概述
整理和研究通用CPU算力和异构GPU/ASIC芯片算力的区别。
CPU工作方式及算力测算
CPU工作原理
SRAM: Static Random Access Memory ,静态随机存取存储器, volatile memory易失性存储,不需要刷新电路即能保存它内部存储的数据。L2 Cache。
DRAM: Dynamic Random Access Memory,动态随机存取器,volatile memory,刷新电路保存它内部存储的数据。
SDRAM: Synchronous Dynamic Random Memory,同步动态随机存取内存。对进入的指令进行管线(Pipeline)操作,管线意味着芯片可以在处理完之前的指令前,接受一个新的指令。
易失性存储器(Volatile Memory,VM),电源关闭,资料丢失,如SRAM、DRAM、SDAM、DDR-SDRAM等;
非易失性存储器(Non-Volatile Memory,NVM):电源关闭,资料任然可以保留,如ROM等。
CPU组成
CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。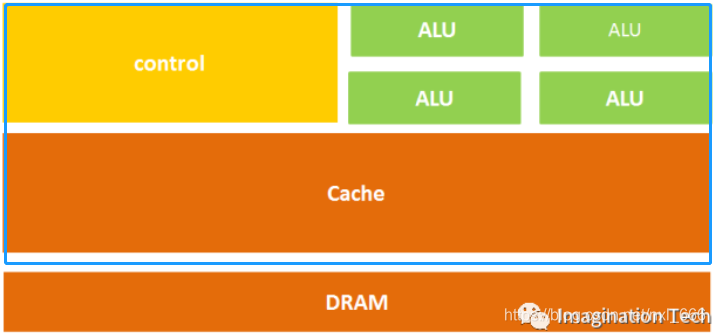
CPU运行过程,下面链接的文章讲的比较清楚。
传送门转载:https://blog.csdn.net/dong_daxia/article/details/80289951。
补充:编译过程
事实上,仅仅将程序通过编译改写成汇编指令或机器指令,在操作系统上还不能直接运行。实际上广义的编译,其实包括预处理、编译、汇编、链接这整个过程。
- 预处理,就是把代码里引入的其他代码,插入到这段代码中,形成一个代码文件。
- 编译,就是把代码转化为汇编指令的过程,汇编指令只是CPU相关的,也就是说C代码和python代码,代码逻辑如果相同,编译完的结果其实是一样的。
- 汇编,就是把汇编指令转为机器码的过程,机器码可以被CPU直接执行。
- 链接,就是将一段我们需要的已经编译好的其他库,与我们的汇编结果连起来,这样才是最终程序完整的形式,操作系统才可以运行。不同操作系统编译好的其他库形式不同,而且链接的方式也不同,得到最终程序的形式也不同,所以编译好的程序只能在特定的操作系统下运行。
CPU算力测算
算力=CPU核心*时钟频率*单时钟周期执行浮点操作数
# FP64 双精度计算
# 支持AVX2的处理器的单指令的长度是256bit,每个intel核心假设包含2个FMA,一个FMA一个时钟周期可以进行2次乘或者加的运算,那么这个处理器在1个核心1个时钟周期可以执行 `256bit*2FMA*2M/A/64=16` 次浮点运算,也称为16FLOPs,就是Floating Point Operations Per Second;
# 支持AVX512的处理器的单指令的长度是512Bit,每个intel核心假设包含2个FMA,一个FMA一个时钟周期可以进行2次乘或者加的运算,那么这个处理器在1个核心1个时钟周期可以执行 `512bit*2FMA*2M/A/64=32` 次浮点运算,也称为32FLOPs。
例子:
现在intel purley platform的旗舰skylake 8180是28Core@2.5GHZ,支持AVX512,其理论双精度浮点性能是:28Core*2.5GHZ*32FLOPs/Cycle=2240GFLPs=2.24TFLOPs。
MOPS(Million Operation Per Second),1MOPS代表处理器每秒钟可进行一百万次(10^6)操作;
GOPS(Giga Operations Per Second),1GOPS代表处理器每秒钟可进行十亿次(10^9)操作;
TOPS(Tera Operations Per Second),1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作;
Pops(Peta Operation Per Second),1POPS代表处理器每秒钟可进行千万亿次(10^15)操作;
Eops(Exa Operation Per Second),1EOPS代表处理器每秒钟可进行百亿亿次(10^18)操作;
参考链接:https://baike.baidu.com/item/数量级/3289119?fr=aladdin
GPU能做的CPU都能做,CPU能做的GPU却不一定能够做到,GPU一般一个时钟周期可以操作64bit的数据,1个核心实现1个FMA。
这个GPU的计算能力的单元是:64bit1FMA2M/A/64bit=2FLOPs/Cycle
GPU的计算能力也是一样和核心个数,核心频率,核心单时钟周期能力三个因素有关。
但是架不住GPU的核心的数量多呀
例如:对现在nvidia tesla class 的pascal旗舰 p100而言,是1792core@1.328GHZ,其理论的双精度浮点性能是:1792Core1.328GHZ2FLOPs/Cycle=4759.552GFLOPs=4.7TFLOPs
CPU和GPU区别
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。;
SISD全称Single instruction, Single data,单指令流单数据流,每个指令部件每次仅译码一条指令,而且在执行时仅为操作部件提供一份数据。
CPU和GPU之所以大不相同,是由于其设计目标的不同,它们分别针对了两种不同的应用场景。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。而GPU面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。
什么类型的程序适合在CPU上运行?
- I/O intensive
- Memory intensive
什么类型的程序适合在GPU上运行? - 计算密集型的程序。所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
- 易于并行的程序。GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。