1、窗口介绍
SparkStreaming是基于spark core 的实时架构,虽然SparkStreaming可以进行实时计算,但它并不是一个纯实时计算框架。StreamingContext的批次间隔决定了每隔多久计算一次。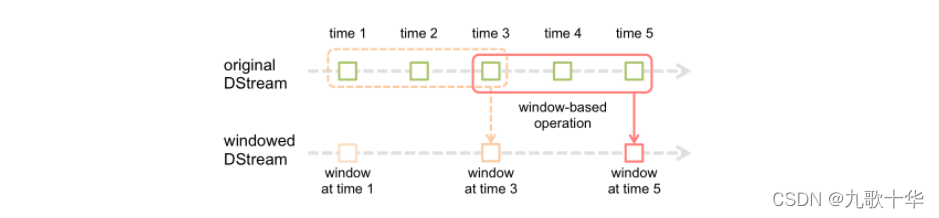
SparkStreaming提供了窗口的计算 ,窗口计算可以整合多个批次的计算结果。在spark streaming 中 ,一共有两种窗口:滑动窗口和滚动窗口。
2、滑动窗口
滑动窗口:需要设置窗口大小和滑动间隔,窗口大小和滑动间隔都是StreamingContext的间隔时间的倍数。
代码:
val result = cacheOper.window(Seconds(20),Seconds(10))
result.count().print()
注意:这里StreamingContext的间隔时间为Seconds(5),使用的是window(Seconds(20),Seconds(10))。概括为:窗口的长度为20s(4个批次),滑动间隔/步长为10s(2个批次)。
输出结果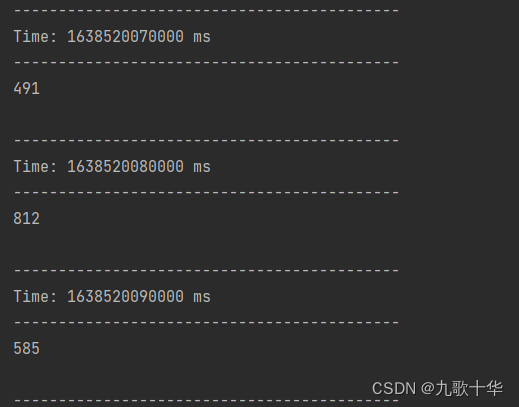
注意:滑动间隔/步长为10s(2个批次)打印一次结果。使用window(Seconds(20))时,不设置滑动步长,默认步长为StreamingContext的批次间隔(5s)。
3、滚动窗口
滚动窗口:需要设置窗口大小和滑动间隔,窗口大小和滑动间隔都是StreamingContext的间隔时间的倍数,同时窗口大小和滑动间隔相等。
代码
val result = cacheOper.window(Seconds(20),Seconds(20))
result.count().print()
注意:window(Seconds(20),Seconds(20)) 概括为:窗口的长度为20s(4个批次),滑动间隔/步长为20s(4个批次)。
滚动窗口是一种特殊的滑动窗口,窗口大小等于滑动间隔/步长。
输出结果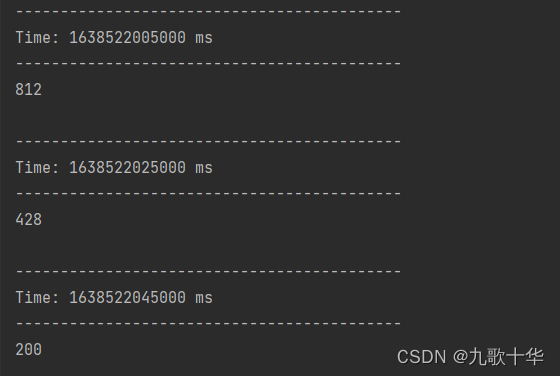
4、滑动窗口和滚动窗口的对比。
对比图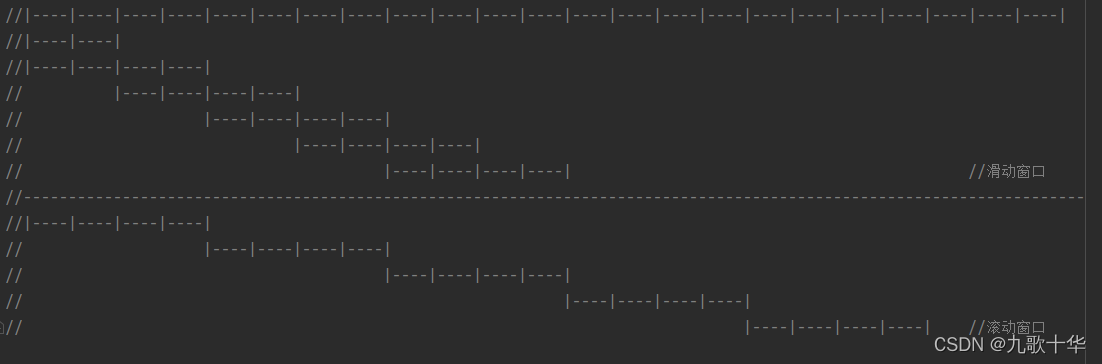
总结:由图可以看出,滑动窗口会出现数据重复计算的情况,滚动窗口则不会。
5、完整代码
object t2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("fs01")
.setMaster("local[*]")
// 配置spark任务优雅的停止
conf.set("spark.streaming.stopGracefullyOnShutdown", "true")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.set("spark.streaming.kafka.consumer.cache.enabled", "false")
conf.set("spark.streaming.kafka.maxRatePerPartition","10")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val ssc:StreamingContext = new StreamingContext(sc, Seconds(5))
val kalfa_server_list: String = PropertiesUtils.loadProperties("kafka.broker.list")
val kafka_group: String = "group_test_role_tn113"
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> kalfa_server_list, //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> kafka_group,
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> "false")
val topics = Array("tmp_t")
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent, //多数时候采用该方式,在所有可用的executor上均匀分配kafka的主题的所有分区。
Subscribe[String, String](topics, kafkaParams))
val cacheOper = kafkaStream.transform(rdd=>{
rdd.map(x => {
val str = x.value().toString
val json2 = JSON.parseObject(str)
val time = json2.get("date").toString
val accountId = json2.getOrDefault("accountid","").toString
(time,accountId)
})
}).cache()
val result = cacheOper.window(Seconds(20),Seconds(20)) //滚动窗口
result.count().print()
val result = cacheOper.window(Seconds(20),Seconds(10)) //滑动窗口
result.count().print()
ssc.start()
ssc.awaitTermination()
}
}
6、其他
spark streaming 还有其他的窗口函数,设置窗口大小和窗口间隔/步长 的方法和window一样。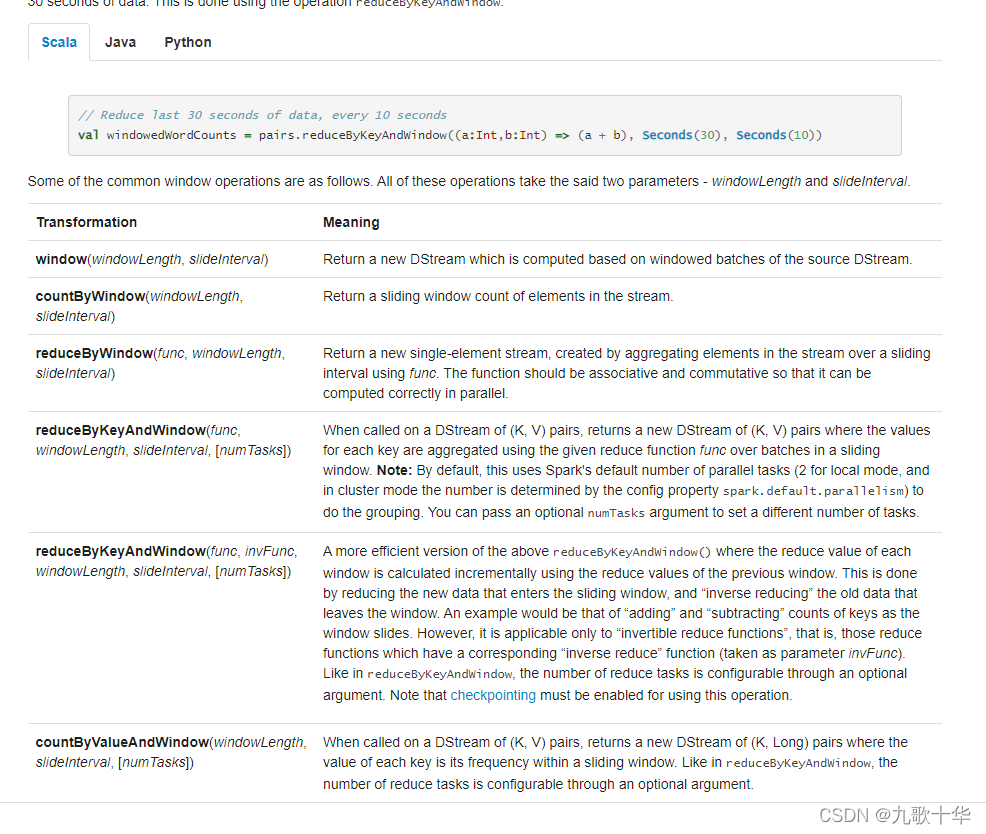
spark streaming官网地址
版权声明:本文为XUJIA2018原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。