前言
我们在写C++的时候,通常是将定义写在.cpp文件内,将声明写在.h(header)文件内。自从我开始写C++以来,将近两年时间都是这么写的,也从来没考虑过为什么要这么写,以为这就是一个约定。最近用python写了几个月的毕业设计,C++都快忘光了,找个视频重新捡起来,视频里讲的很详细。这篇文章将我看过的有关头文件的部分进行一下梳理和总结。
参考视频地址
http://bit.ly/2kumpdb(原地址)
https://www.bilibili.com/video/av68697716?p=1(B站搬运+翻译版)
本文内容:
1.#include的作用
2.为什么在头文件里写函数声明
3.#program once和#ifndef等等
1.#include的作用
当我们看到#include这行语句开头的“#”,就可以知道这是一句“预处理”语句,在C++生成可执行文件的过程中,要经过编译和链接两个步骤。在编译过程中,很重要的一步就是对这些预处理语句进行处理,比如我们熟悉的#define要在这个编译之前进行宏替换,这就是预处理的一部分,所有的以“#”开头的语句都会在这个时候进行处理,生成我们需要的代码送入后续步骤。因此我们要看一下对于一个简单的程序,我们#include一个头文件后再编译,它会生成什么样的代码。//main.cpp
#include <iostream>
int main()
{
return 0;
}
上面就是这段代码,什么也没有做,只是include一个我们入门C++时都会用到的头文件。接下来我们需要调整项目属性设置,使其编译结果输出到文件。右键项目->属性->C/C++ ->预处理器->预处理到文件(本节结束记得改回去,否则编译完无法生成.obj文件)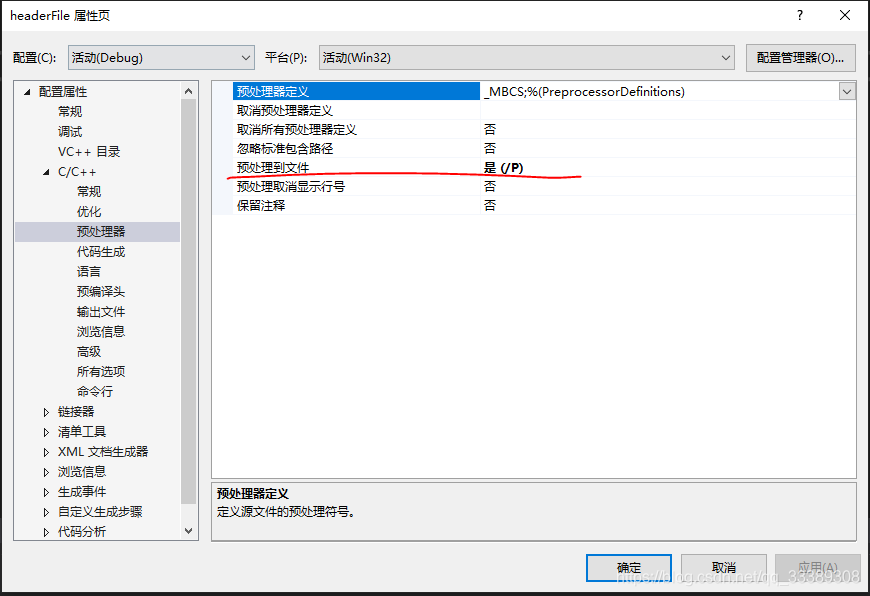
然后单独进行编译(ctrl+F7,不是F5),在项目Debug目录下就可以看到后缀名为.i的文件,我们将它拖到VS中进行显示,可以看到这个编译结果居然有5W多行!也就是说真正送到后面步骤进行处理的代码是这5W多行,而我们自己写的main在最后。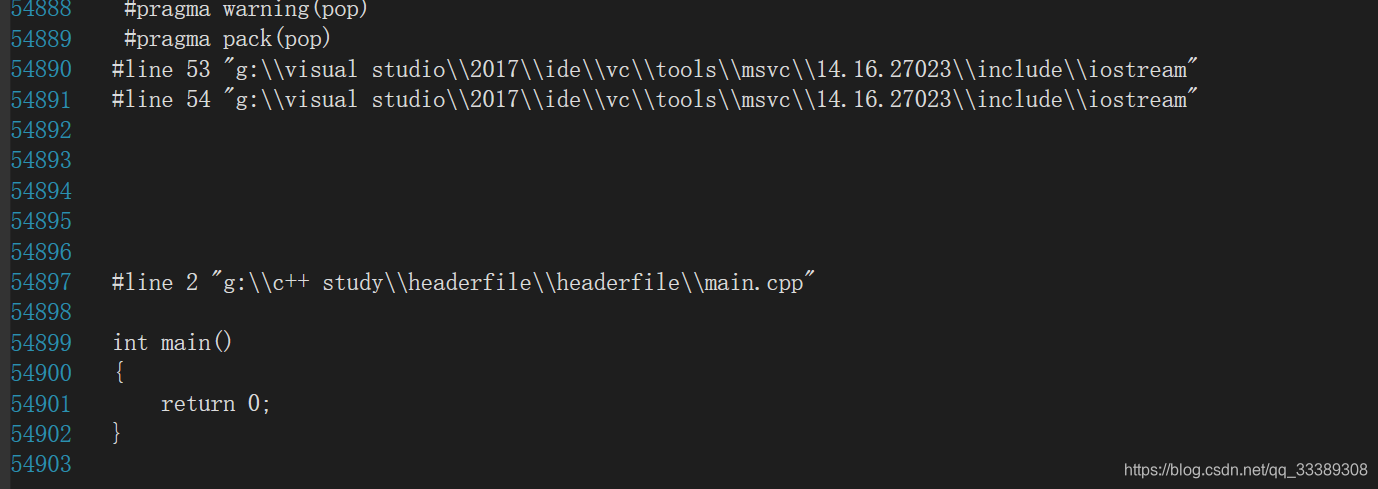
为什么我们只写了几行代码+include,编译生成的代码这么多行呢?这就和本节标题有关了:#include究竟做了些什么?答案其实很简单,编译器对于#include的处理就是把该文件的内容直接copy过来!而iostream是标准库的头文件,里面包含了太多东西,这才造成最终生成的代码量极大。
下面可以做一个有意思的事情,我们创建一个nothing.h文件,里面只写一个“}”字符,然后改一下main.cpp
//main.cpp
int main()
{
return 0;
#include "nothing.h"
//nothing.h
}
以上代码可以编译链接通过并执行,我们打开main.i文件查看编译结果如下:
#line 1 "g:\\c++ study\\headerfile\\headerfile\\main.cpp"
int main()
{
return 0;
#line 1 "g:\\c++ study\\headerfile\\headerfile\\nothing.h"
}
#line 5 "g:\\c++ study\\headerfile\\headerfile\\main.cpp"
是不是觉得很有意思?
本节总结:#include做的事情只是把头文件内的所有内容都copy到当前文件的当前位置
2.为什么头文件里面写函数声明
在入门C++时,教材和视频里都说了要在.h里写函数声明,而.cpp文件内部写函数定义,但是为什么这么做呢?我们可以写一个Math.cpp文件,里面写一个add函数,并修改main.cpp如下://main.cpp
#include <iostream>
int main()
{
std::cout<<add(1, 2);
system("pause");
return 0;
}
//Math.cpp
int add(int a, int b)
{
return a + b;
}
接触过C++的人知道,如果函数前面不声明为static,而且函数不在某个局部作用域内,这时候该函数就是全局函数,因此按理来说这个main.cpp应该能够完成编译、链接、运行。但结果显然是不对的,ctrl+F7编译的时候就开始报错了
这就是现在要说的,即使一个函数是全局函数,但是编译器在编译的时候需要找到这个函数的声明,我们修改main.cpp:
//修改后的main.cpp
#include <iostream>
int add(int a, int b);//添加函数声明
int main()
{
std::cout<<add(1, 2);
system("pause");
return 0;
}
再次编译发现没问题了。可以看到我们必须在本文件中添加用到的函数的声明,添加函数声明只是告诉编译器,我们有这么一个函数,让编译器能够编译通过。至于上哪寻找这个函数的定义,不归编译管,而是由链接来处理。
说到这里是不是开始对头文件的书写方式有些头绪了?没错,我们在头文件中写入函数声明,在对应的cpp文件内写函数定义,由于编译器对#include的处理就是简单的copy,因此就可以通过将头文件#include在其他cpp文件中完成函数声明!
本节总结:在头文件中写函数声明的目的是,其他文件include后能够获取函数声明,完成编译。
3.#program once和#ifndef等等
我们使用visual studio创建新头文件的时候,能够发现,vs给我们的头文件自带了一行#program once,这个有什么用呢?简单来说,就是防止该头文件被重复include到同一个cpp文件中。那么头文件被重复include到同一个cpp文件中会发生什么?我们可以在Math.h中添加了一个函数的定义或结构体的定义,因为有时候我们还是需要在头文件中写一些定义的,然后将这个头文件重复包含到main.cpp中//main.cpp
#include <iostream>
#include "Math.h"
#include "Math.h"//重复包含头文件
int main()
{
std::cout<<add(1, 2);
system("pause");
return 0;
}
//Math.h
int add(int a, int b);
struct matrix4x4 {
};
这个时候编译main.cpp可以发现报错了:
显然,编译器在预处理阶段,将Math.h的内容复制到main.cpp中两次,导致结构体被定义了两次。
对于重复include导致的函数重定义,有一个解决方法。我们可以将其声明为inline,这样在使用该函数的地方,就直接将函数体内容拿过去,这也是为什么头文件中可以写inline函数定义。
通用的解决方法就是在Math.h中加入#program once,#program once的作用就是防止该头文件被重复include到同一个cpp文件中,从而可以避免这种重定义问题。
在看别人写的代码时,经常也可以看到#ifndef、#define、#endif的组合,其实作用和#program once是一样的,比如我们可以将上面Math.h的内容改成下面的形式:
#ifndef _MATH_H_
#define _MATH_H_
int add(int a, int b);
struct matrix4x4 {
};
#endif //_MATH_H_
#ifndef、#define、#endif就是条件宏语句,也非常好理解。首先判断_MATH_H_这个宏是否被定义过,如果被定义过,则直接跳到#endif,这个一般写到文件结尾。如果没被定义过,那么就定义一下。宏定义的命名可以随意起,但是为了保证①代码易读②命名不重复,一般都用头文件的名字大写+下划线来进行命名。
本节总结:用#program once避免重复包含头文件