C++:字符串和字符文本
前言
C++ 支持各种字符串和字符类型,并提供表示每种类型的文本值的方法。 在源代码中,使用字符集表示字符和字符串文本的内容。 通用字符名称和转义字符允许你仅使用基本源字符集表示任何字符串。 原始字符串使你可以避免使用转义字符,可以用于表示所有类型的字符串。 你还可以创建 std::string 文本,而无需执行额外的构造或转换步骤。
#include <string>
using namespace std::string_literals; // enables s-suffix for std::string literals
int main()
{
// Character literals
auto c0 = 'A'; // char
auto c1 = u8'A'; // char
auto c2 = L'A'; // wchar_t
auto c3 = u'A'; // char16_t
auto c4 = U'A'; // char32_t
// Multicharacter literals
auto m0 = 'abcd'; // int, value 0x61626364
// String literals
auto s0 = "hello"; // const char*
auto s1 = u8"hello"; // const char*, encoded as UTF-8
auto s2 = L"hello"; // const wchar_t*
auto s3 = u"hello"; // const char16_t*, encoded as UTF-16
auto s4 = U"hello"; // const char32_t*, encoded as UTF-32
// Raw string literals containing unescaped \ and "
auto R0 = R"("Hello \ world")"; // const char*
auto R1 = u8R"("Hello \ world")"; // const char*, encoded as UTF-8
auto R2 = LR"("Hello \ world")"; // const wchar_t*
auto R3 = uR"("Hello \ world")"; // const char16_t*, encoded as UTF-16
auto R4 = UR"("Hello \ world")"; // const char32_t*, encoded as UTF-32
// Combining string literals with standard s-suffix
auto S0 = "hello"s; // std::string
auto S1 = u8"hello"s; // std::string
auto S2 = L"hello"s; // std::wstring
auto S3 = u"hello"s; // std::u16string
auto S4 = U"hello"s; // std::u32string
// Combining raw string literals with standard s-suffix
auto S5 = R"("Hello \ world")"s; // std::string from a raw const char*
auto S6 = u8R"("Hello \ world")"s; // std::string from a raw const char*, encoded as UTF-8
auto S7 = LR"("Hello \ world")"s; // std::wstring from a raw const wchar_t*
auto S8 = uR"("Hello \ world")"s; // std::u16string from a raw const char16_t*, encoded as UTF-16
auto S9 = UR"("Hello \ world")"s; // std::u32string from a raw const char32_t*, encoded as UTF-32
}
字符串文本可以米有前缀,也可以具有 u8、 L、 u和 U 前缀以分别指示窄字符(单字节或多字节)、UTF-8、宽字符(UCS-2 或 UTF-16)、UTF-16 和 UTF-32 编码。 R u8R LR uR UR 对于这些编码的原始版本等效项,原始字符串文本可以具有、、、和前缀。 若要创建临时或静态 std::string 值,可以使用带后缀的字符串文本或原始字符串文本 s 。
字符文本
字符文本 由一个字符常量构成。 它由用单引号引起来的字符表示。 有五种类型的字符文本:
类型的普通字符文本 char ,例如’a’
类型为的 UTF-8 字符文本 char ( char8_t c + + 20),例如u8’a’
类型的宽字符文本 wchar_t ,例如L’a’
类型的 UTF-16 字符文本 char16_t ,例如u’a’
类型为的 UTF-32 字符文本 char32_t ,例如U’a’
用于字符文本的字符可以是除保留字符反斜杠( \ )、单引号( ’ )或换行符之外的任何字符。 可以使用转义序列指定保留字符。 可以通过使用通用字符名称指定字符,只要类型的大小足以保留字符。
编码
字符文本根据其前缀以不同的方式进行编码。
不带前缀的字符文本是普通字符文本。 包含可在执行字符集中表示的单个字符、转义序列或通用字符名称的普通字符文本值具有等于其编码在执行字符集中的数值的值。 包含多个字符、转义序列或通用字符名称的普通字符文本是一个多字符文本。 不能用执行字符集表示的多字符文本或普通字符文本具有类型 int ,其值是实现定义的。
以前缀开头的字符文本 L 是宽字符文本。 包含单个字符、转义序列或通用字符名称的宽字符文本的值的值等于其编码在执行宽字符集中的数值,除非字符文本在执行宽字符集中没有表示形式,在这种情况下,该值是实现定义的。 包含多个字符、转义序列或通用字符名称的宽字符文本的值是实现定义的
以前缀开头的字符文本 u8 是 utf-8 字符文本。 如果 UTF-8 字符文本包含一个字符、转义序列或通用字符名称,则其值等于其 ISO 10646 码位值(如果它可由单个 UTF-8 代码单元表示(对应于 C0 控件和基本拉丁语 Unicode 块)。 如果值不能由单个 UTF-8 代码单元表示,则程序格式不正确。 包含多个字符、转义序列或通用字符名称的 UTF-8 字符文本格式错误。
以前缀开头的字符文本 u 是 utf-16 字符文本。 如果 UTF-16 字符文本包含一个字符、转义序列或通用字符名称,则其值等于其 ISO 10646 码位值,前提是它可由单个 UTF-16 代码单元(对应于基本多语言平面)表示。 如果值不能由单个 UTF-16 代码单元表示,则程序格式不正确。 包含多个字符、转义序列或通用字符名称的 UTF-16 字符文本格式错误。
以前缀开头的字符文本 U 是一个 UTF-32 字符文本。 包含一个字符、转义序列或通用字符名称的 UTF-32 字符文本的值的值等于其 ISO 10646 代码点值。 包含多个字符、转义序列或通用字符名称的32字符串格式不正确。
转义序列
有三种类型的转义序列:简单、八进制和十六进制。 转义序列可以是以下任一值: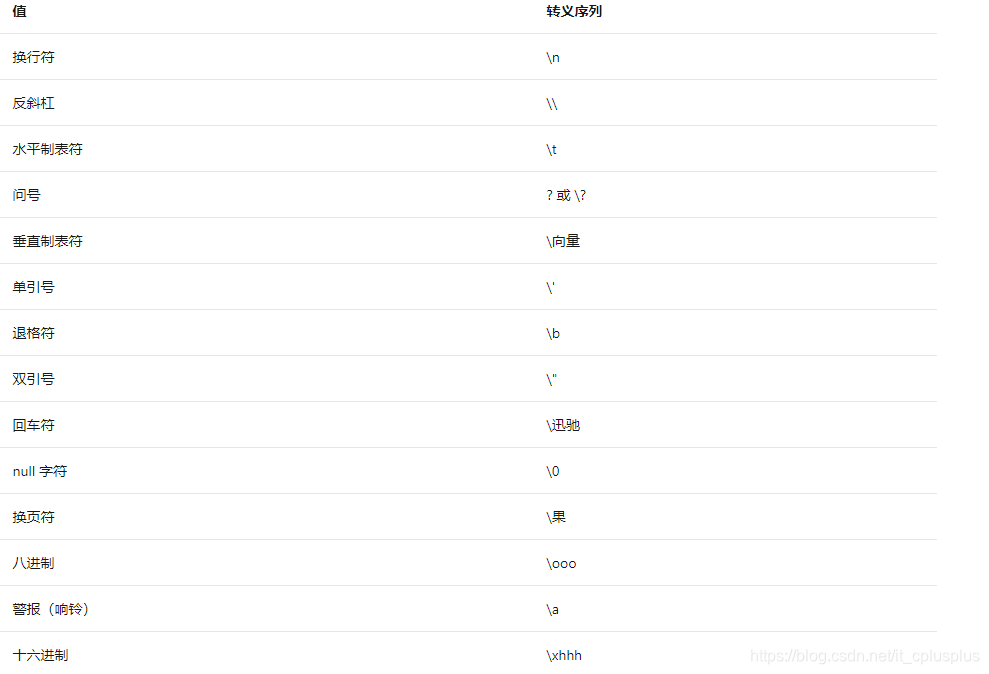
八进制转义序列是一个反斜杠,后跟一到三个八进制数字的序列。 如果早于第三个数字,则八进制转义序列在第一个不是八进制数字的字符处终止。 可能的最高八进制值为 \377 。
十六进制转义序列是一个反斜杠,后跟字符 x ,再后跟一个或多个十六进制数字的序列。 将忽略前导零。 在普通或 u8 前缀的字符文本中,最大的十六进制值为0xFF。 在使用 L 或 u 前缀的宽字符文本中,最大的十六进制值为 0xFFFF。 在使用 U 前缀的宽字符文本中,最大的十六进制值为 0xFFFFFFFF。
此示例代码演示了使用普通字符文本的转义字符的一些示例。 相同的转义序列语法对其他字符文本类型有效。
#include <iostream>
using namespace std;
int main() {
char newline = '\n';
char tab = '\t';
char backspace = '\b';
char backslash = '\\';
char nullChar = '\0';
cout << "Newline character: " << newline << "ending" << endl;
cout << "Tab character: " << tab << "ending" << endl;
cout << "Backspace character: " << backspace << "ending" << endl;
cout << "Backslash character: " << backslash << "ending" << endl;
cout << "Null character: " << nullChar << "ending" << endl;
}
/* Output:
Newline character:
ending
Tab character: ending
Backspace character:ending
Backslash character: \ending
Null character: ending
*/
反斜杠字符( \ )位于行尾时是行继续符。 如果希望反斜杠字符显示为字符文本,则必须在一行中键入两个反斜杠( \ )。
Microsoft 专用
若要从窄多字符文本创建值,编译器将单引号之间的字符或字符序列转换为32位整数内的8位值。 文本中的多个字符根据需要从高序位到低序位填充相应字节。 然后,编译器会按照常规规则将整数转换为目标类型。 例如,若要创建 char 值,编译器需要使用低序位字节。 若要创建 wchar_t 或 char16_t 值,编译器采用低序位字。 如果在分配的字节或字上设置了任何位,则编译器会警告结果被截断。
char c0 = 'abcd'; // C4305, C4309, truncates to 'd'
wchar_t w0 = 'abcd'; // C4305, C4309, truncates to '\x6364'
int i0 = 'abcd'; // 0x61626364
显示为包含三个以上位数的八进制转义序列被视为三位数八进制序列,后跟作为多字符文本中字符的后续数字,这可能会产生令人吃惊的结果。 例如:
char c1 = '\100'; // '@'
char c2 = '\1000'; // C4305, C4309, truncates to '0'
显示为包含非八进制字符的转义序列将作为八进制序列向上计算,直到最后一个八进制字符,后跟剩余字符作为多字符文本中的后续字符。 如果第一个非八进制字符是十进制数字,则会生成警告 C4125。 例如:
char c3 = '\009'; // '9'
char c4 = '\089'; // C4305, C4309, truncates to '9'
char c5 = '\qrs'; // C4129, C4305, C4309, truncates to 's'
一个八进制转义序列,其值大于 \377 导致错误 C2022: “值的小数位数”:字符太大。
显示为具有十六进制和非十六进制字符的转义序列将作为多字符文本进行计算,其中包含直到最后一个十六进制字符的十六进制转义序列,后跟非十六进制字符。 不包含十六进制数字的十六进制转义序列将导致编译器错误 C2153: “十六进制文本必须至少有一个十六进制数字”。
char c6 = '\x0050'; // 'P'
char c7 = '\x0pqr'; // C4305, C4309, truncates to 'r'
如果以为前缀的宽字符文本 L 包含多字符序列,则会从第一个字符中获取值,并且编译器会引发警告 C4066。 将忽略后续字符,这与等效普通多字符文本的行为不同。
wchar_t w1 = L'\100'; // L'@'
wchar_t w2 = L'\1000'; // C4066 L'@', 0 ignored
wchar_t w3 = L'\009'; // C4066 L'\0', 9 ignored
wchar_t w4 = L'\089'; // C4066 L'\0', 89 ignored
wchar_t w5 = L'\qrs'; // C4129, C4066 L'q' escape, rs ignored
wchar_t w6 = L'\x0050'; // L'P'
wchar_t w7 = L'\x0pqr'; // C4066 L'\0', pqr ignored
Microsoft 特定部分在此处结束。
通用字符名称
在字符文本和本机(非原始)字符串文本中,任何字符都可由通用字符名称表示。 通用字符名称由前缀 \U 后跟八位数 unicode 码位组成,或者由前缀 \u 后跟四位数 unicode 码位组成。 必须分别显示所有八个或四个数字,以组成一个格式正确的通用字符名称。
char u1 = 'A'; // 'A'
char u2 = '\101'; // octal, 'A'
char u3 = '\x41'; // hexadecimal, 'A'
char u4 = '\u0041'; // \u UCN 'A'
char u5 = '\U00000041'; // \U UCN 'A'
代理项对
通用字符名称不能对代理项码位范围 D800-DFFF 中的值进行编码。 对于 Unicode 代理项对,通过使用 \UNNNNNNNN(其中,NNNNNNNN 是字符的八位数码位)指定通用字符名称。 如果需要,编译器将生成代理项对。
在 C++03 中,语言只允许字符串子集通过其通用字符名称来表示,并且允许某些实际不表示任何有效 Unicode 字符的通用字符名称。 此错误已在 c + + 11 标准中解决。 在 C++ 11 中,字符以及字符串文本和标识符可以使用通用字符名称。
字符串文本
字符串文本表示字符序列,这些字符合起来可组成以 null 结尾的字符串。 字符必须放在双引号之间。 字符串文本有以下类型:
窄字符串文本
窄字符串是一个非前缀的、双引号分隔、以 null 结尾的类型为的数组 const char[n] ,其中 n 是数组的长度(以字节为单位)。 窄字符串文本可包含除双引号 (")、反斜杠 () 或换行符以外的所有图形字符。 窄字符串文本还可包含上面列出的转义序列和装入一个字节中的通用字符名称。
const char *narrow = "abcd";
// represents the string: yes\no
const char *escaped = "yes\\no";
UTF-8 编码的字符串
UTF-8 编码的字符串是 u8 前缀的双引号分隔的、以 null 结尾的类型为的数组 const char[n] ,其中n是编码数组的长度(以字节为单位)。 以 u8 为前缀的字符串文本可包含除双引号 (")、反斜杠 () 或换行符以外的所有图形字符。 以 u8 为前缀的字符串文本还可包含上面列出的转义序列和任何通用字符名称。
const char* str1 = u8"Hello World";
const char* str2 = u8"\U0001F607 is O:-)";
宽字符串文本
宽字符串文本是一个以 null 结尾的常数数组,其 wchar_t 前缀为 " L ",包含除双引号( " )、反斜杠( \ )或换行符以外的任何图形字符。 宽字符串文本可包含上面列出的转义序列和任何通用字符名称。
const wchar_t* wide = L"zyxw";
const wchar_t* newline = L"hello\ngoodbye";
char16_t 和 char32_t (C++11)
C + + 11 引入了可移植的 char16_t (16位 unicode)和 char32_t (32位 unicode)字符类型:
auto s3 = u"hello"; // const char16_t*
auto s4 = U"hello"; // const char32_t*
原始字符串文本(c + + 11)
原始字符串文本是一个以 null 结尾的数组,其中包含任何图形字符,其中包括双引号( " )、反斜杠( \ )或换行符。 原始字符串通常用于使用字符类的正则表达式,还用于 HTML 字符串和 XML 字符串。
// represents the string: An unescaped \ character
const char* raw_narrow = R"(An unescaped \ character)";
const wchar_t* raw_wide = LR"(An unescaped \ character)";
const char* raw_utf8 = u8R"(An unescaped \ character)";
const char16_t* raw_utf16 = uR"(An unescaped \ character)";
const char32_t* raw_utf32 = UR"(An unescaped \ character)";
分隔符是用户定义的最多包含16个字符的序列,该序列紧靠在原始字符串文本的左括号之前,并紧跟在其右括号之后。 例如,在 R"abc(Hello"()abc" 中,分隔符序列为 abc ,字符串内容为 Hello"(。 你可使用分隔符来消除同时含有双引号和括号的原始字符串。 此字符串文本导致编译器错误:
// meant to represent the string: )"
const char* bad_parens = R"()")"; // error C2059
但分隔符能够解决这样的错误:
const char* good_parens = R"xyz()")xyz";
可以在源中构造包含换行符(而非转义字符)的原始字符串文本:
// represents the string: hello
//goodbye
const wchar_t* newline = LR"(hello
goodbye)";
std:: string 文本(c + + 14)
std::string文本是用户定义的文本(见下文)的标准库实现,表示为 "xyz"s (带有 s 后缀)。 这种类型的字符串会生成类型为、、或的临时对象 std::string std::wstring std::u32string std::u16string ,具体取决于指定的前缀。 如果未使用任何前缀, std::string 则会生成。 L"xyz"s生成一个 std::wstring 。 u"xyz"s生成std:: u16string,并 U"xyz"s 生成std:: u32string。
//#include <string>
//using namespace std::string_literals;
string str{ "hello"s };
string str2{ u8"Hello World" };
wstring str3{ L"hello"s };
u16string str4{ u"hello"s };
u32string str5{ U"hello"s };
s后缀还可以用于原始字符串文本:
u32string str6{ UR"(She said "hello.")"s };
std::string在 std::literals::string_literals 标头文件的命名空间中定义文本 。 因为 std::literals::string_literals 和 std::literals 都声明为内联命名空间,所以 std::literals::string_literals 自动视为它直接属于命名空间 std 。
字符串文本的大小
对于 ANSI char* 字符串和其他单字节编码(但不是 utf-8),字符串文本的大小(以字节为单位)是终止 null 字符的字符数加1。 对于所有其他字符串类型,大小不与字符数严格相关。 UTF-8 使用最多四个 char 元素对某些代码单元进行编码, char16_t 或 wchar_t 编码为 utf-16 可能使用两个元素(共四个字节)对单个代码单元进行编码。 本示例演示了宽字符串文本的大小(以字节为单位):
const wchar_t* str = L"Hello!";
const size_t byteSize = (wcslen(str) + 1) * sizeof(wchar_t);
请注意, strlen() 和 wcslen() 不包含终止 null 字符的大小,其大小等于字符串类型的元素大小:一个或字符串上有一个字节 char* char8_t* ,或字符串上有两个字节 wchar_t* ,字符串上有四个 char16_t* 字节 char32_t* 。
字符串文本的最大长度为65535个字节。 此限制适用于窄字符串文本和宽字符串文本。
修改字符串文本
因为字符串文本(不包括 std::string 文本)是常量,所以尝试修改它们(例如) str[2] = ‘A’ 会导致编译器错误。
Microsoft 专用
在 Microsoft c + + 中,可以使用字符串文本将指针初始化为非常量 char 或 wchar_t 。 此非常量初始化在 C99 代码中是允许的,但在 c + + 98 中已弃用,并在 c + + 11 中已删除。 尝试修改该字符串将导致访问冲突,例如:
wchar_t* str = L"hello";
str[2] = L'a'; // run-time error: access violation
当您设置 /Zc:strictStrings (禁用字符串文本类型转换)编译器选项时,如果字符串文本转换为非常量字符指针,则可以导致编译器发出错误。 我们建议将其用于符合标准的可移植代码。 使用关键字声明经过字符串文本初始化的指针也是一种很好的做法 auto ,因为它解析为正确的(const)类型。 例如,此代码示例捕捉到一次在编译时写入字符串文本的尝试:
auto str = L"hello";
str[2] = L'a'; // C3892: you cannot assign to a variable that is const.
在某些情况下,可以合并相同的字符串文本,节省可执行文件的空间。 字符串文本合并过程中,编译器将导致对特定字符串文本的所有引用都指向内存中的同一位置,而不是每次引用都指向一个单独的字符串文本实例。 若要启用字符串池,请使用 /GF 编译器选项。
Microsoft 特定部分在此处结束。
串联相邻字符串文本
相邻宽或窄字符串文本是串联的。 声明如下:
char str[] = "12" "34";
与此声明相同:
char atr[] = "1234";
也和此声明相同:
char atr[] = "12\
34";
使用嵌入式十六进制转义代码来指定字符串会导致意外的结果。 以下示例旨在创建包含 ASCII 5 字符、后跟字符 f、i、v 和 e 的字符串文本:
"\x05five"
实际结果是十六进制 5F,它是一个下划线 ASCII 代码,后跟字符 i、v 和 e。 若要获得正确的结果,可以使用以下转义序列之一:
"\005five" // Use octal literal.
"\x05" "five" // Use string splicing.
std::string文本,因为它们是 std::string 类型,可以与 + 为类型定义的运算符连接在一起 basic_string 。 它们还可以通过与相邻字符串相同的方式进行串联。 在两种情况下,字符串编码和后缀都必须匹配:
auto x1 = "hello" " " " world"; // OK
auto x2 = U"hello" " " L"world"; // C2308: disagree on prefix
auto x3 = u8"hello" " "s u8"world"s; // OK, agree on prefixes and suffixes
auto x4 = u8"hello" " "s u8"world"z; // C3688, disagree on suffixes
具有通用字符名称的字符串文本
本机(非原始)字符串文本可能使用通用字符名称来表示任何字符,只要通用字符名称可被编码为字符串类型中的一个或多个字符。 例如,表示扩展字符的通用字符名称不能在使用 ANSI 代码页的窄字符串进行编码,但可以在某些多字节代码页或 UTF-8 字符串或宽字符串中的窄字符串进行编码。 在 c + + 11 中,通过 char16_t* 和字符串类型扩展了 Unicode 支持 char32_t* :
// ASCII smiling face
const char* s1 = ":-)";
// UTF-16 (on Windows) encoded WINKING FACE (U+1F609)
const wchar_t* s2 = L"? = \U0001F609 is ;-)";
// UTF-8 encoded SMILING FACE WITH HALO (U+1F607)
const char* s3 = u8"? = \U0001F607 is O:-)";
// UTF-16 encoded SMILING FACE WITH OPEN MOUTH (U+1F603)
const char16_t* s4 = u"? = \U0001F603 is :-D";
// UTF-32 encoded SMILING FACE WITH SUNGLASSES (U+1F60E)
const char32_t* s5 = U"? = \U0001F60E is B-)";
该博文为原创文章,未经博主同意不得转载,如同意转载请注明博文出处
本文章博客地址:https://blog.csdn.net/it_cplusplus/article/details/118090532