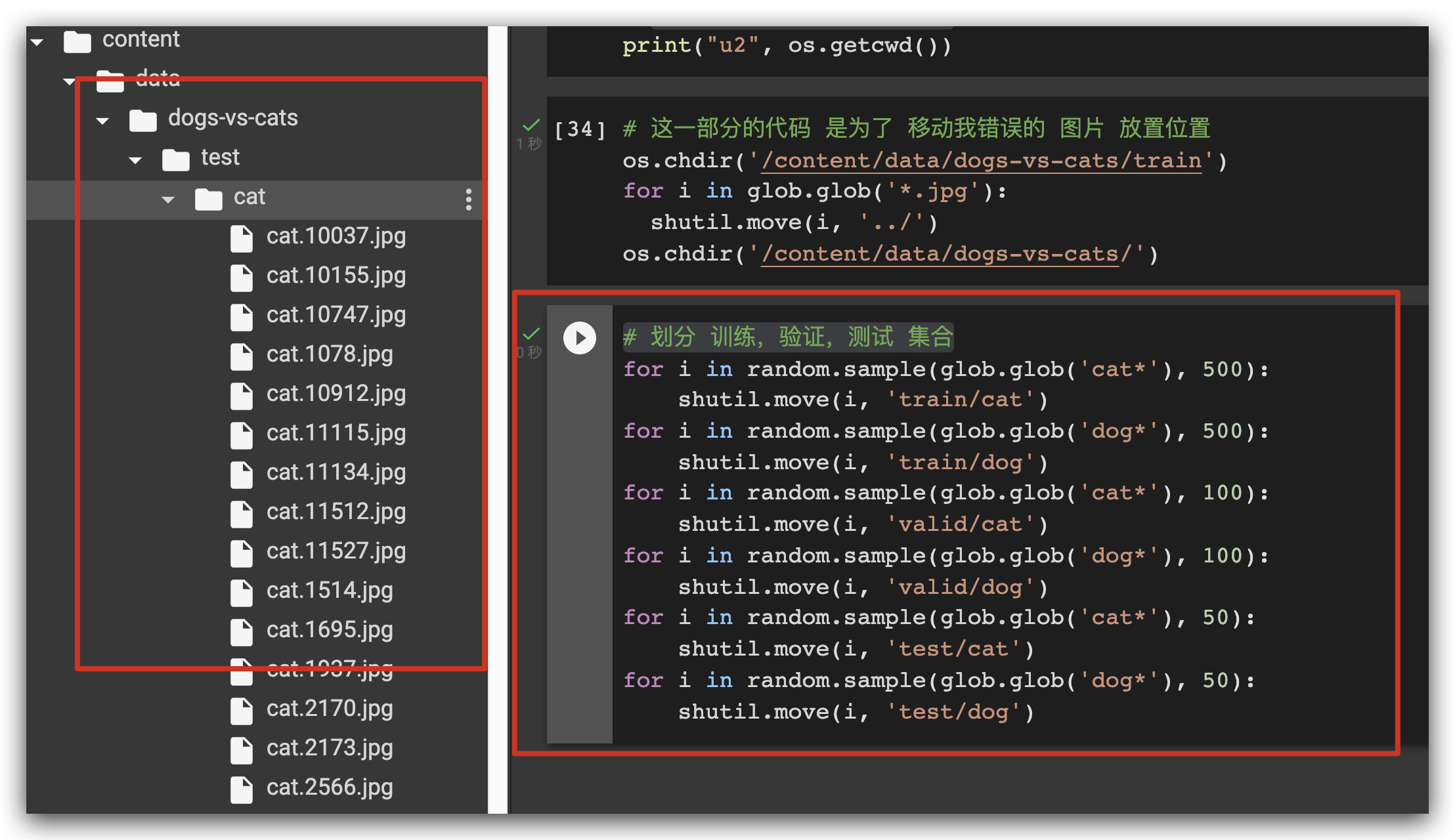
所以我必须做一个 图片文件 的 挪位:
挪
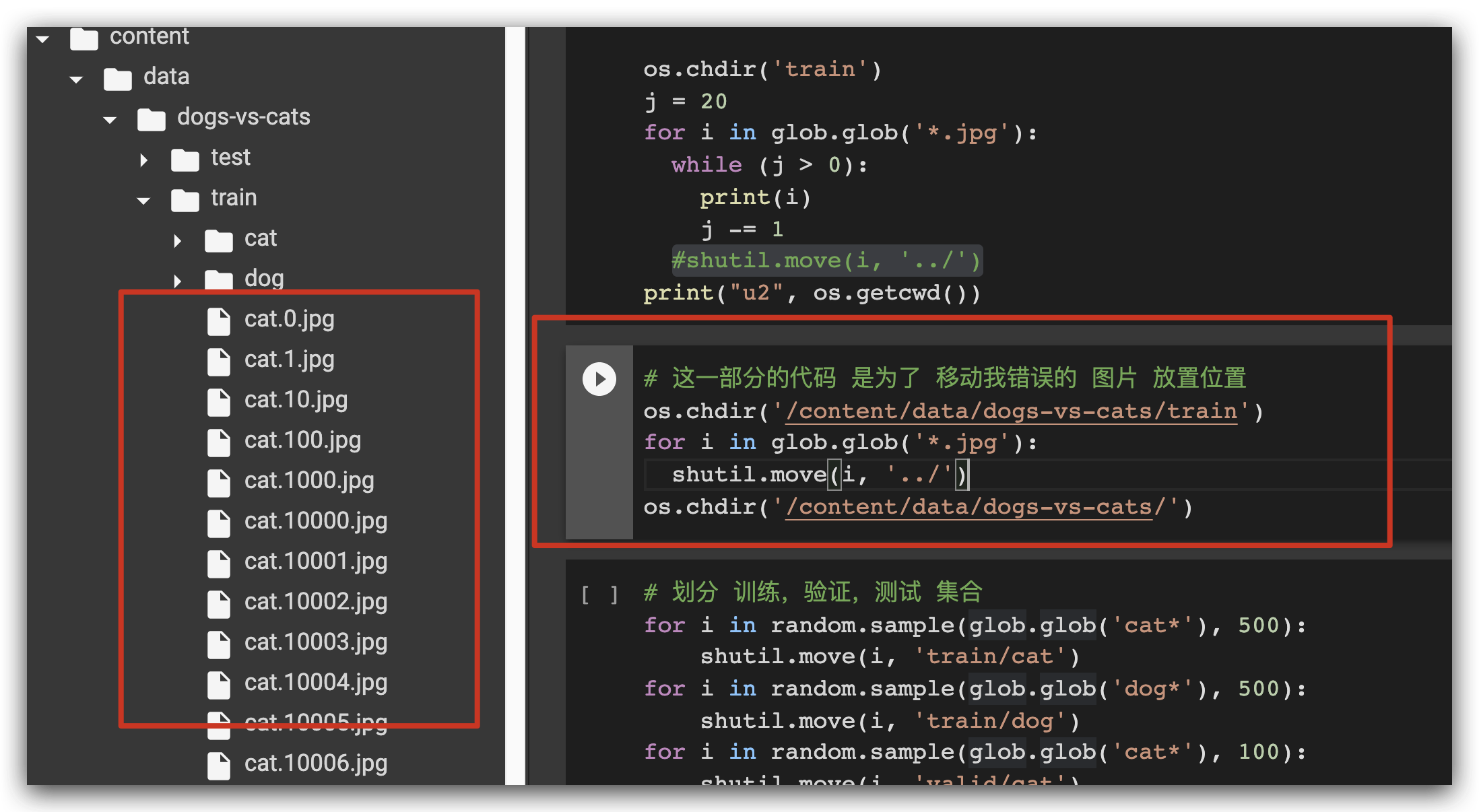
挪好了
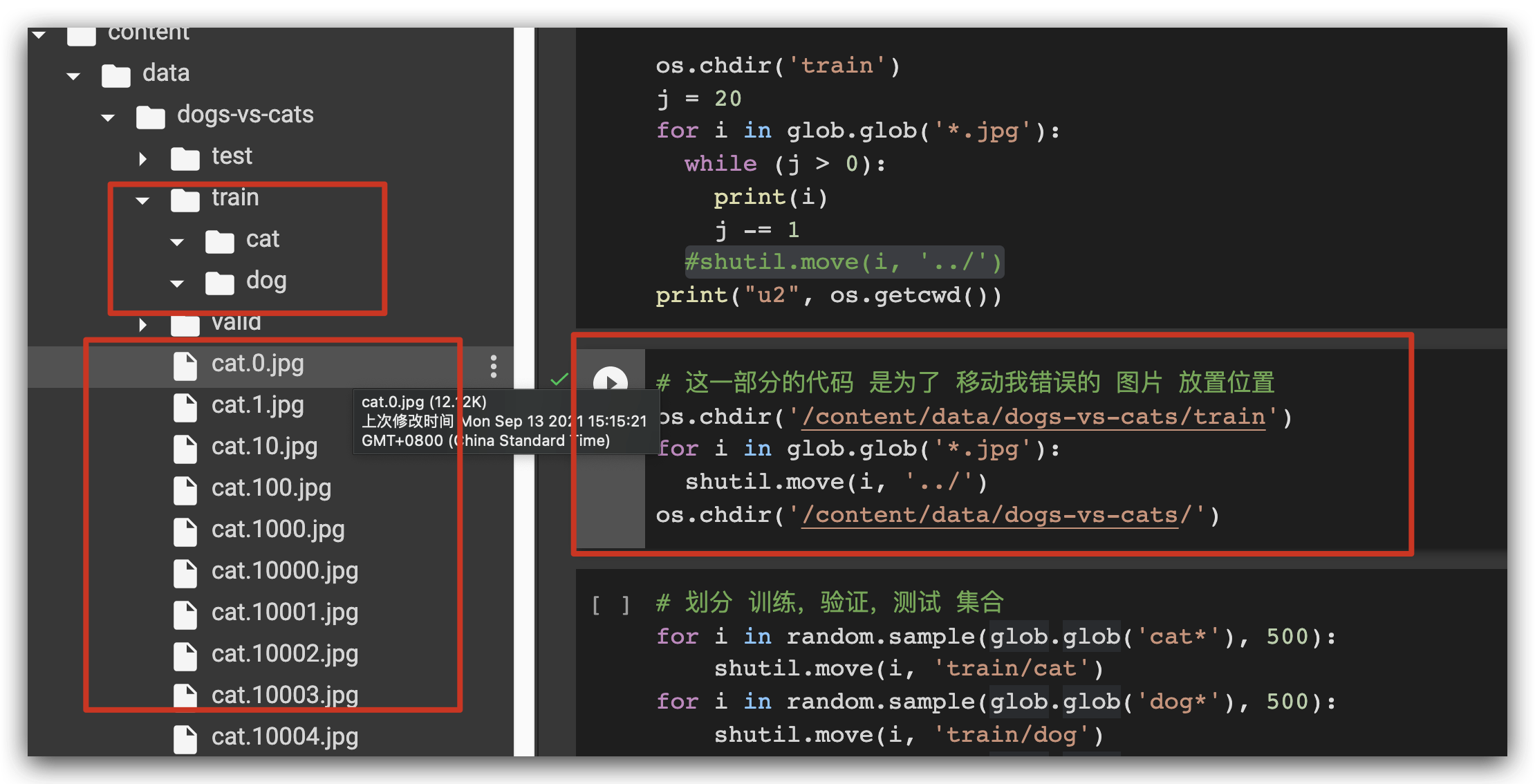
我开始了:
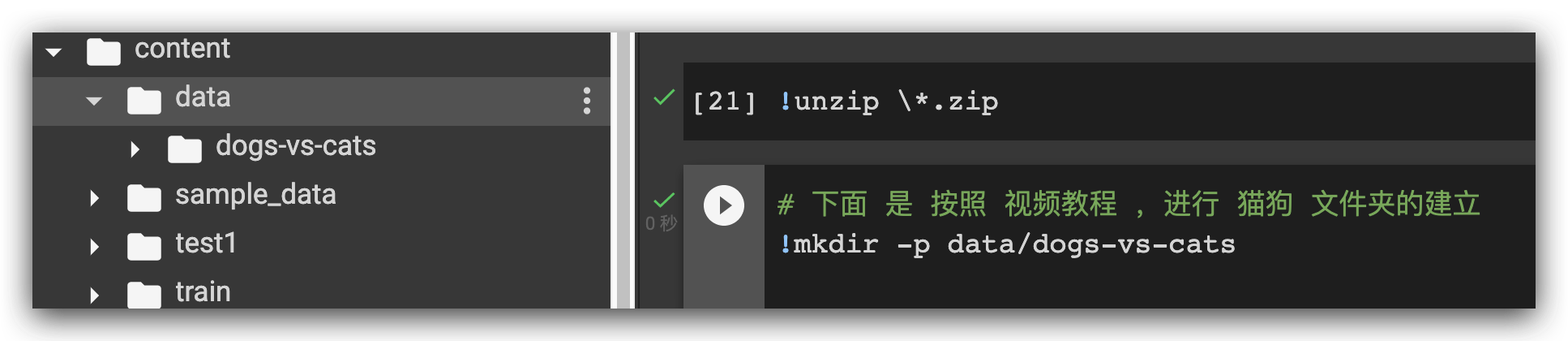
然后 复制 过去:
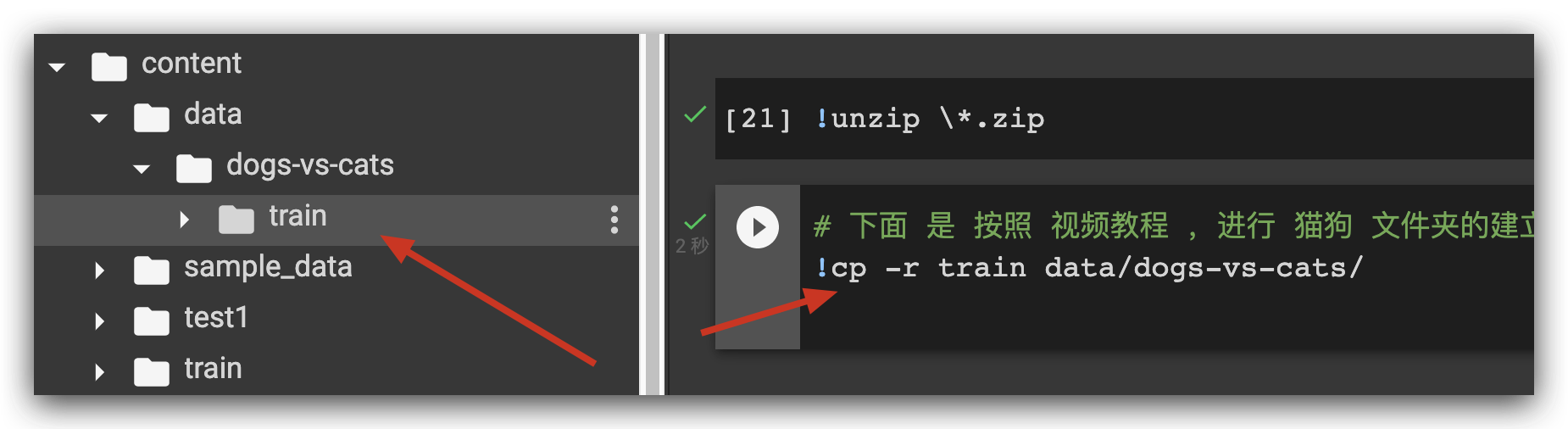
然后建立文件夹
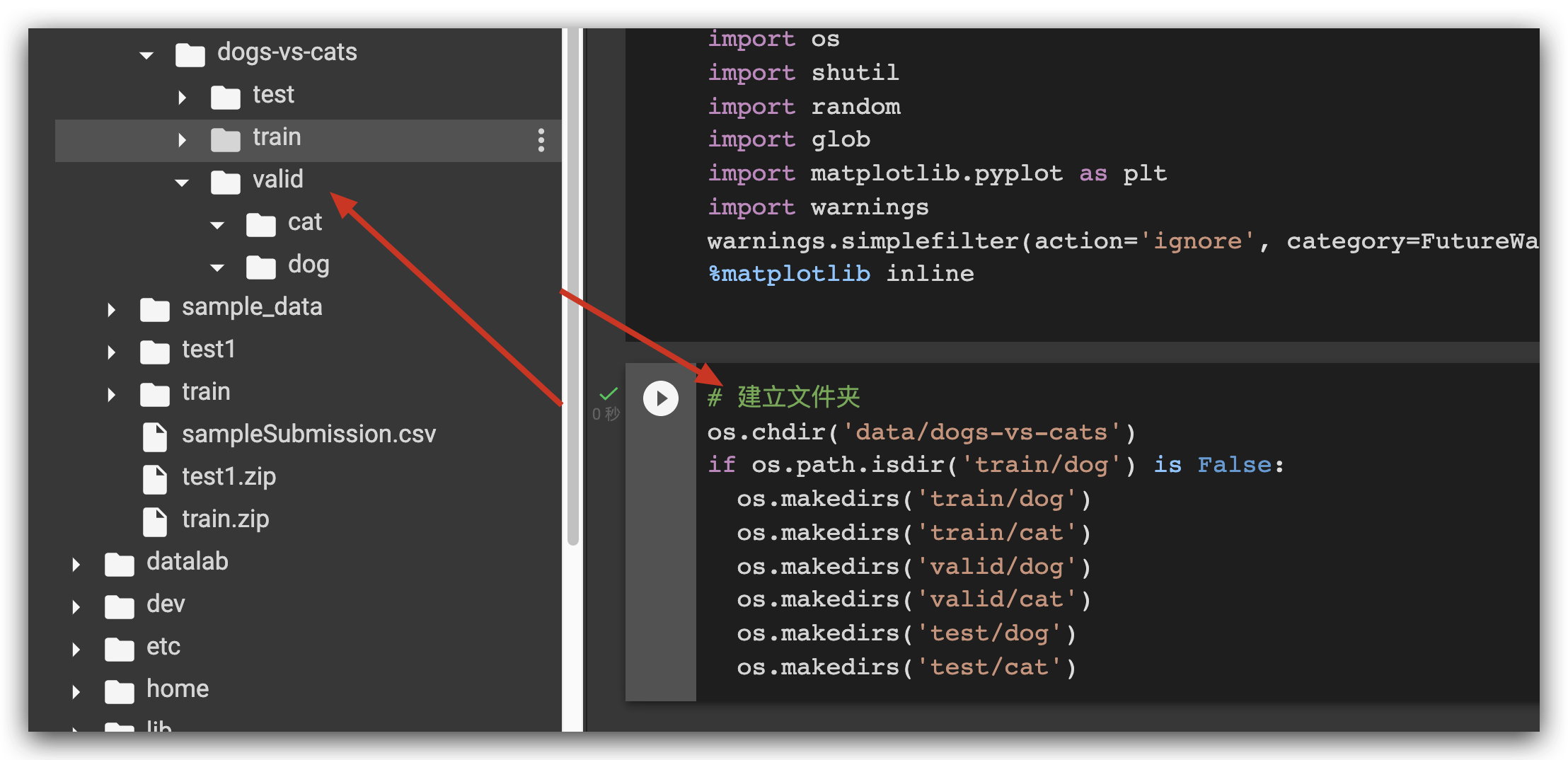
划分 训练,验证,测试 集合
最后的 工程 结构是:
数据准备好了之后,开始 写展示数据的代码
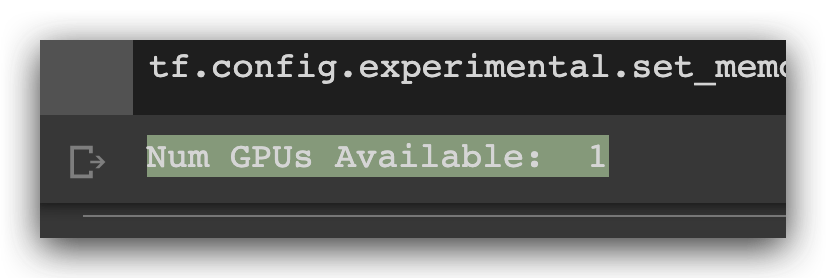
看看有没有用 gpu
physical_devices = tf.config.experimental.list_physical_devices('GPU')
print("Num GPUs Available: ", len(physical_devices))
tf.config.experimental.set_memory_growth(physical_devices[0], True)
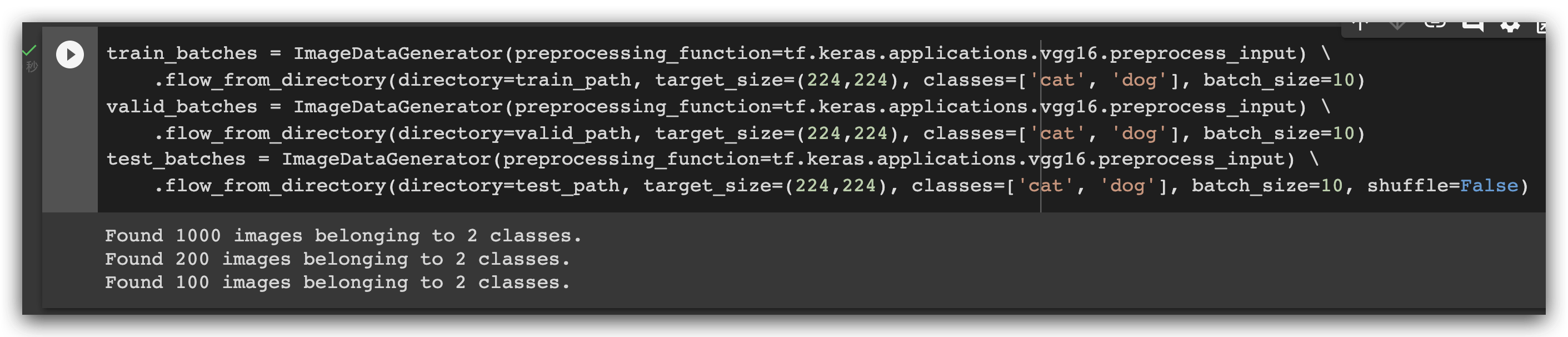
生成 batch
train_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.vgg16.preprocess_input) \
.flow_from_directory(directory=train_path, target_size=(224,224), classes=['cat', 'dog'], batch_size=10)
valid_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.vgg16.preprocess_input) \
.flow_from_directory(directory=valid_path, target_size=(224,224), classes=['cat', 'dog'], batch_size=10)
test_batches = ImageDataGenerator(preprocessing_function=tf.keras.applications.vgg16.preprocess_input) \
.flow_from_directory(directory=test_path, target_size=(224,224), classes=['cat', 'dog'], batch_size=10, shuffle=False)
这里的 test set 有一个参数不同,就是 shuffle 这个 参数,原因是为了 之后,我们更好地 形成 混淆矩阵。
现在 看看我们 准备好的数据
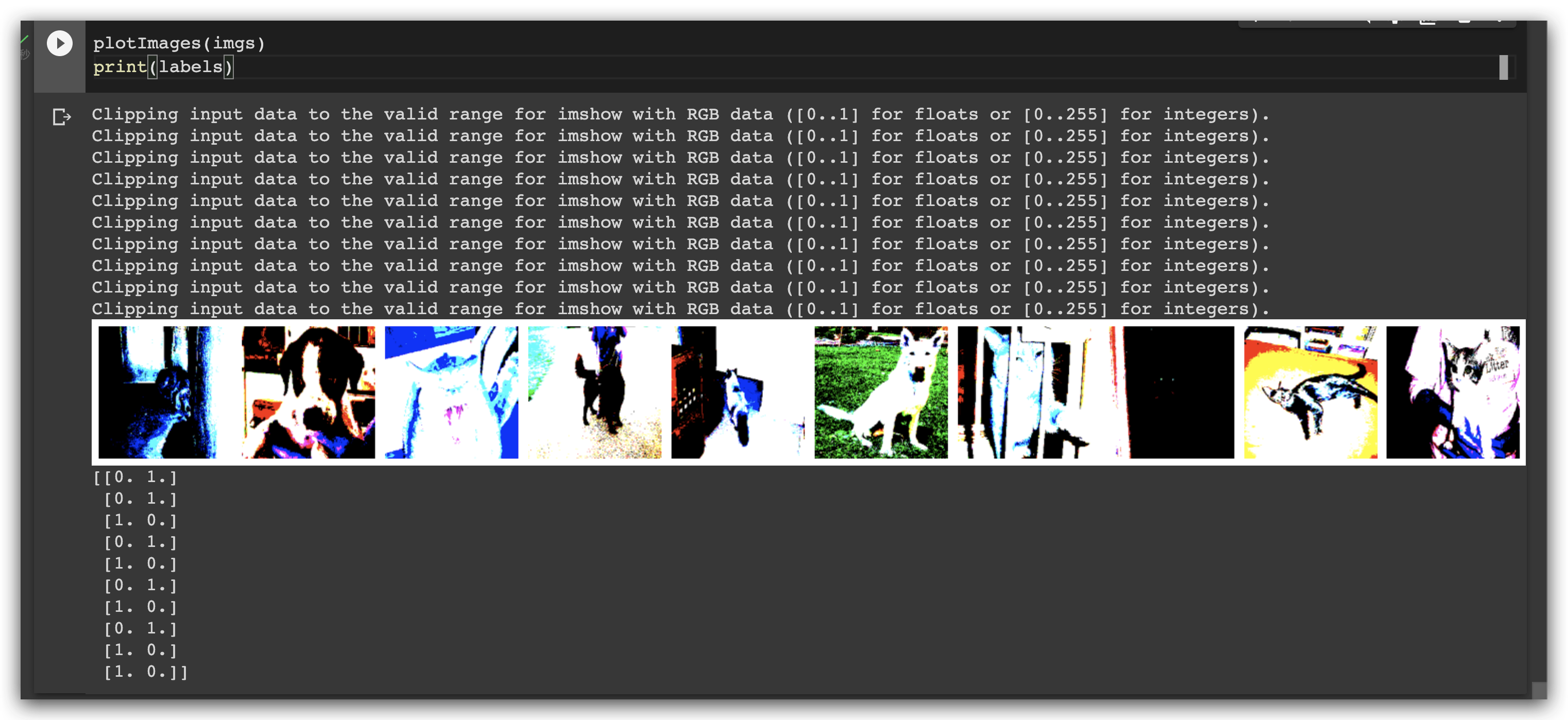
(这些难以辨认的图像,是因为来自了 vgg16 的处理)
参考
- 加载 kaggle 数据:
辅助参考:国人的: 在 colab 中加载 kaggle 数据集
- 教程部分:
版权声明:本文为paulkg12原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。