HIVE SQL 底层执行逻辑
hive可以通过访问HDFS等,通过MR引擎(或者更换的Spark、Tez等)执行查询逻辑,一个hive sql会被解译为若干个mr流程,那么是怎么执行的?
一、HIVE五大组件
在hive中,有很重要的五个组件
UI
用户界面,也就是hive提供给用户的可视化工具
DRIVER
驱动程序,十分关键的一部分
COMPLIER
编译器。负责将HIVE SQL翻译成可执行的执行计划
METASTORE
元数据库。存储各种表和分区所有的结构信息
EXECUTION ENGIGN
执行引擎。将解译好的执行计划提交到不同的引擎上。MR、Spark、Tez
二、执行过程
执行过程可以简单的理解为
- 通过UI提交代码
- 编译器编译,生成执行计划
- 获取执行计划中需要的元数据
- 为执行计划划分阶段
- 执行任务
- 任务结束,返回到UI
步骤1:UI调用DRIVER的接口
步骤2:DRIVER为查询创建会话句柄,并将查询发送到编译器生成执行计划
步骤3:编译器从元数据存储中获取输入输出元数据
步骤4:编译器生成的计划是分阶段的DAG,每个阶段要么是map任务,要么是reduce任务,从而将生成的计划发给DRIVER
步骤5:执行引擎将任务提交到对应的引擎。在每个 task(mapper/reducer) 中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入到一个临时HDFS文件中(如果不需要 reduce 阶段,则在 map 中操作)。临时文件用于向计划中后面的 map/reduce 阶段提供数据。
步骤6:最终的临时文件移动到表的位置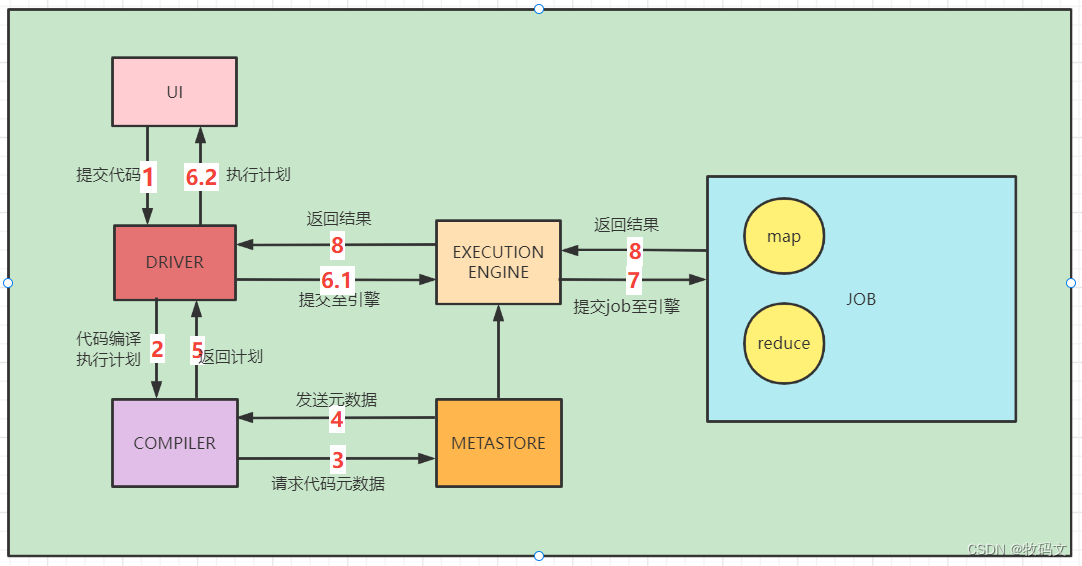
版权声明:本文为weixin_46429290原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。