1)没有标签的图像语义如何提取
2)端到端的对齐过程如何构建,具体损失函数是什么
3)attention如何加入,双端反馈如何建立联系,attention训练过程的损失函数是什么
1: Karpathy A, Fei-Fei L. Deep Visual-Semantic Alignments for Generating Image Descriptions.
IEEE Trans Pattern Anal Mach Intell. 2017 Apr;39(4):664-676.
面向图像自动语句标注的注意力反馈模型
摘要
这篇文章的作者提出了一种方法,可以用于生成图像的自然语言描述。
主要包含了两个部分:
(1)视觉语义的对齐模型;
(2)为新图像生成文本描述的 Multimodal RNN 模型。
其中视觉语义的对齐模型主要由3部分组成:
- 应用于图像区域的卷积神经网络(Convolution Neural Networks)。
- 应用于语句的双向循环神经网络(bidirectional Recurrent Neural Networks)。
- 结构化的目标函数,通过多模态嵌入来对齐视觉与语义。
概述
图片的描述语句通常仅提到“有什么”,而不知道“在哪里”,所以作者提出将 imgae caption 数据集的描述语句看作 弱标签(weak labels),这些语句中有一些单词,对应了图片中一些特殊但位置未知的物体,那么我们就想如何 “对齐” 这些单词和物体(就像做连线题一样),然后再学习如何生成描述。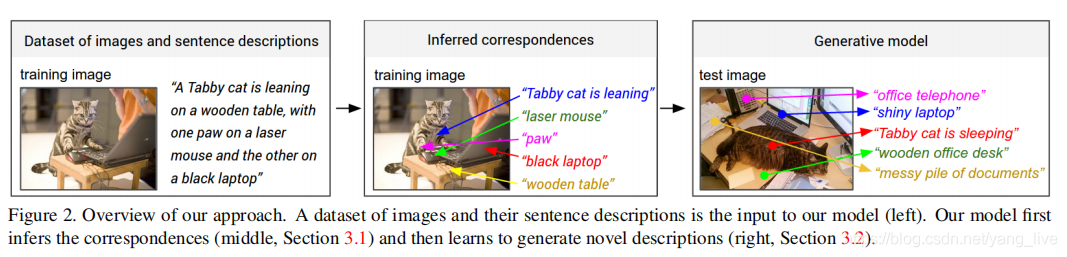
- 图像数据和其对应的语句描述作为模型的输入(左图)
- 模型学习推理子图像区域和其对应的语句片段(中图)
- 最后模型学习为图像生成一些描述语句(右图)
第一个模型对齐模型是第二个模型生成模型的准备工作,第二个模型在第一个模型推测出的对应关系上进行训练。
Model1:对齐RCNN+BRNN
由于最终的目标是看着图片生成描述语句,所以我们可以先学习图片和语句的一种潜在对应关系。
对齐图像和文本直观上就是在做连线题
**输入:**图片和图片对应描述的数据集
**目标:**找到图片区域的语句片段和物体间的潜在对应关系
举例:“Tabby cat is leaning” 对应 cat,“wooden table” 对应 table
1.图像的表示:Region Convolution Neural Network(RCNN)
we use the top 19 detected locations in addition to the whole image and compute the representations based on the pixels Ib.
我们使用检测出排名前19个图片的子框加上图片本身来进行卷积操作。
思路:
1.使用Region Convolution Neural Network(RCNN)检测图像上的物体,取top 19个检测到的图像区域,加上整张图像,共20个作为图像特征。
2.计算这个20个图像块的CNN特征,每个特征是4096维(最后一个全连接层的输出)
方法:
使用Region CNN(RCNN)来编码图片,CNN在ImageNet上预训练。
ImageNet 预训练模型的作用是抽取「通用」特征。
- 目前,cv领域的图像训练主要预先在ImageNet分类任务上预训练的模型作为初始权重。
- ImageNet项目是一个用于视觉对象识别软件研究的大型可视化数据库。超过1400万的图像URL被ImageNet手动注释,以指示图片中的对象;
- 在至少一百万个图像中,还提供了边界框。
- ImageNet包含2万多个类别; 其中一个典型的类别,如“气球”或“草莓”,包含数百个图像。
使用ImageNet预训练有以下几点原因:
1.ImageNet囊括了非常多的不同类别的数据,这些数据有各种各样浅层和深层的特征,在ImageNet上训练好的权值很好的提取到了这些特征。
2.因为预训练得到的模型存在通用性(可以用于提取特征),可以被其它类似的任务借用。
3.预训练模型后的微调相当于给模型一个初始化参数。
本文在ImageNet Detection Challenge的200类上作了fine-tune,选择top19的location和整张图片来计算图片的表达。
计算方法:根据每个bounding box的像素Ib将图像映射为向量V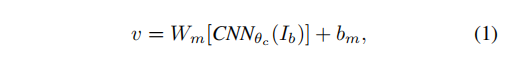
- Ib表示某个bounding box中的pixels,在CNN得到的特征上作投影得到mutimodal embedding。
- CNN(Ib) 将 bounding box 内的像素Ib转换为分类前的全连接层的 (4096∗1)
- 其中Wm是 h×4096 维的矩阵,h是多模态嵌入空间的维度(1000到1600的范围)。因此每个图像区域表示为h维的向量 {vi|i=1…20} 。
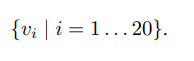
2.表示句子
使用Bidirectional RNN(BRNN)来编码句子,BRNN接受N个词的输入,然后将他们编码成h维向量,每个词的编码过程会融入其上下文的信息,输入的词用word embedding编码为300维的向量。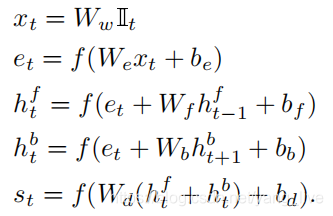
- 其中第一个公式里的It是一个one-hot,在单词表的第t个单词的索引都有一个值1,其余为0。它的含义是: 初始时这是一个全0的列向量,假设句子中第t个词在词典(word vocabulary)中的位置为i, 那只有i位置的值为1,其他位置的值全为0。
- 用 word2vec 将单词转为300维的向量表示,即权重Ww。这一步是准备工作。第二个公式则是将这些一股脑儿输入进BRNN模型里面。
- 而公式三四代表着BRNN中的两个方向的RNN,最后得出的St中既包含了单词的位置,又包含在语境中的特殊含义,
- 在最后用ReLU作为激活函数: f:x⇒max(0,x)。
- We,Wf,Wb,Wd,be,bf,bb,bd是要学习的参数。
3.对齐(alignment)目标
“our strategy is to formulate an image-sentence score as a function of the individual region word scores.”
本文提出一种得分机制来当作不同单词在各个区域的得分。
通过前两步,已经可以将每张图片和每条语句转化成一个公共的 h 维向量集合。
本文将 image-sentence 得分看成是独立的 region-word 得分的函数。
直观上看,如果一个单词对一个图片区域有较高的置信度,那么包含这个单词的 sentence-image 应该也有较高的匹配得分。
现在已经将图片和句子编码到了相同的h维空间中,定义图片k和句子l的匹配程度为: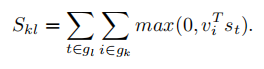
- gk是第k张图片中的feature集合
- gl是第l个语句中的语句feature的集合
- 下标 k,l遍历训练集中的图像区域和语句片段
得分即相似度用向量点积(dot product)表示,当句子feature与图像feature的点积得分Skl为正时,表明语句片段和图像区域是对齐的。
优化: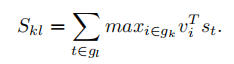
原先的相似性度量是把每一对大于0的点积求和得出最终得分,改版后就是只针对每个图像最大的点积算出对应句子片段的得分
这个公式表示每个单词只与最匹配的那个图像区域进行对齐。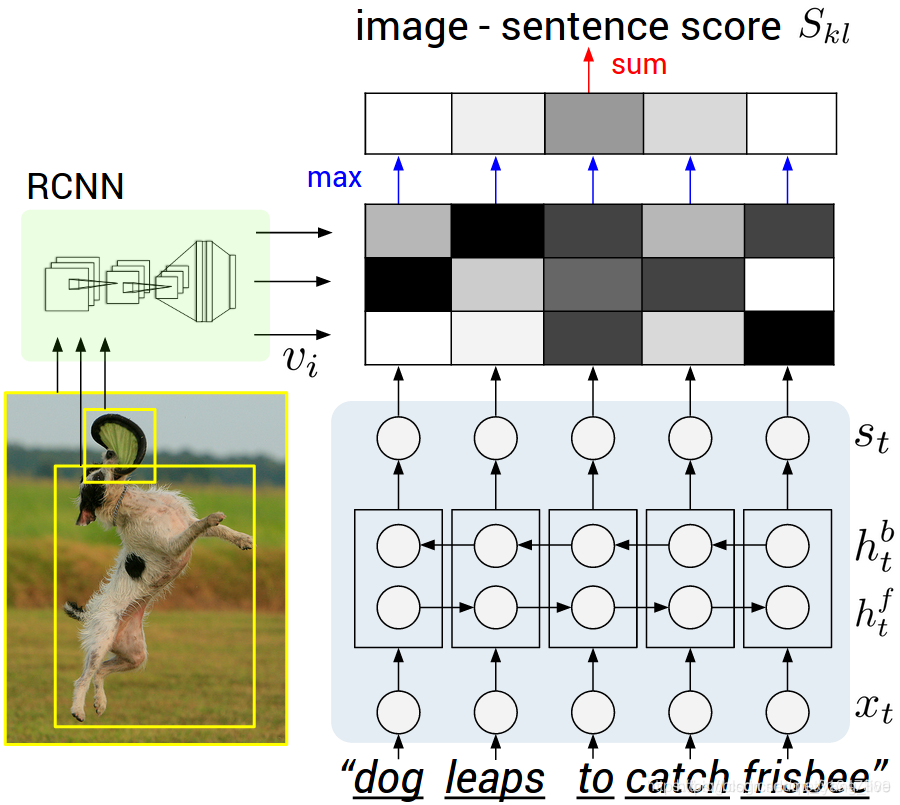
假设 k=l 表示相对应的图像和语句,那么最终的结构化损失函数为: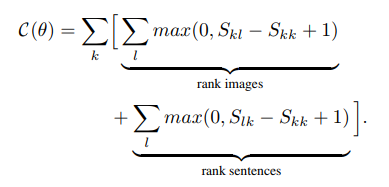
- Skl针对每个图像最大的点积
- Slk则是针对每个句子片段的最大点积
- Skk是当前得分
- 后面的+1是为防止没有与标准值特别符合的(因为点积和大于0即代表合格,分越大越好),如果没有只能从不合格里面选出最接近的了,当然又不能点积分过低,于是从点积和(-1,0)之间找个最好的。
它的物理意义就是使得Skk要尽量高,而Skl或Slk尽量小。
这样的损失函数鼓励k=l时有更高的匹配得分,k!=l时得分更低,这解决了没有region级别的对应label的问题。
Model2:生成
假定我们有一些图像和相关文本描述的集合,这些集合可以是整幅的图像和相关的句子描述,也可以是图像区域和相关的文本片段。
主要的挑战是设计一个模型,可以根据给出的图像,预测出可变尺寸的文本序列。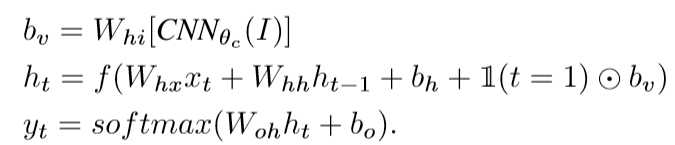
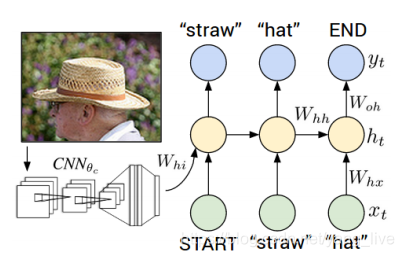
- Xt为t时刻的输入;ht为t时刻的语境意义,会带入到t+1时刻计算;
- yt为下一个输出单词。
- 由下图可以直观地看出RNN地训练过程:每一步RNN接受都接受上一步的单词与语境义,同时在句中下一个单词基础上定义一个分布。
RNN在第一个时间步的输入取决于图像信息。要注意的是训练的时候每一时刻输入的是标准答案,测试的时候的输入是上一时刻概率最大的单词。