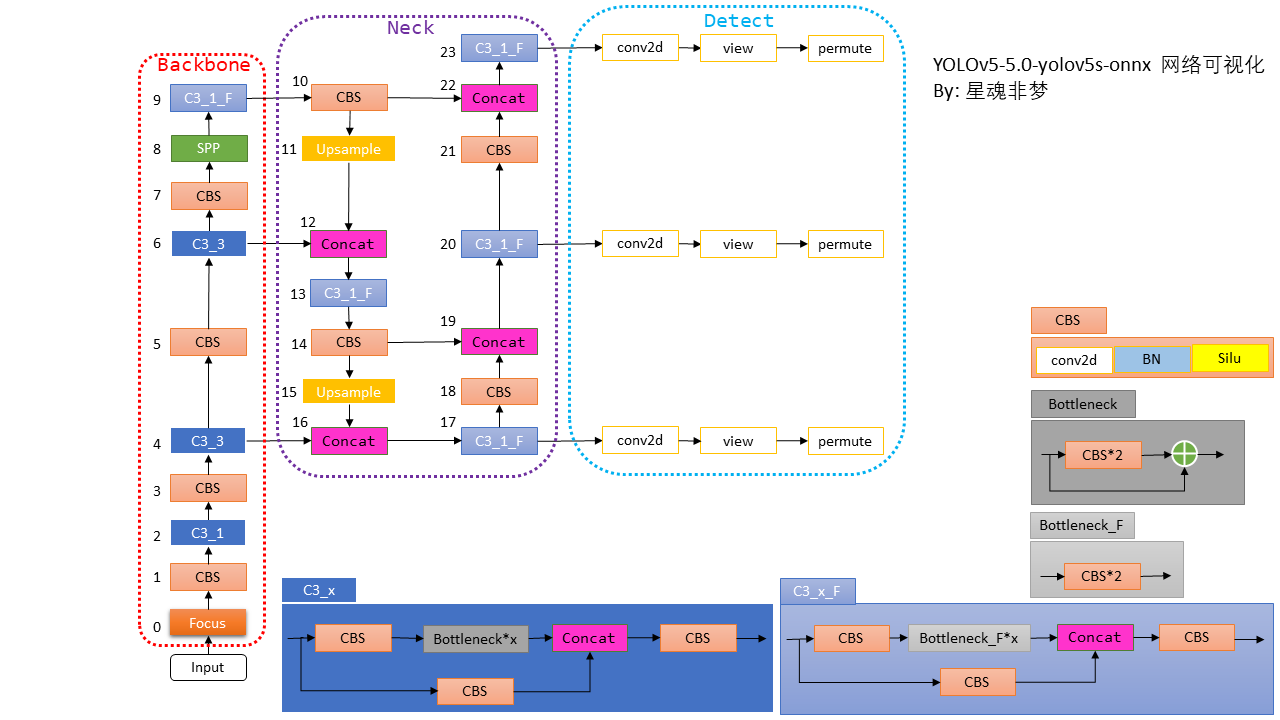
| YOLO | Input | Backbone | Neck | Head | 置信度Loss | 坐标回归Loss | 分类Loss |
| v1 | 448*448 | GoogleNet | FC*2 | MSE | |||
| v2 | 32x | DarkNet-19 | Passthrough | Conv | MSE | ||
| v3 | 32x | DarkNet-53 | FPN | Conv | BCE | (x,y) BCE (w,h) MSE | BCE |
| v4 | 32x | CSPDarkNet-53 | SPP PAN | 同v3 | BCE | CIOU | BCE |
| v5-5.0v | 32x | C3Net | SPP PAN | 同v3 | BCE- WithLogitsLoss | CIOU | BCE- WithLogitsLoss |
损失函数
正负样本分配
yolov5与v3和v4一样都使用了3个 head 预测,一共9种 anchor,每个head被分配到3个。
3个head的分辨率为输入的 8、16和32倍下采样,比如640输入,那么head1 = 80,head2 = 40,head3 = 20:
head1 分配三个最小的 anchor;
head2 分配三个中等的 anchor;
head3 分配三个最大的 anchor。
遍历每个head:
1. 选择哪种尺度的Anchor:每个标注框的 w, h 和当前head的3种Anchors的W和H计算比值r,如果两个比值 r 都小于self.hyp['anchor_t'](data/hyp.scratch.yaml:anchor_t: 4.0),那么当前标注框中心(下图红色点)所在的 那个Anchor 就是正样本。
2. 考虑另外两个cell: 如下图,3个cell中的满足上述条件的Anchor都会被选为正样本。所以对于一个目标,最多有9个正样本。
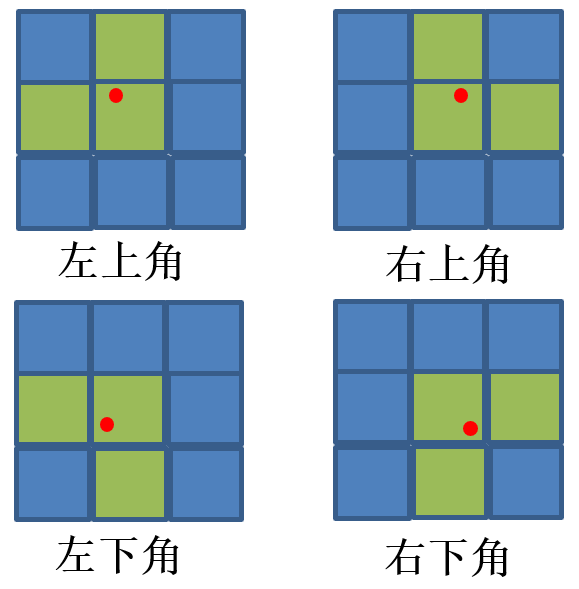
3. 其他的cell中的全部Anchor 和不满足条件1的都是负样本。
正样本:
当前head中的三个cell中 r<4 的Anchor。
正样本需要计算:置信度损失(标签为CIOU+BCEWithLogitsLoss)、分类损失(标签平滑+BCEWithLogitsLoss)和回归损失(CIOU)。BCEWithLogitsLoss等价于对输出的置信度做sigmoid,然后再使用BCELoss。
,其中
为下面代码中的 tobj。
self.gr是一个人为加大训练难度的系数,假设该值为1,那么置信度的标签值就是 CIOU
# 预测信息有置信度 但是真实框信息是没有置信度的 所以需要我们人为的给一个标准置信度
# self.gr是iou ratio [0, 1] self.gr越大置信度越接近iou self.gr越小置信度越接近1(人为加大训练难度)
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio分类损失:
坐标损失:
负样本:
当前head中的三个cell中 r=>4 的Anchor 或 其他cell 的 所有Anchor。负样本只计算 置信度损失(标签为0)。
总损失:
参考:
yolov5目标检测神经网络——损失函数计算原理_萌萌哒程序猴的博客-CSDN博客_yolov5损失函数
1. 有网友说,看到有的材料写的坐标损失是GIOU.
原因:yolov5 tag 有多个版本 1.0 2.0 版本使用的是 GIOU 后面的版本都是使用的CIOU。那些公开的材料估计是太老了。
2. 网友私信:Focal loss 是替换的什么?其实是下面代码,把分类和置信度loss 都替换了。
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)