

友情提示:全文6000多文字,预计阅读时间11分钟
一、前言
Kubernetes(K8s) 作为一个可移植的、可扩展的开源平台,已经被广泛应用于管理容器化的工作负载和服务。虽然K8s本身提供了丰富的资源类型,但是在使用中,仍然存在扩展资源的需求。
本文将以项目中遇到的一个实际问题作为切入点,详细分析问题原因,同时介绍下使用第三方框架扩展K8s资源时的工作原理。
二、背景
在描述具体问题前,先对涉及的K8s概念做一些简单介绍。
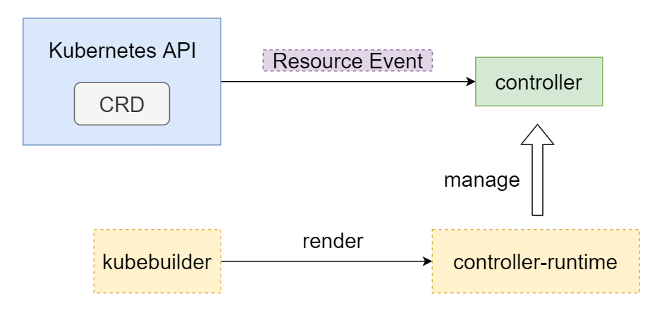
图(1) CRD关系图
1)CRD
CRD全称是CustomResourceDefinition,即自定义资源。CRD也是K8s的一种资源,创建一个CRD即在K8s中定义了一种新的资源类型,这个资源类型可以像K8s中的原生资源一样,既可以通过kubectl命令行,也可以通过访问apiserver来进行操作。
2)Resource Event
这里的Event是当资源本身发生变化时触发的事件,并不是K8s中的Event资源。共有四种类型,CreateEvent,UpdateEvent,DeleteEvent,GenericEvent。其中GenericEvent用来处理未知类型的Event,比如非集群内资源事件,一般不会使用。如果控制器"订阅"了这个资源,那么资源发生变化时,比如被更新或者被删除时,控制器会获取到这个事件。Event是联系控制器和资源的数据通道。
3)controller-runtime
controller-runtime被用来创建K8s资源控制器,如果引入了CRD的话,单纯定义这个资源只能起到存数据的作用,并没有业务处理逻辑。通过controller-runtime可以监听资源的变化,捕获Resource Event,触发相应的处理流程,让这个自定义资源表现出和原生资源相同的行为。
4)kubebuilder
kubebuilder是一个根据模板生成代码的工具,使用kubebuilder可以快速渲染出一个依赖controller-runtime的控制器。在分析controller-runtime之前,需要先用它来生成一个controller。
为了使CRD像原生资源那样工作,需要创建对应的控制器(controller),这个控制器需要捕获资源发生变化时的事件,完成指定的操作。理解了CRD的使用方法和运行原理,这样遇在到问题时,才能够方便定位和解决。
三、问题
在项目中使用controller-runtime监听CRD资源过程中,发现在资源变化触发事件,如果请求事件没有被正确处理而返回错误时,事件会被重复处理,但是每次处理的时间间隔并不规则。表现为日志中显示事件被再处理的间隔时间并不等长,从几秒到十几分钟的分布。精简后的日志显示如下。
controller.go:36] failed at: 2020-06-30 08:14:38.492813441 +0000 UTC m=+0.733523768controller.go:36] failed at: 2020-06-30 08:14:39.493302606 +0000 UTC m=+1.734012936controller.go:36] failed at: 2020-06-30 08:14:40.49372105 +0000 UTC m=+2.734431343controller.go:36] failed at: 2020-06-30 08:14:41.49402338 +0000 UTC m=+3.734733690controller.go:36] failed at: 2020-06-30 08:14:42.494593356 +0000 UTC m=+4.735303683controller.go:36] failed at: 2020-06-30 08:14:43.495217453 +0000 UTC m=+5.735927765controller.go:36] failed at: 2020-06-30 08:14:44.49564783 +0000 UTC m=+6.736358135controller.go:36] failed at: 2020-06-30 08:14:45.496101659 +0000 UTC m=+7.736811950controller.go:36] failed at: 2020-06-30 08:14:46.496564312 +0000 UTC m=+8.737274709controller.go:36] failed at: 2020-06-30 08:14:47.776977606 +0000 UTC m=+10.017687933controller.go:36] failed at: 2020-06-30 08:14:50.339145951 +0000 UTC m=+12.579856239controller.go:36] failed at: 2020-06-30 08:14:55.459778396 +0000 UTC m=+17.700488722controller.go:36] failed at: 2020-06-30 08:15:05.700252055 +0000 UTC m=+27.940962359controller.go:36] failed at: 2020-06-30 08:15:26.180615289 +0000 UTC m=+48.421325604controller.go:36] failed at: 2020-06-30 08:16:07.140934099 +0000 UTC m=+89.381644386controller.go:36] failed at: 2020-06-30 08:17:29.061481373 +0000 UTC m=+171.302191703controller.go:36] failed at: 2020-06-30 08:20:12.901929639 +0000 UTC m=+335.142639963大体观察到,前面日志的时间差值在1s左右,后面的差值变成了5s,10s,20s左右。所以产生了下面的疑问:
1) 这些事件的处理时间间隔是不是会持续增加?
2) 如果持续增加,最大会有多长?
3) 这样持续的事件处理会不会影响到controller性能?
4) 当集群中事件数量规模扩大时会不会冲刷掉正常的请求?
四、分析
为了解Event是如何被处理的,将从上到下分析下controller-runtime的启动流程,Reconcile函数在何时被调用、调用出错时如何再处理等步骤。为了聚焦在事件再处理的步骤上,对前面的几个步骤先做下简单的描述。也借此了解下controller-runtime的整体架构。
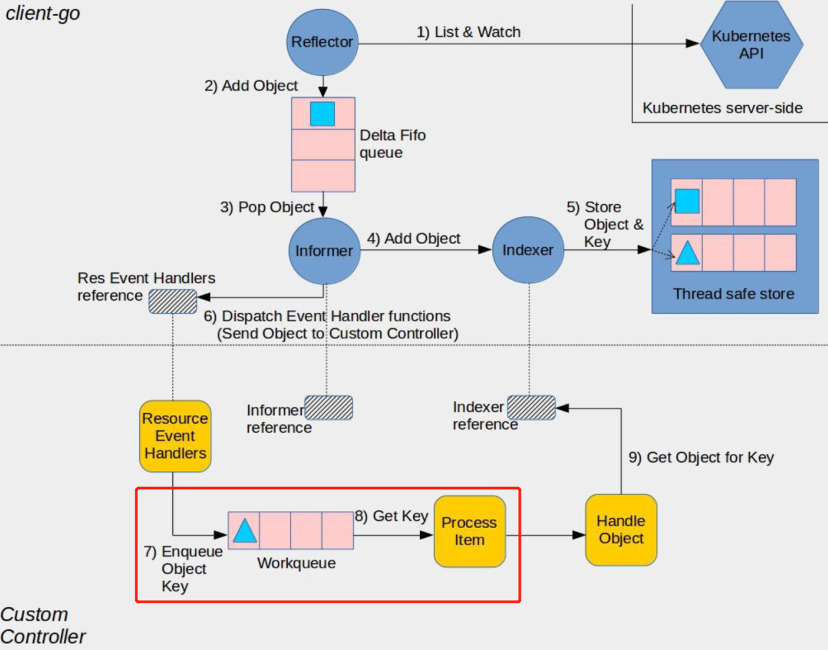
图(2) Kubernetes controller架构图(图片来自网络)
上面提到的问题在步骤7和步骤8中产生,也是本文分析的重点。
在分析controller-runtime之前,需要先使用kubebuilder构建一个简单的controller,因为这不是本文的重点,所以下面略过生成步骤,直接进入到分析步骤。kubebuilder的使用参考链接(https://book.kubebuilder.io/quick-start.html)。
其中reconcile.Reconcile函数被简化为
go func (r *ClusterReconciler) Reconcile(req ctrl.Request) (ctrl.Result,error) { klog.Infof("failed at: %s",time.Now()) return ctrl.Result{},errors.New("err") }1)controller-runtime启动
*controller-runtime版本: 0.5.5
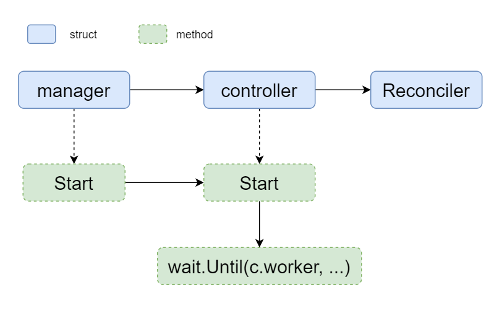
图(3) controller-runtime启动
在controller-runtime中,Event的处理逻辑是Reconciler对象,Reconciler被controller引用,这里的controller便是控制器。在controller之上,还有一个更高层的管理者manager。manager中可以设置多个controller,但是一个controller中只有一个Reconciler。
1.1)生成manager
goimport ("sigs.k8s.io/controller-runtime/pkg/manager") // 生成一个manager,初始化所需的各种配置,实现了Manager接口 mgr,err := manager.New(config,manager.Options{Scheme: scheme,MetricsBindAddress: "0"})... // 这里看似没有涉及到controller,实际上在SetupWithManager中,使用了生成器模式,最终实现了 // manager -> controller -> reconciler 的对象层级结构 // 主体分为两部分,一是配置manager,二是启动manager if err = (&controllers.Reconciler{ Client: client, }).SetupWithManager(mgr); err != nil { klog.Errorf("unable to create cluster controller: %s",err) os.Exit(1) } ... // 启动manager,主要是启动manager中注册的controller if err := mgr.Start(stop); err != nil { klog.Errorf("unable to run the manager: %s",err) }1.2)配置manager
除了manager.New函数外,比较有意思的是SetupWithManager函数
goimport (ctrl "sigs.k8s.io/controller-runtime")func (r *Reconciler) SetupWithManager(mgr ctrl.Manager) error { return ctrl.NewControllerManagedBy(mgr)。For(&v1alpha1.Cluster{})。Complete(r) }NewControllerManagedBy最终会跳转到builder中,,下文中都将以监听v1alpha1.Cluster这个资源为例
pkg/builder/controller.go
`gofunc ControllerManagedBy(m manager.Manager) *Builder { return &Builder{mgr: m}}func (blder *Builder) Complete(r reconcile.Reconciler) error { _,err := blder.Build(r) return err}...func (blder *Builder) Build(r reconcile.Reconciler) (controller.Controller,error) { if r == nil { return nil,fmt.Errorf("must provide a non-nil Reconciler") } if blder.mgr == nil { return nil,fmt.Errorf("must provide a non-nil Manager") }... // Build主要做了两件事,一是doController,二是doWatch // doController中新建了一个controller,reconciler作为入参,将controller和// reconciler联系起来 if err := blder.doController(r); err != nil { return nil,err }... // 监听资源,即上文中的v1alpha1.Cluster if err := blder.doWatch(); err != nil { return nil,err } // 将controller返回 return blder.ctrl,nil}1.3)生成controller
看下doController中如何创建的controller
pkg/builder/controller.go
goimport ("sigs.k8s.io/controller-runtime/pkg/controller")var newController = controller.Newfunc (blder *Builder) doController(r reconcile.Reconciler) error {... ctrlOptions.Reconciler = r blder.ctrl,err = newController(name,blder.mgr,ctrlOptions) return errpkg/controller/controller.go
func New(name string,mgr manager.Manager,options Options) (Controller,error) {... if options.RateLimiter == nil { // 初始化了ratelimiter,核心方法 options.RateLimiter = workqueue.DefaultControllerRateLimiter() }... c := &controller.Controller{ // 将reconciler赋值给Do,在下面的分析中可以看到对controller.Do.Reconile的// 调用 Do: options.Reconciler, ... // 赋值了新建queue的方法,带有限速功能 MakeQueue: func() workqueue.RateLimitingInterface { return workqueue.NewNamedRateLimitingQueue(options.RateLimiter,name) }, MaxConcurrentReconciles: options.MaxConcurrentReconciles, Name: name, } // Add方法完成controller和manager关联 return c,mgr.Add(c)}以options.RateLimiter为例,一般情况下,刚开始分析时是不会过分注意这些变量赋值的,但并不代表不重要。在后面分析的过程中,如果涉及到具体接口方法调用时,最终的分析还是会回溯到实例对象这里。所以这里提前做了标注。
1.4)启动manager
最后看下controller是如何关联到manager的。回溯到上文中的"manager.New"函数中,最终创建了一个controllerManager
pkg/manager/internal.go
gotype controllerManager struct {... // 需要选举操作的controller leaderElectionRunnables []Runnable// 不需要选举操作的controller,为简单,下文中只涉及不需选举的controller,需要选// 举只是增加了步骤,逻辑上没有大的变化 nonLeaderElectionRunnables []Runnable}func (cm *controllerManager) Add(r Runnable) error {... if leRunnable,ok := r.(LeaderElectionRunnable); ok && !leRunnable.NeedLeaderElection() { shouldStart = cm.started // 将r也就是上文提到的controller添加到nonLeaderElectionRunnables中,这里// 就完成了manager和controller的关联 cm.nonLeaderElectionRunnables = append(cm.nonLeaderElectionRunnables,r) } else { shouldStart = cm.startedLeader cm.leaderElectionRunnables = append(cm.leaderElectionRunnables,r) }...到这里完成了manager -> controller -> reconciler的对象关联,下面将看下manager如何启动controller,controller会启动资源的事件处理。回到manager.Start。
1.5)启动controller
pkg/manager/internal.go
gofunc (cm *controllerManager) Start(stop ... go cm.startNonLeaderElectionRunnables()...}func (cm *controllerManager) startNonLeaderElectionRunnables() { ... for _,c := range cm.nonLeaderElectionRunnables { ctrl := c go func() { // 最终是调用了controller的Start函数 if err := ctrl.Start(cm.internalStop); err != nil { cm.errSignal.SignalError(err) } }() }...}controller.Start函数很重要,涉及到了之前提及的队列的初始化和worker的启动。
pkg/internal/controller/controller.go
gofunc (c *Controller) Start(stop struct{}) error { ... // 回想之前初始化controller的queue的创建函数,这里会真正实例化这个queue c.Queue = c.MakeQueue()... err := func() error { ... // 很重要的一个抖动参数,可以认为是一个冷却时间,目前还没有用到 if c.JitterPeriod == 0 { c.JitterPeriod = 1 * time.Second } for i := 0; i < c.MaxConcurrentReconciles; i++ { // 到这里便是启动了MaxConcurrentReconciles个worker go wait.Until(c.worker,c.JitterPeriod,stop) }... }()...controller-runtime整体上可以认为启动结束,收尾函数是wait.Until。这个函数的功能是1) 当接收到stop(channel变量)信号时,函数退出,否则2)运行c.worker函数,如果c.woker退出,间隔JitterPeriod后,再次运行c.worker。这里的JitterPeriod是一个比较重要的参数,它直接影响了问题中提及到的日志刷新频率。
2)调用Reconcile
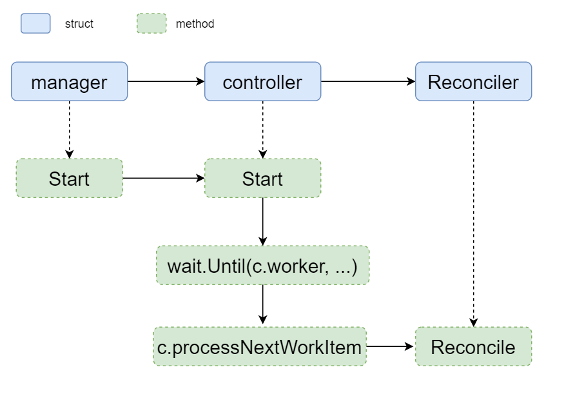
图(4) 调用Reconcile
从上文中的c.worker作为切入点,分析worker是如何调用Reconciler,以及返回错误时如何处理的。
pkg/internal/controller/controller.go
gofunc (c *Controller) worker() {// 引入一个for循环,当processNextWorkItem返回true时,重复执行,如果返回了// false,则退出worker函数。 for c.processNextWorkItem() { }}结合上文中的wait.Until函数,达到了效果1)如果processNextWorkItem返回true时,Until函数暂不生效,逻辑一直在for循环的判断中。2) 如果processNextWorkItem返回false时,跳出了for循环,worker函数也会返回,这时Until函数生效,在JitterPeriod时间间隔后重新调用worker函数,即在1s后重新调度函数。如前文所述,这里会影响日志的刷新频率,前提是processNextWorkItem返回了false。继续看下processNextWorkItem中的逻辑是怎样的。
pkg/internal/controller/controller.go
gofunc (c *Controller) processNextWorkItem() bool {// 从Queue中获取一个item,由NewNamedRateLimitingQueue创建而来,这里可//能影响到日志刷新频率,如果Get一直夯住的话,那么对reconcilerHandler的调用会//延迟 obj,shutdown := c.Queue.Get()... return c.reconcileHandler(obj)}gofunc (c *Controller) reconcileHandler(obj interface{}) bool {...// 在controller-runtime启动中分析过,c.Do被赋值为reconciler,所以// c.Do.Reconcile调用的便是reconciler.Reconcile// Reconcile函数是处理Event的核心逻辑,下面的判断分支即是根据Reconcile的返// 回是否含有错误进行不同的事件请求重入队 if result,err := c.Do.Reconcile(req); err != nil { // 错误不为空,将这个事件请求重新加入到限速队列中,可能会影响到日志刷新的频率 c.Queue.AddRateLimited(req)... // 在错误不为空的情况下,返回false,会导致间接调用者processNextWorkItem的// 返回值为false,再往上追溯,会导致c.worker退出,wait.Until会间隔// JitterPeriod(1s)后重新调度,这可以解释日志中的前面的几条日志的间隔为1s,但// 是无法解释后面日志的时间间隔的递增 return false } else if result.RequeueAfter > 0 {... // 错误为空,但是设置了RequeueAfter的话,会将现有的事件请求作为一个新的请// 求在RequeueAfter后冲洗加入队列,作为新的请求的意思是清除这个请求已在队// 列中保存的其他数据 c.Queue.Forget(obj) c.Queue.AddAfter(req,result.RequeueAfter)... // 返回值为true,processNextWorkItem的返回一直为true,所以不会触发// wait.Until重新调度c.worker,因此如果有日志的话,预测日志的前几条应该不是按// 照1s间隔打印的,而是按照其他规则 return true } else if result.Requeue { // 在错误为空且RequeueAfter不大于0的情况下,如果设置Requeue为true,那// 么仅将请求重新加入限速队列 c.Queue.AddRateLimited(req) // 不会触发wait.Until的重新调度,所以日志应该也是规则的 return true }...// 上述判断分支都失败时,即错误为空,result也无其他设置时,认为请求被正确处理,所// 以直接在队里中清除该请求后返回,可以继续进行下一个请求的处理 c.Queue.Forget(obj)... return truereconcileHandler函数包含了处理事件以及错误处理,reconcile也就是在这个函数中被调用的。根据分析,前几条日志时间间隔1s的原因已经被找到。但是后面时间间隔增加的原因还没有被分析到。
在reconcileHandler中,出现了c.Queue,对req的Get,AddRateLimited等操作都是作用在这个队列上,所以时间间隔要么出现在请求加入到队列之前,要么出现在加入到队列之后的获取上。
3)事件请求时间间隔
*client-go版本: v0.17.1
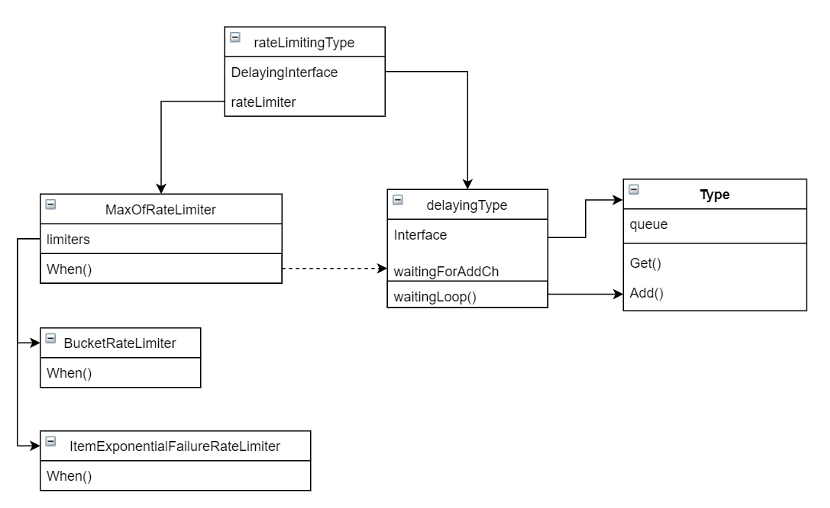
图(5) 事件请求时间间隔
先看下c.Queue.Get,是否在获取处理对象时有时间设置。队列的设置位于client-go库中。import路径为"k8s.io/client-go/util/workqueue"。按照上文提到的,从queue的创建作为入口。
3.1)初始化限速队列
util/workqueue/rate_limiting_queue.go
gofunc NewNamedRateLimitingQueue(rateLimiter RateLimiter,name string) RateLimitingInterface { return &rateLimitingType{ // 初始化了一个延迟队列 DelayingInterface: NewNamedDelayingQueue(name), // rateLimiter作为入参赋值 rateLimiter: rateLimiter, }}先看下NewNamedDelayingQueue。
util/workqueue/delaying_queue.go
gofunc NewNamedDelayingQueue(name string) DelayingInterface { return NewDelayingQueueWithCustomClock(clock.RealClock{},name)}gofunc NewDelayingQueueWithCustomClock(clock clock.Clock,name string) DelayingInterface { ret := &delayingType{ Interface: NewNamed(name), ... } // 开启了一个goroutine用来处理请求对象的增删改查,核心函数 go ret.waitingLoop() return ret}3.2)获取待处理请求事件对象
delayingType结构体中并没有Get方法,因此q是它的某个属性中含有并做了方法提升,这个属性是Interface,所以查看NewNamed的内容。
util/workqueue/queue.go
gofunc NewNamed(name string) *Type { rc := clock.RealClock{} return newQueue( rc, globalMetricsFactory.newQueueMetrics(name,rc), defaultUnfinishedWorkUpdatePeriod, )}gofunc (q *Type) Get() (item interface{},shutdown bool) { ... item,q.queue = q.queue[0],q.queue[1:]... return item,false}所以Get方法最终只是从队列中取值,并没有时间间隔的设置。所以时间间隔的设置是在事件请求入队之前,看下c.Queue.AddRateLimited。仍然属于rateLimitingType上的方法。
gofunc (q *rateLimitingType) AddRateLimited(item interface{}) {// 涉及到DelayingInterfaces属性的AddAfter方法,上文提及过。还涉及到了// q.rateLimiter中的When方法,之前有提及过rateLimiter,但是没有分析 q.DelayingInterface.AddAfter(item,)}3.3)请求事件对象再处理
先看下AddAfter方法,然后分析下rateLimiter。从这里也可以看得出,引用了rateLimiter,很可能日志间隔事件跟限速器有关。
util/workqueue/delaying_queue.go
gofunc (q *delayingType) AddAfter(item interface{},duration time.Duration) { // 从函数名称AddAfter也可以推测,时间间隔会在某个地方被设置 if duration <= 0 { q.Add(item) return } select {// 将duration时间经过运算后赋值给readyAt,然后发送到waitingForAddCh这// channel中,所以这里仍然是进行参数设置,并没有进行真正的时间延迟。但是// duration作为时间间隔被进行了传递。 readyAt表明这个对象在now+duration时// 间后"准备好"被处理。 case q.waitingForAddCh }}所以数据来到了waitingForAddCh中,看下waitingForAddCh是如何读数据的,上文中提及过一个goroutine,位于NewDelayingQueueWithCustomClock方法中,waitingLoop这个方法中开启了一些后台进程。
util/workqueue/delaying_queue.go
gofunc (q *delayingType) waitingLoop() { ... // 初始化一个优先队列,根据有限队列的使用方法,可以推测可能跟时间间隔有关。 waitingForQueue := &waitForPriorityQueue{} heap.Init(waitingForQueue)... // 死循环,表示一直在处理 for { // 如果优先队列总存在数据 for waitingForQueue.Len() > 0 { // 那么取队列中具有最高优先级的元素 entry := waitingForQueue.Peek().(*waitFor) // 如果对象readyAt中的时间尚未到来, 从当前循环中退出,执行for之后的逻辑 if entry.readyAt.After(now) { break } // 如果对象中readyAt的时间已经到来,那么将这个对象出队后加入到queue中。// 所以这里将优先队列和queue联系起来。还有疑问在于优先队列// waitingForQueue中的元素顺序是如何决定的,虽然到这里可以断定元素排序依// 据是entry.readyAt。 entry = heap.Pop(waitingForQueue).(*waitFor) q.Add(entry.data) delete(waitingEntryByData,entry.data) }... select { ... // 上文中waitingForAddCh这个channel在这里被消费 case waitEntry := // 如果对象尚未到被处理时间,就丢到优先队列中 if waitEntry.readyAt.After(q.clock.Now()) { insert(waitingForQueue,waitingEntryByData,waitEntry) } else { // 如果对象可以被处理,那么加入到queue中。 q.Add(waitEntry.data) }.... } }}引入了两个队列,一个是queue,一个是waitingForQueue,前者是全局队列,请求对象在整个程序中的处理顺序按照queue的先进先出原则进行处理,后者是优先队列,由于在请求对象入queue之前的预处理,达成的效果是queue中存在的对象必然是到了被处理的时间的,而且处理先后按照duration从小到大排序。最后看下insert函数。
util/workqueue/delaying_queue.go
go// 最小堆排序,保证waitForPriorityQueue堆顶的元素是readyAt时间最小的值func insert(q *waitForPriorityQueue,knownEntries map[t]*waitFor,entry *waitFor) { existing,exists := knownEntries[entry.data] if exists { if existing.readyAt.After(entry.readyAt) { existing.readyAt = entry.readyAt heap.Fix(q,existing.index) } return heap.Push(q,entry) knownEntries[entry.data] = entry上面分析了请求对象的入队顺序以及被Get时的先后顺序,请求对象是依据readyAt中设置的时间先后入队的,所以最后的问题衍变成duration是如何产生的。回溯看一下duration如何产生。duration出现在q.DelayingInterface.AddAfter函数中,duration的值为q.rateLimiter.When
最后看下q.rateLimiter,在初始化controller的时候被赋值到options中。创建函数为workqueue.DefaultControllerRateLimiter。
3.4)限速器
util/workqueue/default_rate_limiters.go
func DefaultControllerRateLimiter() RateLimiter { return NewMaxOfRateLimiter( // 一个是指数限速器 NewItemExponentialFailureRateLimiter(5*time.Millisecond,1000*time.Second), // 一个是桶限速器 &BucketRateLimiter{Limiter: rate.NewLimiter(rate.Limit(10),100)}, )}把这两个限速器放在一边,先看下NewMaxOfRateLimiter.When函数。最终落在NewMaxOfRateLimiter.When。
gofunc (r *MaxOfRateLimiter) When(item interface{}) time.Duration { // 每次调用When时都会初始化一个ret ret := time.Duration(0) // 上面的两个限速器是这里的r.limiters for _,limiter := range r.limiters { // 分被调用限速器 curr := limiter.When(item) // 如果当前限速器返回的When值比ret大,则更新到ret中 if curr > ret { ret = curr } } return ret}实现的效果是每次调用When时,返回所有限速器中When函数的最大值作为duration的延迟值。
其中令牌桶是常见的限流算法之一,目的是保证请求处理速率不超过设置阈值。在BucketRateLimiter中,qps被设置为10,桶大小为100。程序当前只监听了一个资源,每次也只有一个请求入队,每秒平均请求数很小,不会触发限流,即便程序在刚启动时,也不会有100个请求产生引起限流器brust。因此只要考虑NewItemExponentialFailureRateLimiter这个限流器就可以了。
util/workqueue/default_rate_limiters.go
gofunc NewItemExponentialFailureRateLimiter(baseDelay time.Duration,maxDelay time.Duration) RateLimiter { // baseDelay为5ms,maxDelay为1000s,即16分40s。 return &ItemExponentialFailureRateLimiter{ failures: map[interface{}]int{}, baseDelay: baseDelay, maxDelay: maxDelay, }}gofunc (r *ItemExponentialFailureRateLimiter) When(item interface{}) time.Duration { ...// ItemExponentialFailureRateLimiter为全局变量,每次调用when时,都会在// failures中记录一下,初始值为0。如果When被调用时,failures中已有这个对象,表// 明是因失败重新入对,这个对象的failures值加1,如果下次再失败,继续加1。这个逻// 辑保证了每个对象都是可以被追溯的。当处理完成时,会有Forget函数清除掉过期数// 据。 exp := r.failures[item] r.failures[item] = r.failures[item] + 1 // 指数表现在math.Pow函数上,乘法因子一个是5ms,一个是底数为2,指数为failures[item]的幂指数。结果即为When将要返回的duration时间。 backoff := float64(r.baseDelay.Nanoseconds()) * math.Pow(2,float64(exp))... // 格式转换 calculated := time.Duration(backoff) // 如果幂指数运算的结果超过了maxDelay ,那么就只返回maxDelay,即为1000s if calculated > r.maxDelay { return r.maxDelay } return calculated}ItemExponentialFailureRateLimiter限流器起到的作用是对每一个请求对象,如果该对象的失败次逐次增加,那么它下一次被处理的时间则呈指数增加。所以日志的刷新间隔会逐渐变长,知道maxDelay。
延迟时间表
乘数1(单位s) | 乘数2 | 值(单位s) |
0.005 | 2^0 | 0.005 |
2^1 | 0.01 | |
2^2 | 0.02 | |
2^3 | 0.04 | |
2^4 | 0.08 | |
2^5 | 0.16 | |
2^6 | 0.32 | |
2^7 | 0.64 | |
2^8 | 1.28 | |
2^9 | 2.56 | |
2^10 | 5.12 | |
2^11 | 10.24 | |
2^12 | 20.48 | |
2^13 | 40.96 | |
2^14 | 81.92 | |
2^15 | 163.84 | |
2^16 | 327.68 | |
2^17 | 655.36 | |
2^18 | 1310.72 |
四、验证
Reconcile中返回(ctrl.Result{},errors.New("err")),
乘数1(单位s) | 乘数2 | 值(单位s) | 观察数据 |
0.005 | 2^0 | 0.005 | 1.001 |
2^1 | 0.01 | 1.000 | |
2^2 | 0.02 | 1.001 | |
2^3 | 0.04 | 1.000 | |
2^4 | 0.08 | 1.001 | |
2^5 | 0.16 | 1.000 | |
2^6 | 0.32 | 1.001 | |
2^7 | 0.64 | 1.000 | |
2^8 | 1.28 | 1.280 | |
2^9 | 2.56 | 2.536 | |
2^10 | 5.12 | 5.120 | |
2^11 | 10.24 | 10.241 | |
2^12 | 20.48 | 20.480 | |
2^13 | 40.96 | 40.960 | |
2^14 | 81.92 | 81.921 | |
2^15 | 163.84 | 163.840 |
在第9次入队之前,虽然指数限速器的duration值很小,但是因为Reconcile中err返回了非空值,所以processNextWorkItem退出,wait.Until中的JitterPeriod生效,即1s后才重启c.worker,因此前7次的时间间隔都在1s左右。从第9次开始,虽然c.worker启动了,过了1s时间,但是指数限速器中设置的时间已经大于1s,所以只能等待时间到达才可处理请求。等到第19次入队时,如果限速器不设最大阈值,那么应该等待1310.72s,但是最大值是1000s,所以从19次开始,间隔时间都会是1000s。
五、结论现在可以回答之前提到的疑问,
1) 事件被再处理的时间间隔确实会逐渐增加,并且影响因素主要有两个,一是位于wait.Until中的抖动参数,二是ItemExponentialFailureRateLimiter限流器中的幂指数延迟时间。
2) 有最大值限制,最大的时间间隔是1000s。并且当达到最大时间间隔后,后面会稳定为最大值。
3) controller中使用了令牌桶来限流,最大处理能力是10qps。当请求数量超限时,controller会存在性能问题,请求响应时间会增加。当前能想到的处理方法是更改限速器参数配置或者增加controller中worker的数量。
4) 最小堆和优先队列可以保证每个请求按时间上的先后顺序被处理。当请求规模扩大时,理论上只要资源充足,不会出现丢请求的状况。
上述问题的核心是重试。controller-runtime中主要使用了抖动参数和限流器来处理事件,前者保证了当业务逻辑出错时,controller有足够的冷却时间恢复,后者平衡了事件被再处理的频率和效率。
K8s的设计要求资源被声明后,controller需要负责资源的状态一直保持在期望值,重试是不可避免的,所以一个好的重试机制对于服务性能至关重要。在其他重试场景中,相对于简单的定长间隔重写,引入限流器不失为一个更好的选择。
参考链接
https://book.kubebuilder.io/quick-start.html
https://book.kubebuilder.io/cronjob-tutorial/controller-overview.html
https://en.wikipedia.org/wiki/Token_bucket
往期精选
1、干货分享丨深入理解CAS—以AtomicInteger为例
2、干货分享丨高性能RoCE网络技术研究
3、干货分享丨浅析ForkJoin并行框架


