1. Export/Import(导入导出)
hdfs常用命令:
http://www.cnblogs.com/gaopeng527/p/4314215.html
1) 导出
通过Export导出数据到目标集群的hdfs,再在目标集群执行import导入数据,Export支持指定开始时间和结束时间,因此可以做增量备份,Export工具参数如下:
可见,在导出时可以指定version,starttime,endtime等参数,并且可以通过-D指定是否压缩,指定caching等属性。
//hbase org.apache.hadoop.hbase.mapreduce.Export test4 hdfs://t2-namenode:9000/test4_90 1
1415693812520 1415694912520
//hbase org.apache.hadoop.hbase.mapreduce.Export 表名 数据文件位置 版本 开始时间 结束时间
Export导出工具与CopyTable一样是依赖hbase的scan读取数据,并且采用的InportFormat与CopyTable一样是TableInputFormat类,从该类的getSplits()方法可以看出MR的map数与hbase表的region数相同。
如hbase的test_table表内容如下:

导出:
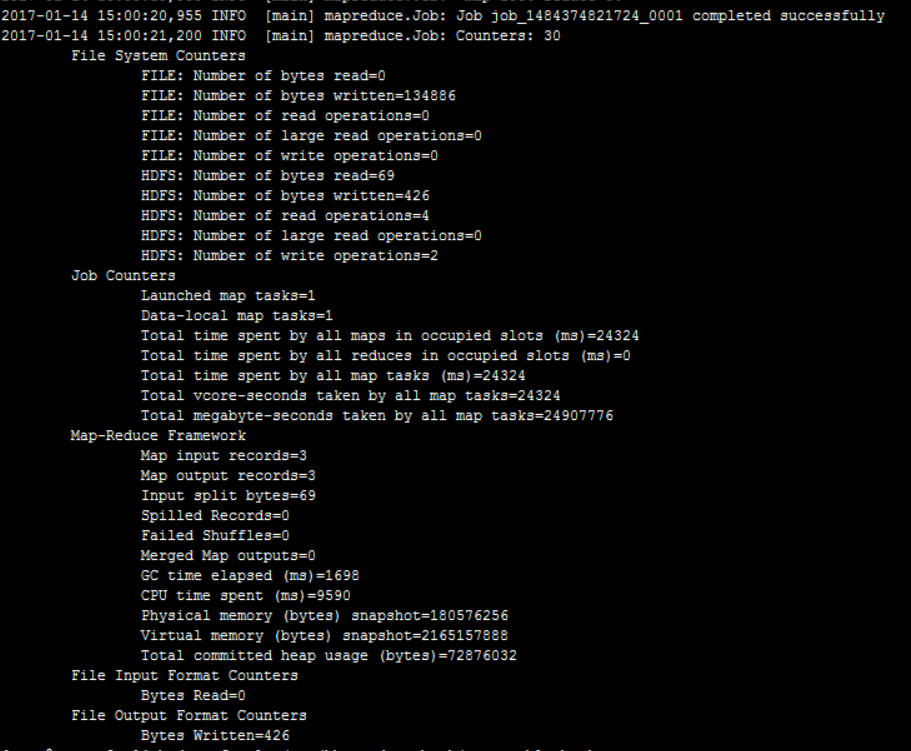
hbase org.apache.hadoop.hbase.mapreduce.Export test_table /opt/hbase-data-back/test_table_back
//hbase org.apache.hadoop.hbase.mapreduce.Driver export test_table /opt/hbase-data-back/test_table_back
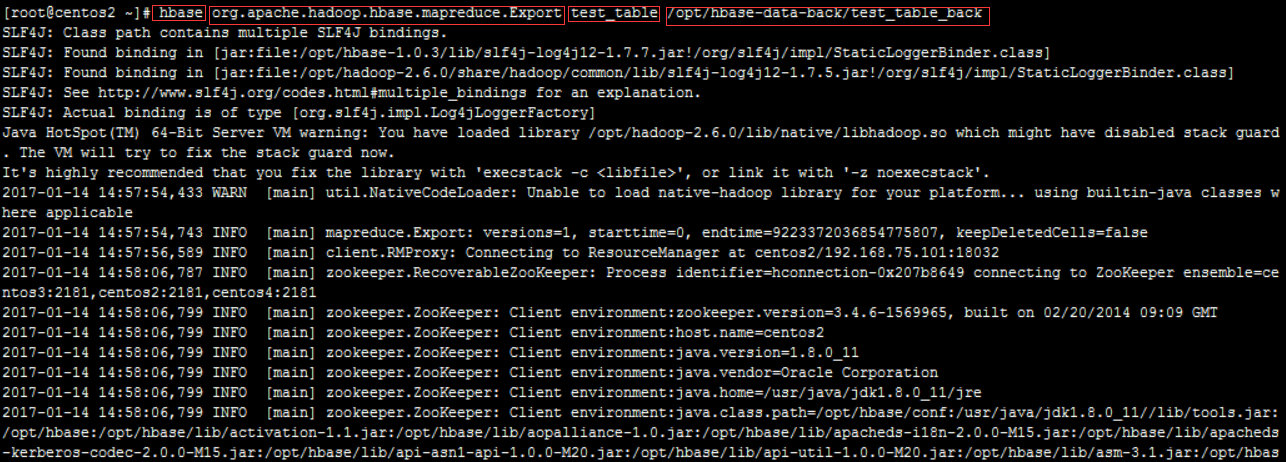
查看文件:
注:上面的路径并不是我最初认为的系统目录,而是hdfs内部的目录。因此在系统中是找不到此文件的。可以通过hdfs的命令查看文件:
hadoop fs -ls /opt/hbase-data-back/test_table_back

注:增量备份:
在最后加上版本号和时间就可以了,时间需要使用数字格式,可使用此页面工具将日期时间转为数字:
http://tool.chinaz.com/Tools/unixtime.aspx
如:
2017-05-19 00:00:00 1495123200000
2017-05-29 00:00:00 1495987200000
/hbase org.apache.hadoop.hbase.mapreduce.Export harve_plate /hdfs/data_back/harve_plate 1 1483200000000 1495123200000
2) 获取hdfs文件到系统
将hdfs中的/opt/hbase-data-back/test_table_back,复制到系统的/opt/hbase-data-back/test_table_back中:
hadoop fs -get /opt/hbase-data-back/test_table_back /opt/hbase-data-back/test_table_back

然后系统中自动创建了一个test_table_back目录
目录中的文件也复制过来了:
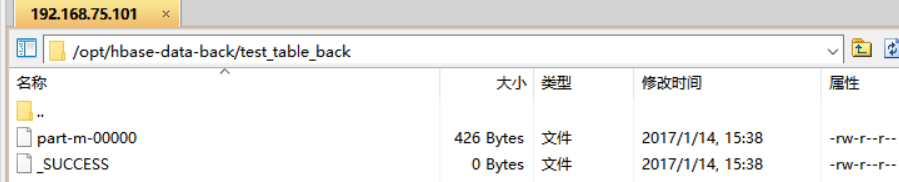
3) 将备份文件添加到hdfs中
将上面的目录复制到新的机器中,通过put将文件上传到hdfs中去。
hadoop dfs -put localFile hdfsFile
如:把系统的/opt/hbase-data-back/test_table_back上传到hdfs的/opt/hbase-data-back/test_table_back2下。

查看/opt/hbase-data-back/test_table_back2下的内容:

4) 导入:
先创建一张一样的表:

hbase org.apache.hadoop.hbase.mapreduce.Import test_table_back /opt/hbase-data-back/test_table_back
网上有人说要这么写(指定从hdfs获取数据):hdfs://l-master.data/opt/hbase-data-back/test_table_back
但不这么写默认就是从hdfs中获取数据。
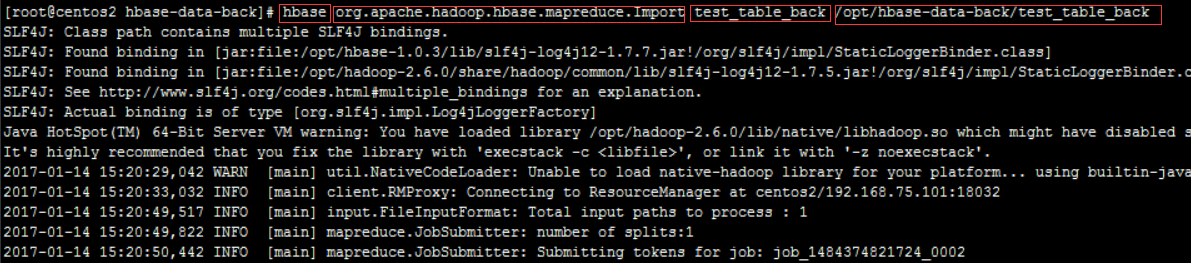
在import时可以指定使用bulk的方式,bulk是生成hfile格式的文件,直接导入到Region,无需经历hbase的写数据过程,从而无需消耗memstore,无需Flush等,更加高效,如果不指定bulk文件路径(hdfs的路径)则会采用hbase的put和delete API进行写入。
$ bin/hbase -Dhbase.import.version=0.94 org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
使用Import工具前必须先创建表,关于hbase.import.version属性是0.96的功能。
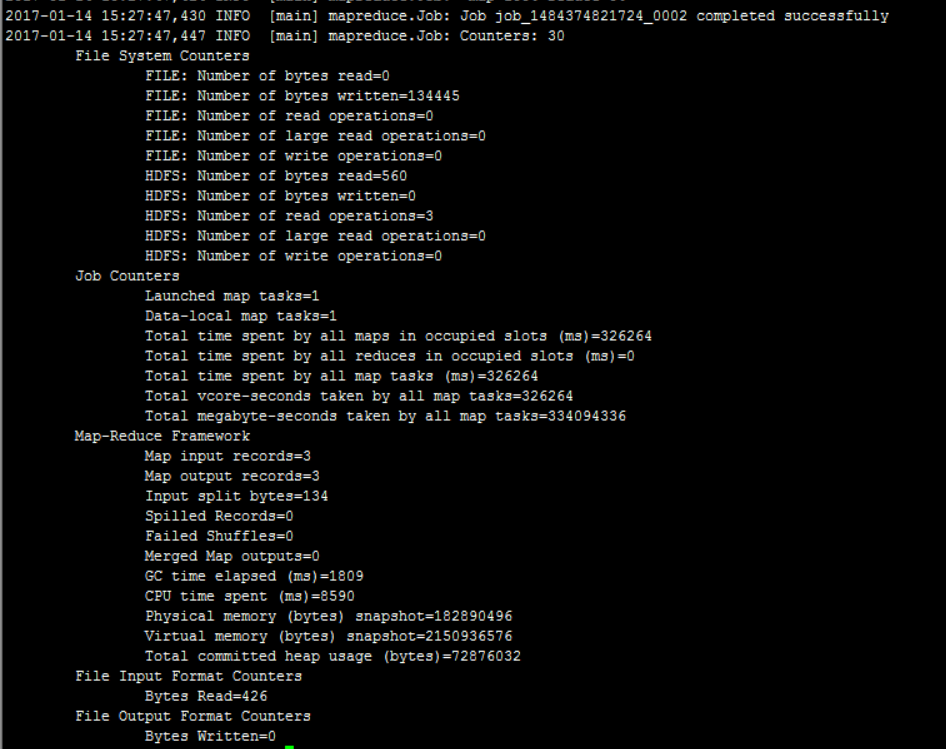
导入结束后查看数据:

导入成功。
5) 大数据量导出
导出user表,接近18万条记录:
/hbs/hbase-1.0.3/bin/hbase org.apache.hadoop.hbase.mapreduce.Export harve_user /hdfs/data_back/harve_user_back

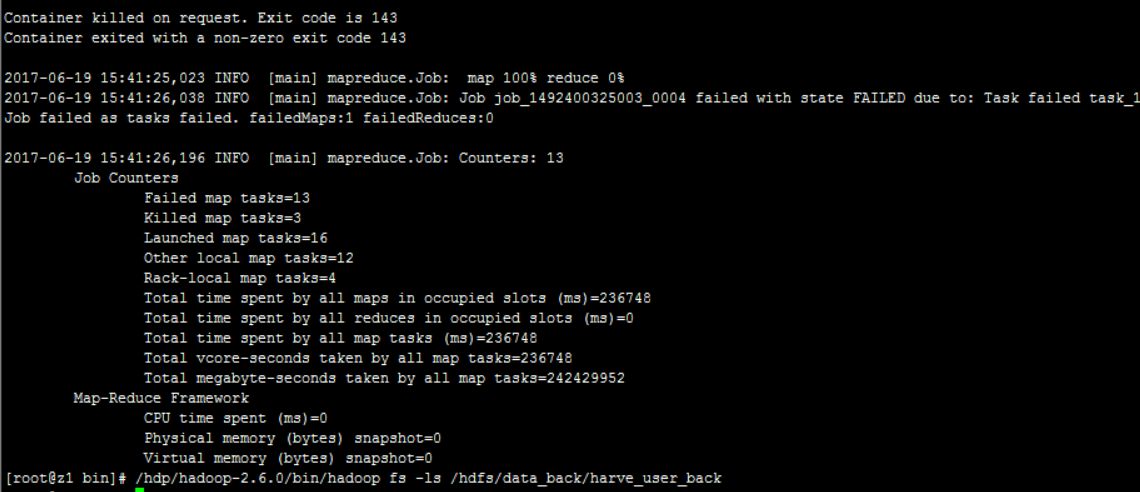
导出失败了,查看hdfs中的内容也是空的:

失败原因:

2017-06-19 15:41:21,996 INFO [main] mapreduce.Job: Task Id : attempt_1492400325003_0004_m_000002_2, Status : FAILED
Container [pid=126946,containerID=container_1492400325003_0004_01_000020] is running beyond virtual memory limits. Current usage: 162.1 MB of 1 GB physical memory used; 2.1 GB of 2.1 GB virtual memory used. Killing container.
机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
该错误是YARN的虚拟内存计算方式导致,上例中用户程序申请的内存为1Gb,YARN根据此值乘以一个比例(默认为2.1)得出申请的虚拟内存的值,当YARN计算的用户程序所需虚拟内存值大于计算出来的值时,就会报出以上错误。调节比例值可以解决该问题。
解决方法:mapred-site.xml中设置map和reduce任务的内存配置如下:(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改)
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
MapReduce作业配置参数
可在客户端的mapred-site.xml中配置,作为MapReduce作业的缺省配置参数。也可以在作业提交时,个性化指定这些参数。
参数名称 | 缺省值 | 说明 |
mapreduce.job.name |
| 作业名称 |
mapreduce.job.priority | NORMAL | 作业优先级 |
yarn.app.mapreduce.am.resource.mb | 1536 | MR ApplicationMaster占用的内存量 |
yarn.app.mapreduce.am.resource.cpu-vcores | 1 | MR ApplicationMaster占用的虚拟CPU个数 |
mapreduce.am.max-attempts | 2 | MR ApplicationMaster最大失败尝试次数 |
mapreduce.map.memory.mb | 1024 | 每个Map Task需要的内存量 |
mapreduce.map.cpu.vcores | 1 | 每个Map Task需要的虚拟CPU个数 |
mapreduce.map.maxattempts | 4 | Map Task最大失败尝试次数 |
mapreduce.reduce.memory.mb | 1024 | 每个Reduce Task需要的内存量 |
mapreduce.reduce.cpu.vcores | 1 | 每个Reduce Task需要的虚拟CPU个数 |
mapreduce.reduce.maxattempts | 4 | Reduce Task最大失败尝试次数 |
mapreduce.map.speculative | false | 是否对Map Task启用推测执行机制 |
mapreduce.reduce.speculative | false | 是否对Reduce Task启用推测执行机制 |
mapreduce.job.queuename | default | 作业提交到的队列 |
mapreduce.task.io.sort.mb | 100 | 任务内部排序缓冲区大小 |
mapreduce.map.sort.spill.percent | 0.8 | Map阶段溢写文件的阈值(排序缓冲区大小的百分比) |
mapreduce.reduce.shuffle.parallelcopies | 5 | Reduce Task启动的并发拷贝数据的线程数目 |
修改配置文件重启后再次执行,成功:
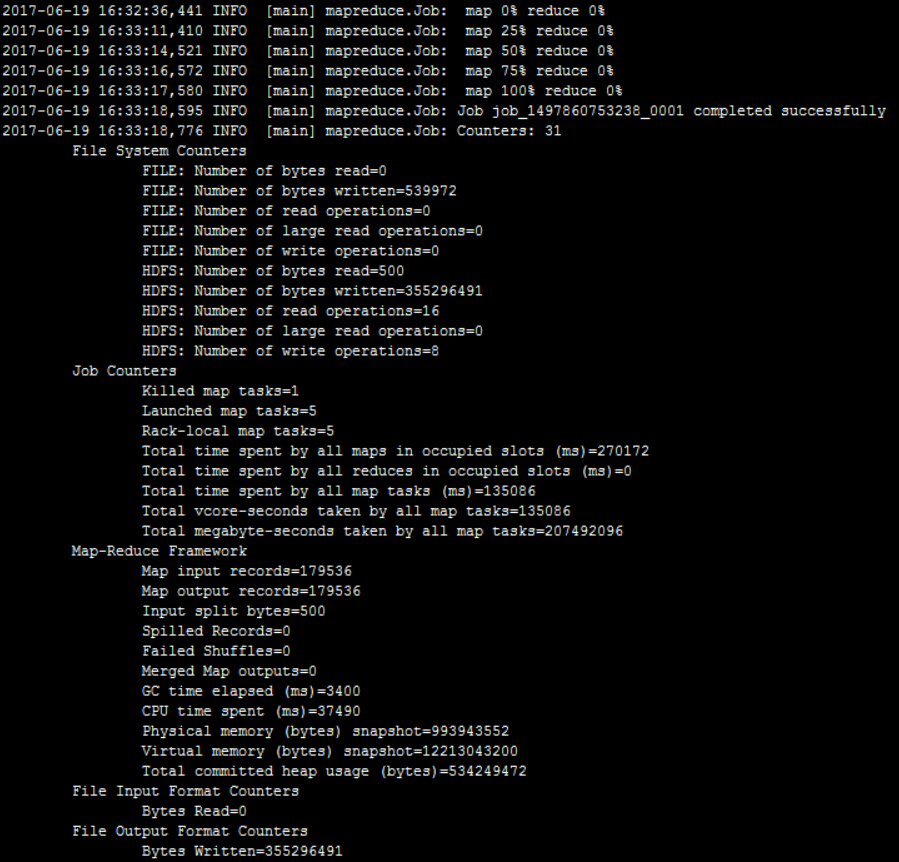
最终导出后共300多M