简介
很多大小公司都在仪表仪器字符读取,比如百度https://ai.baidu.com/tech/ocr/meter
使用仪器仪表盘读数识别技术,可对采集到的仪器仪表数值信息自动识别,并快速录入到业务系统中,有效解决人工抄录过程中抄错、抄漏等问题,提升抄录效率,减少人工录入工作量,降低企业人力成本,实现仪器仪表数据录入的自动化
基础的OCR流程
框出图像
将待识别的文字区域用框在图像中框出来,如下图所示: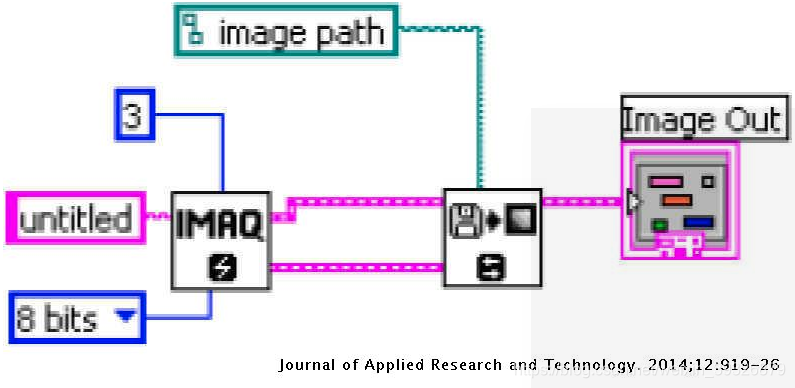
第一步例程图像如下图所示:
图像预处理(二值化)
二值化是通过使用阈值将灰度图像(0至255像素值)转换为二进制图像(0至1像素值)的过程。比阈值浅的像素变为白色,其余部分变为黑色像素。在这项工作中,已使用阈值为175的全局阈值对图像进行二值化,即从175到255的像素值已转换为1,而灰度值小于175的像素的像素值已转换为1。转换为0。LabVIEW二值化程序如图2所示。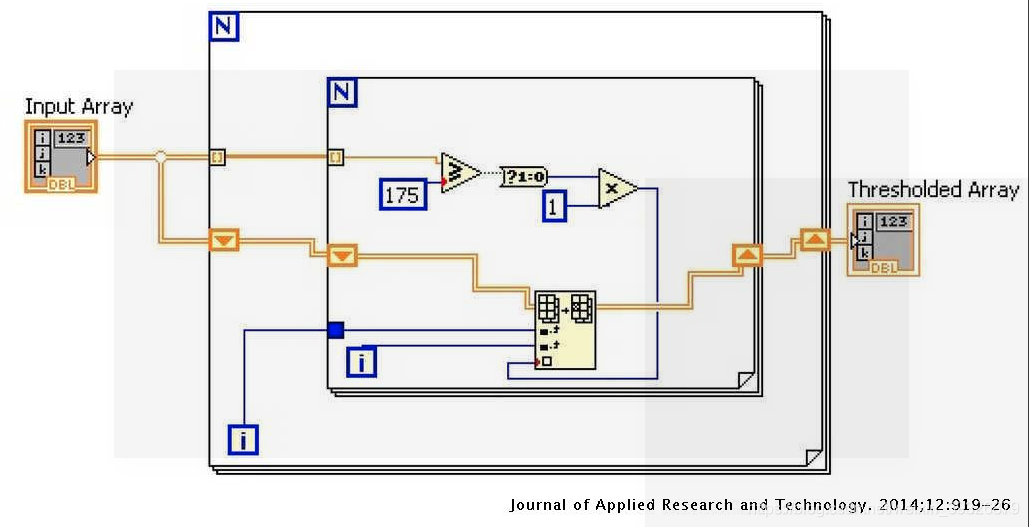

图像分割
分割过程包括行分割,单词分割和最后的字符分割。
行分割是分割过程的第一步。它以图像阵列作为输入,并水平扫描图像以找到第一个ON像素,并将该坐标记为y1。系统将继续水平扫描图像并发现许多ON像素,因为这些字符已经开始。当最终检测到第一个OFF像素时,系统会将坐标记为y2并检查像素周围,以找出所需数量的OFF像素。如果发生这种情况,则系统会在坐标y1和y2之间剪切输入图像中的第一条线(fl)。这样,所有行都已被分割并存储以用于单词和字符分割。线段的LabVIEW程序如图3所示。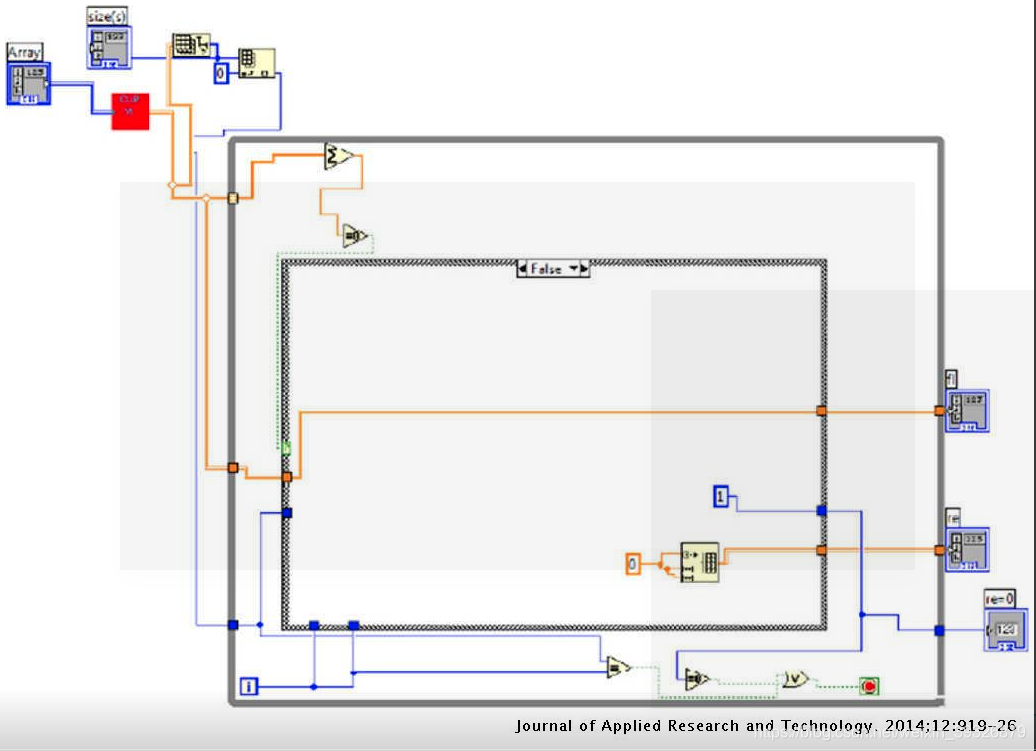

分词
在分词过程中,已对行分割的图像进行了垂直扫描,以找到第一个ON像素。发生这种情况时,系统会将该点的坐标记为x1。这是单词的起始坐标。系统继续扫描过程,直到获得十五个(假定为字距)连续的OFF像素为止。系统将第一个OFF像素记录为x2。从x1到x2是这个词。这样,所有单词都被分割了,这些分割后的单词已在下一步中用于字符识别。在图4中示出了分词的LabVIEW的程序。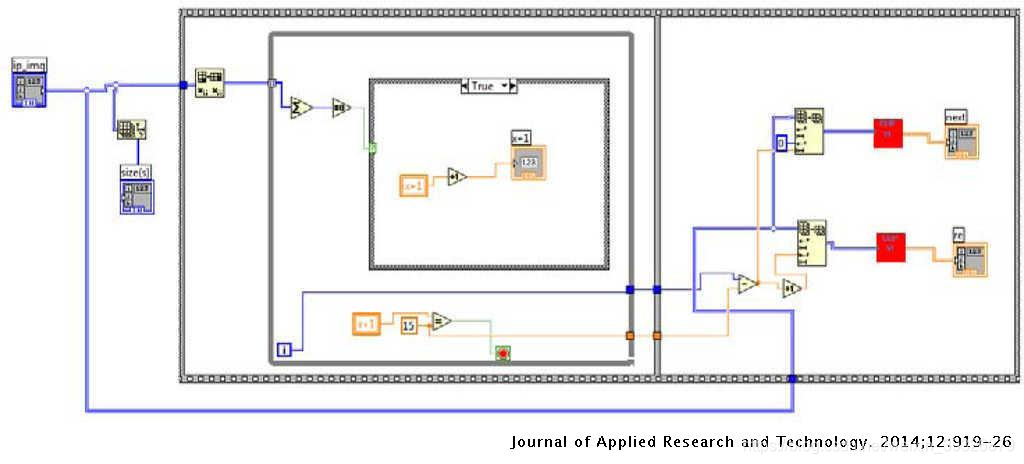

字符分割
通过垂直扫描单词分割图像来执行字符分割。此过程在以下两个方面不同于分词:
与字符之间的OFF像素数量相比,不同字符之间的水平OFF像素数量更少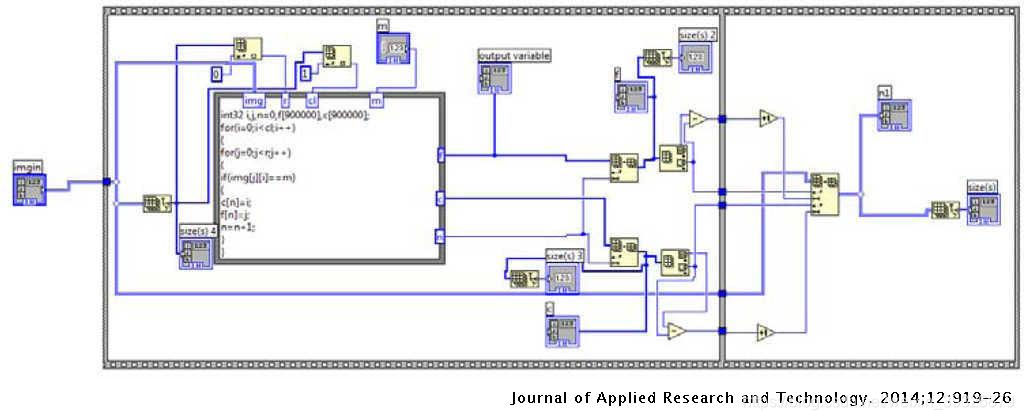

匹配和识别
在此过程中,已通过使用关联VI获得了存储的模板和分段字符之间的关联。相关性VI确定分段字符与每个字符的存储模板之间的相关性。最高相关性的值可识别特定字符。以这种方式,为了识别字符,已经将每个分割的字符与存储在系统中的预定数据进行比较。由于已使用相同的字体大小进行识别,因此已获得每个字符的唯一匹配。图6显示了两个图像之间的关联的LabVIEW程序。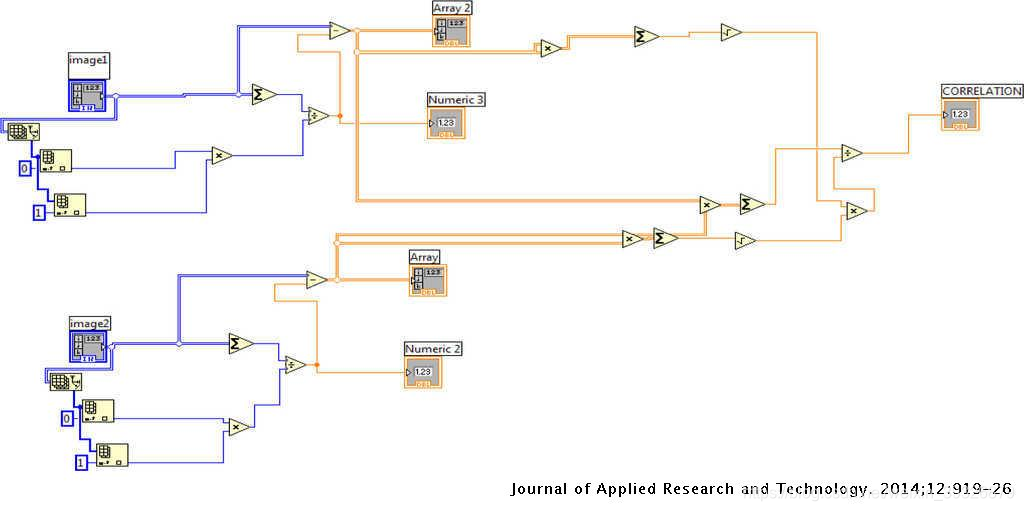

ocr的整体流程图如下图所示: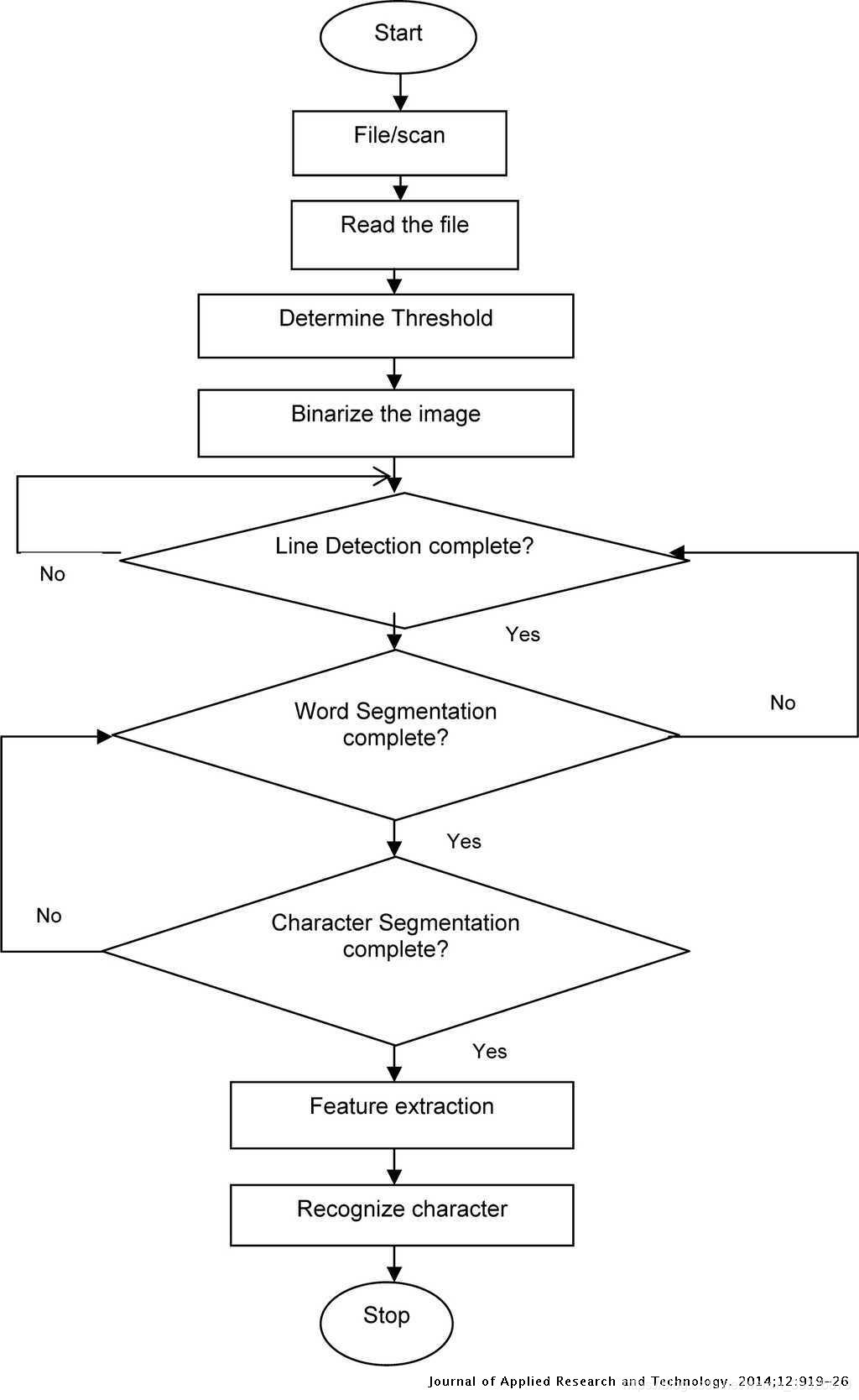
以上只是基于传统的OCR识别方法,预处理+分割+机器学习识别;
现在比较流行的是深度学习的方法:
CNN+LSTM+CTC
数字型仪表
其主要步骤如下:
1.仪表检测
2.数字区域分割
3.数字检测
指针型仪表
部署
部署可以采用mnn部署到嵌入上(参考:https://zhuanlan.zhihu.com/p/70323042)
嵌入式端和PC端的区别可见:
https://zhuanlan.zhihu.com/p/70323042