4、group by的优化
最好使用同一表中的列,
需求:每个演员所参演影片的数量-(影片表和演员表)
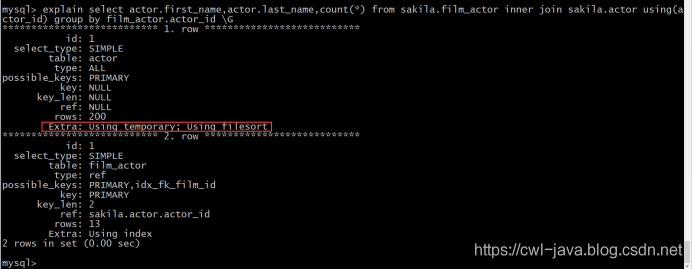
explain select actor.first_name,actor.last_name,count(*)
from sakila.film_actor
inner join sakila.actor using(actor_id)
group by film_actor.actor_id;
优化后的SQL:
explain select actor.first_name,actor.last_name,c.cnt
from sakila.actor inner join (
select actor_id,count(*) as cnt from sakila.film_actor group by actor_id
)as c using(actor_id);
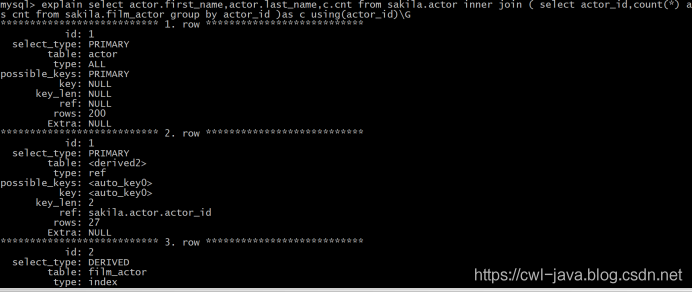
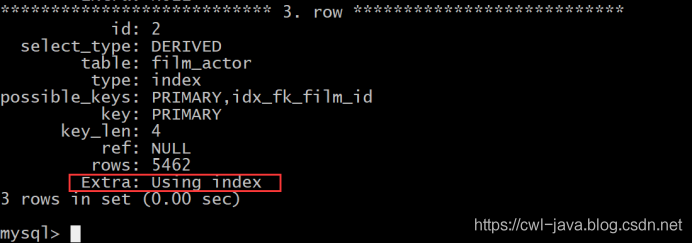
说明:从上面的执行计划来看,这种优化后的方式没有使用临时文件和文件排序的方式了,取而代之的是使用了索引。查询效率老高了。
这个时候我们表中的数据比较大,会大量的占用IO操作,优化了sql执行的效率,节省了服务器的资源,因此我们就需要优化。
注意:
1、mysql 中using关键词的作用:也就是说要使用using,那么表a和表b必须要有相同的列。
2、在用Join进行多表联合查询时,我们通常使用On来建立两个表的关系。其实还有一个更方便的关键字,那就是Using。
3、如果两个表的关联字段名是一样的,就可以使用Using来建立关系,简洁明了。
本文同步分享在 博客“cwl_java”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。