学习视频:B站 刘二大人《PyTorch深度学习实践》完结合集
四、用PyTorch实现线性回归
1. 用pytorch实现:(训练过程)
- 准备数据集
- 设计模型
- 计算loss和优化
- 训练周期

2. 构造函数

在pytorch的__ call __语句里面有一个重要的就是forward()。
Module实现了魔法函数__ call __(),call()里面有一条语句是要调用forward()。因此新写的类中需要重写forward()覆盖掉父类中的forward()。
所以我们在自己的moudle里面必须是实现forward。

3. 损失函数

4. 优化器

优化器不会构建计算图。
第一个参数:params代表的是权重。
优化器可以对模型里面的所有权重进行更新,上述的模型包括w和b。
具体可参照pytorch官网
5. 完整代码
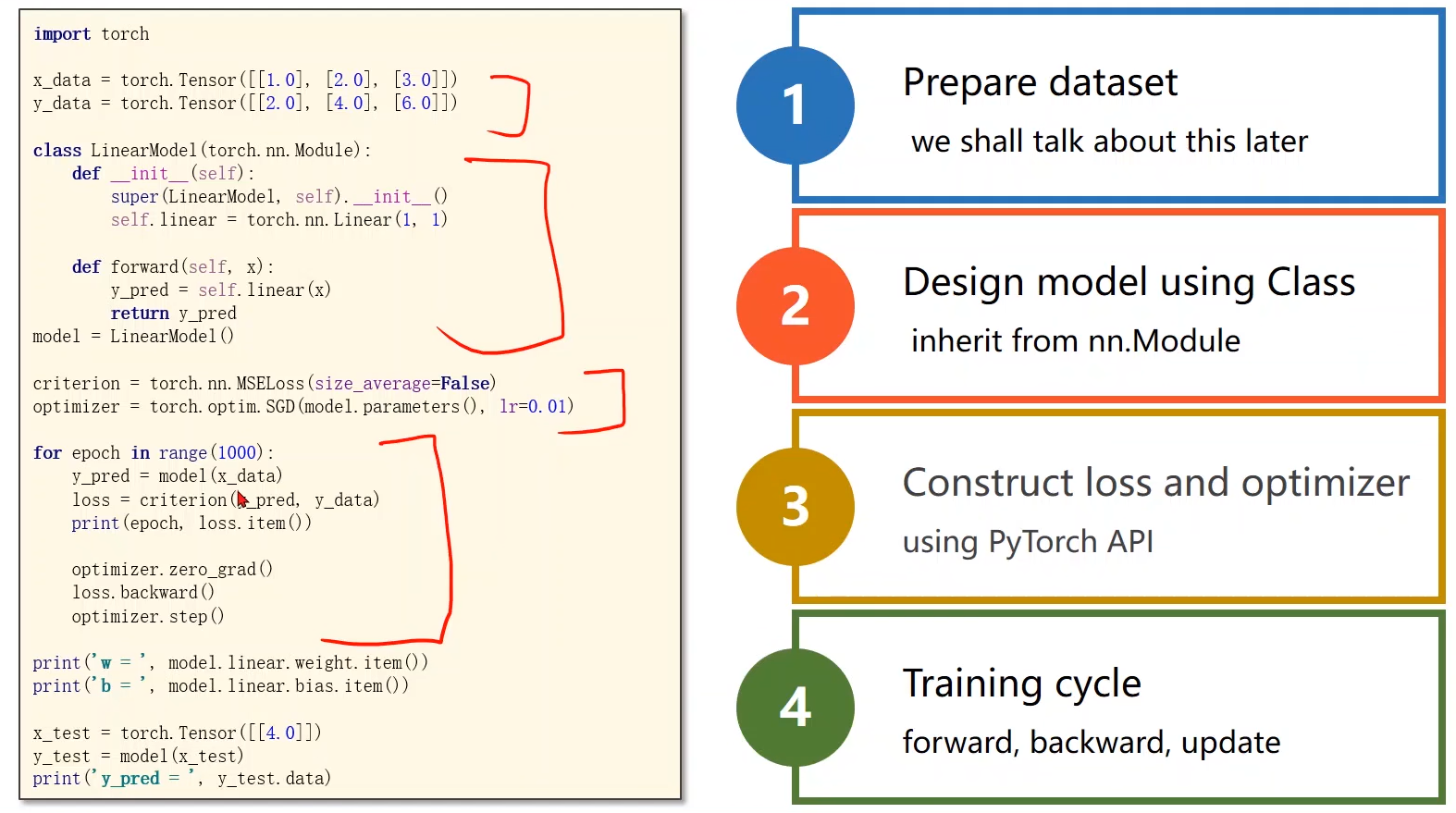
import torch
#准备数据集
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
#定义模型
class LinearModel(torch.nn.Module): #继承nn.Module
def __init__(self):
super(LinearModel,self).__init__() #调用父类的构造
self.linear = torch.nn.Linear(1,1) #torch.nn.Linear是torch中的一个类,torch.nn.Linear(1,1)构造了一个对象,包括权重和偏置
def forward(self,x):
y_pred = self.linear(x) #实现了可调用的对象
return y_pred
model = LinearModel()
#构造损失函数
criterion = torch.nn.MSELoss(size_average=False) #需要传入的参数为y_pred,y_data
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
#训练的过程
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred,y_data)
print(epoch,loss.item())
optimizer.zero_grad() #梯度归零
loss.backward()
optimizer.step() #梯度更新
#输出结果
print('w=','%.2f'%(model.linear.weight))
print("b=",'%.2f'%(model.linear.bias))
x_test = torch.Tensor([4.0])
y_test = model(x_test)
print('y_pred=',y_test.data)
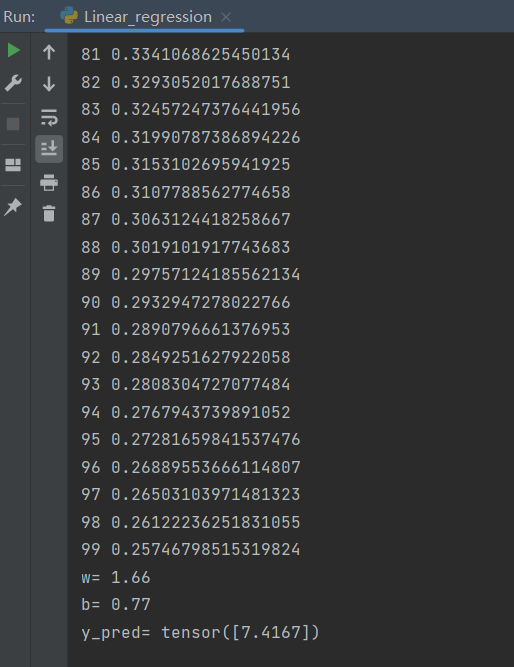
运行结果:
参考资料
https://blog.csdn.net/lizhuangabby/article/details/125607166
版权声明:本文为qq_46656857原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。