为什么HashMap不是线程安全?
HashMap实现使用了一个数组,每个数组项有一个链表(JDK8之后链表长度大于8的将会把链表转换为红黑树),数组index是有key的hashCode以及数组Capacity综合计算得出,由于不同的key能计算出相同的index,这就产生了hash冲突。
每条数据都为一个数据节点,其中hash用来定位,由于hash是由key值所计算的,更改之后可能会丢失记录,所以key值不允许修改,next指向下一个节点。
HashMap初始数组长度为16,loadFact为0.751,当超过阈值,HashMap会进行扩容(resize)操作,每次为原先的2倍,直至最大值。
数据模型:
Node{
final int hash;
final K key;
V value;
Node<K,V> next;
}
实现:
1.通过计算hash与capacity得出数组index,确定位置。
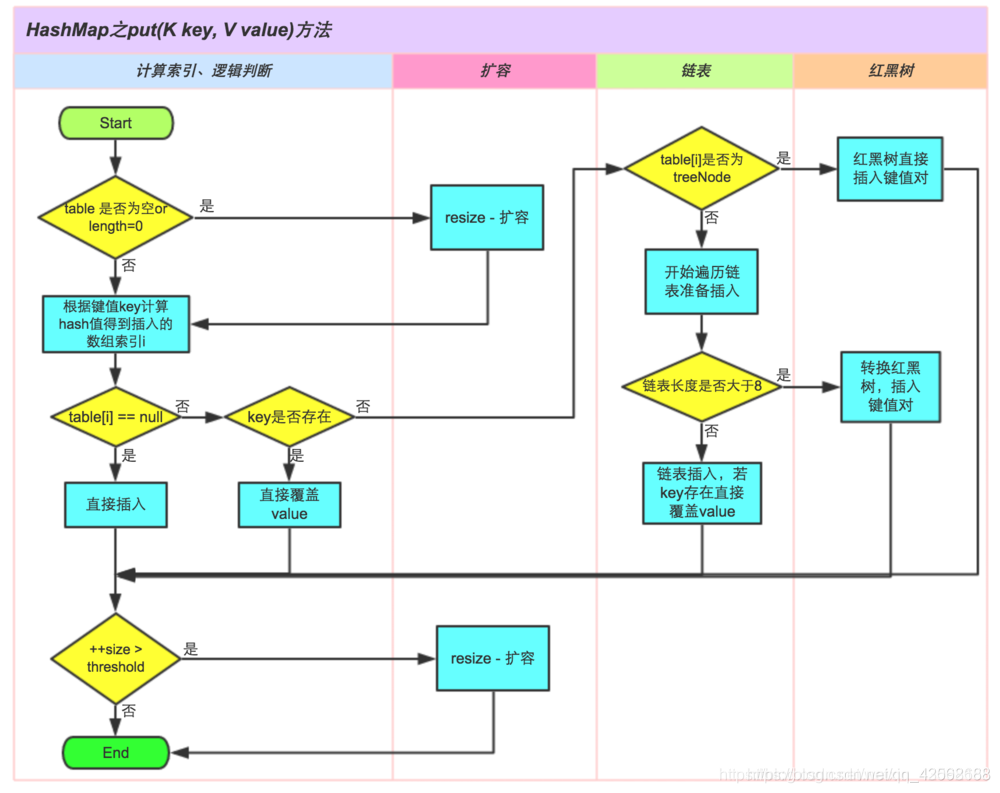
2.HashMap.put():
3.resize机制(JDK1.7):
扩容机制就是重新申请一个2倍大小的数组,然后逐个进行映射至新的数组中,使旧的数组引用失效。
实现代码:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
① Entry<K,V> next = e.next; //获得下一个节点,保存
② if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
③ int i = indexFor(e.hash, newCapacity);
④ e.next = newTable[i]; //当前节点的next指针指向新表数组的第i个元素
⑤ newTable[i] = e; //将e放入新表第i个位置,由于新表数组原来元素已有e.next指向,所以这个相当于将e插入该链表的表头
⑥ e = next;
}
}
}
JDK1.7下的线程不安全问题:
1.put导致的数据覆盖
假设A与B所计算的索引位置相同,当线程A计算定位索引时,由于多线程抢占时间导致线程A未向其中插入数据,时间片就用完了,此时线程B计算定位索引并插入成功,B成功之后A再次抢占,A将会覆盖B所插入的数据。
2.resize导致的循环
假设原表为如下
单线程情况下(以下数字代替数据节点Node):
假设1和3计算所得index相同。
① - { e = 1 ; e.next = 3 ; next = 3 }
②③④⑤ - { e = 1 ; newTable[i] = null ; e.next = null ; newTable = 1 }
⑥ - { e = 3 }
此时newTable为: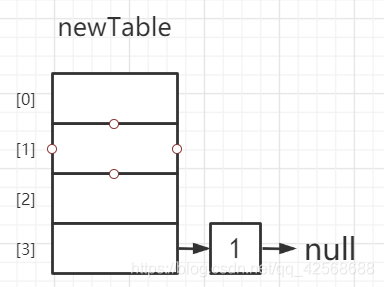
① - { e = 3 ; e.next = null ; next = null }
②③④⑤ - { e = 3 ; newTable[i] = 1 ; e.next = 1 ; newTable = 3 }
⑥ - { e = null }
此时newTable为: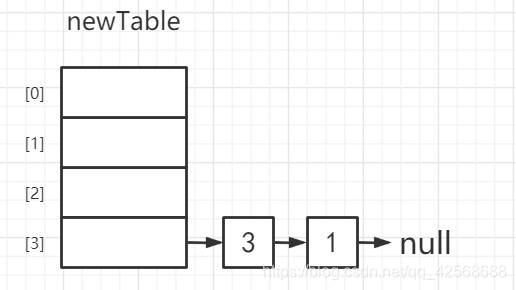
循环结束,扩容完成。
多线程情况下(以下数字代替数据节点Node):
假设Thread A执行
① - { e = 1 ; e.next = 3 ; next = 7 }
此时Thread B抢占,将resize成功执行
① - { e = 1 ; e.next = 3 ; next = 3 }
②③④⑤ - { e = 1 ; newTable[i] = null ; e.next = null ; newTable = 1 }
⑥ - { e = 3 }
① - { e = 3 ; e.next = null ; next = null }
②③④⑤ - { e = 3 ; newTable[i] = 1 ; e.next = 1 ; newTable = 3 }
⑥ - { e = null }
Thread B的newTable:
此时数据节点3的属性为
Node{
final int hash; //3
final K key; //key
V value; //value
Node<K,V> next; //1
}
节点1的属性为
Node{
final int hash; //1
final K key; //key
V value; //value
Node<K,V> next; //null
}
Thread A抢占到时间片,继续执行,此时e = 1 , next = 3:
②③④⑤ - { e = 1 ; newTable[i] = null ; e.next = null ; newTable = 1 }
⑥ - { e = 3 }
Thread A 的newTable:
① - { e = 3 ; e.next = 1 ; next = 1 }
②③④⑤ - { e = 3 ; newTable[i] = 1 ; e.next = 1 ; newTable = 3 }
⑥ - { e = 1 }
Thread A的newTable:
① - { e = 1 ; e.next = null ; next = null }
②③④⑤ - { e = 1 ; newTable[i] = 3 ; e.next = 3 ; newTable = 1 }
⑥ - { e = null }
循环结束,此时Thread A的newTable为: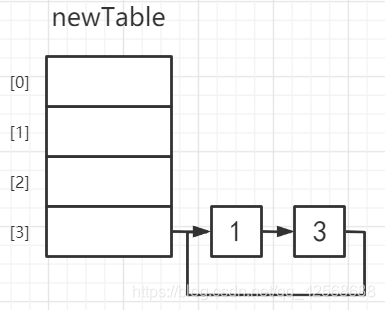
由于get为循环遍历next,所以当上形成循环链表之后,调用get方法会变成死循环。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
为什么负载因子是0.75? ↩︎