A
flume: 1.6.0
elasticSearch: 1.6.0
kibana: 4.1.3-linux-x64
下载地址:
http://mirrors.hust.edu.cn/apache/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.6.0.tar.gz
https://download.elastic.co/kibana/kibana/kibana-4.1.3-linux-x64.tar.gz
当前最新版:
https://download.elasticsearch.org/elasticsearch/release/org/elasticsearch/distribution/zip/elasticsearch/2.1.0/elasticsearch-2.1.0.zip
https://download.elastic.co/kibana/kibana/kibana-4.3.0-linux-x64.tar.gz
启动 elasticSearch
配置: config/elasticsearch.yml
启动: bin/elasticSearch -d
启动 kibana
先配置 config/kibana.yml
启动: bin/kibana
如果后台运行,可以使用这个 daemon.c
./daemon /data/elk/kibana-4.1.3-linux-x64/bin/kibana
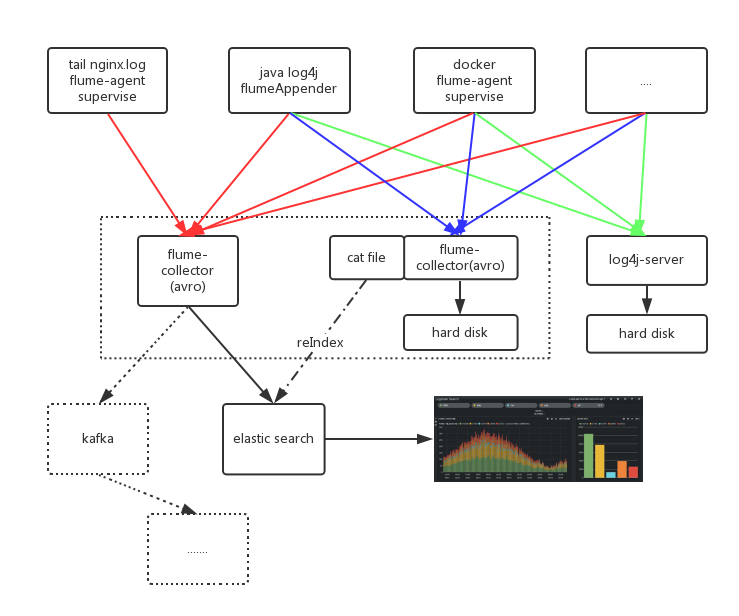
运行 flume (collector)
配置 avro.conf , sink有2个,分别输出到elasticSearch和文件(flume-ng-log4j-sink)
743
bin/flume-ng agent -c ./conf -f conf/avro.conf -n avroAgent -Dflume.root.logger=INFO,console
bin/flume-ng agent -c ./conf -f conf/tomcatLog.conf -n tomcatAgent -Dflume.root.logger=INFO,console
本地测试,使用 avro-client 上传一个文件内容,如果成功在 elasticSearch/kibana 就能看到数据
bin/flume-ng avro-client -c ./conf -H localhost -p 1234 -F /etc/passwd -Dflume.root.logger=DEBUG,console
flume-agent
如果是java项目可以使用 flume-ng-log4jappender 直接上传到avro
如果tail文件 则需要再增加一个保证agent存活的程序,如 daemontools, 而 daemontools 的存活需要使用系统服务来保证
flume-avro-elasticSearch-log4j
avroAgent.sources = avro
avroAgent.channels = memoryChannel fileCh
avroAgent.sinks = elasticSearch logfile
# For each one of the sources, the type is defined
avroAgent.sources.avro.type = avro
avroAgent.sources.avro.bind = 0.0.0.0
avroAgent.sources.avro.port = 1234
avroAgent.sources.avro.threads = 20
avroAgent.sources.avro.channels = memoryChannel
# Each sink's type must be defined
avroAgent.sinks.elasticSearch.type = org.apache.flume.sink.elasticsearch.ElasticSearchSink
#Specify the channel the sink should use
avroAgent.sinks.elasticSearch.channel = memoryChannel
avroAgent.sinks.elasticSearch.batchSize = 100
avroAgent.sinks.elasticSearch.hostNames=172.16.0.18:9300
avroAgent.sinks.elasticSearch.indexName=longdai
avroAgent.sinks.elasticSearch.indexType=longdai
avroAgent.sinks.elasticSearch.clusterName=longdai
avroAgent.sinks.elasticSearch.client = transport
avroAgent.sinks.elasticSearch.serializer=org.apache.flume.sink.elasticsearch.ElasticSearchLogStashEventSerializer
avroAgent.sinks.logfile.type = org.apache.flume.sink.log4j.Log4jSink
avroAgent.sinks.logfile.channel = memoryChannel
avroAgent.sinks.logfile.configFile = /home/apache-flume-1.6.0-bin/conf/log4j.xml
avroAgent.channels.fileCh.type = file
avroAgent.channels.fileCh.keep-alive = 3
avroAgent.channels.fileCh.overflowCapacity = 1000000
avroAgent.channels.fileCh.dataDirs = /data/flume/ch/data
# Each channel's type is defined.
avroAgent.channels.memoryChannel.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
avroAgent.channels.memoryChannel.capacity = 2000
avroAgent.channels.memoryChannel.transactionCapacity = 2000
avroAgent.channels.memoryChannel.keep-alive = 3
#-- END --flume-tail-elasticSearch
tomcatAgent.sources = tomcatLog
tomcatAgent.channels = memoryChannel
tomcatAgent.sinks = elasticSearch
# For each one of the sources, the type is defined
tomcatAgent.sources.tomcatLog.type = exec
# The channel can be defined as follows.
tomcatAgent.sources.tomcatLog.channels = memoryChannel
tomcatAgent.sources.tomcatLog.command = tail -F /data/longdai/logs/longdai.log
tomcatAgent.sources.tomcatLog.bufferCount = 200
# Each sink's type must be defined
tomcatAgent.sinks.elasticSearch.type = org.apache.flume.sink.elasticsearch.ElasticSearchSink
#Specify the channel the sink should use
tomcatAgent.sinks.elasticSearch.channel = memoryChannel
tomcatAgent.sinks.elasticSearch.batchSize = 100
tomcatAgent.sinks.elasticSearch.hostNames=172.16.0.18:9300
tomcatAgent.sinks.elasticSearch.indexName=longdai
tomcatAgent.sinks.elasticSearch.indexType=longdai
tomcatAgent.sinks.elasticSearch.clusterName=longdai
tomcatAgent.sinks.elasticSearch.client = transport
tomcatAgent.sinks.elasticSearch.serializer=org.apache.flume.sink.elasticsearch.ElasticSearchLogStashEventSerializer
# Each channel's type is defined.
tomcatAgent.channels.memoryChannel.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# In this case, it specifies the capacity of the memory channel
tomcatAgent.channels.memoryChannel.capacity = 100另:
cd /data/apache-flume-1.6.0-bin/
wget http://central.maven.org/maven2/org/elasticsearch/elasticsearch/1.6.0/elasticsearch-1.6.0.jar
mv elasticsearch-1.6.0.jar lib/
wget http://central.maven.org/maven2/org/apache/lucene/lucene-core/4.10.4/lucene-core-4.10.4.jar
mv lucene-core-4.10.4.jar lib/flume-agent 一定要修个 bin/flume-ng, 增大堆内存(Xmx默认20m), 如果使用memchannel总是感觉内存有问题,那就缓存file channel, 使用固态硬盘速度够用了
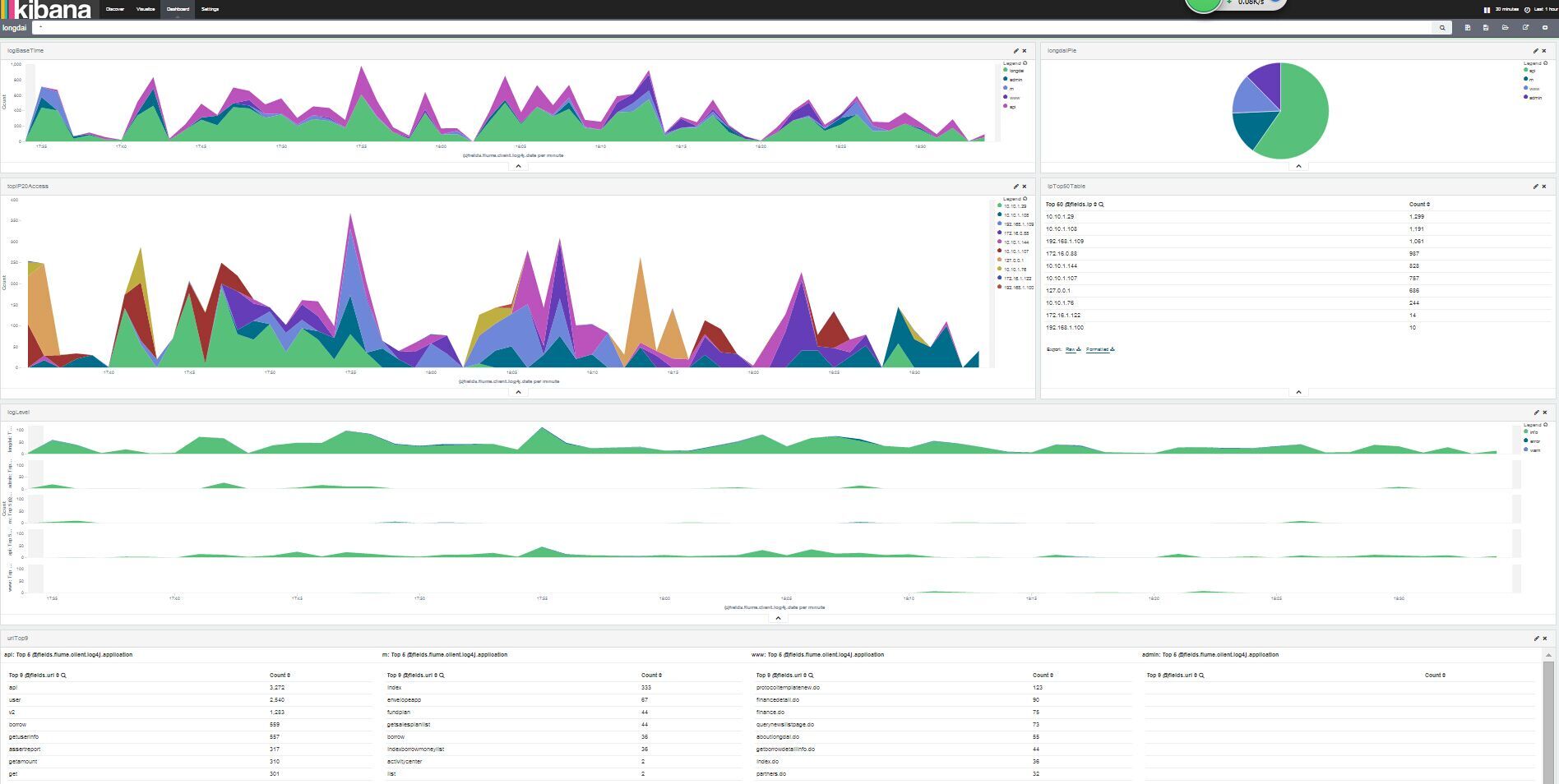
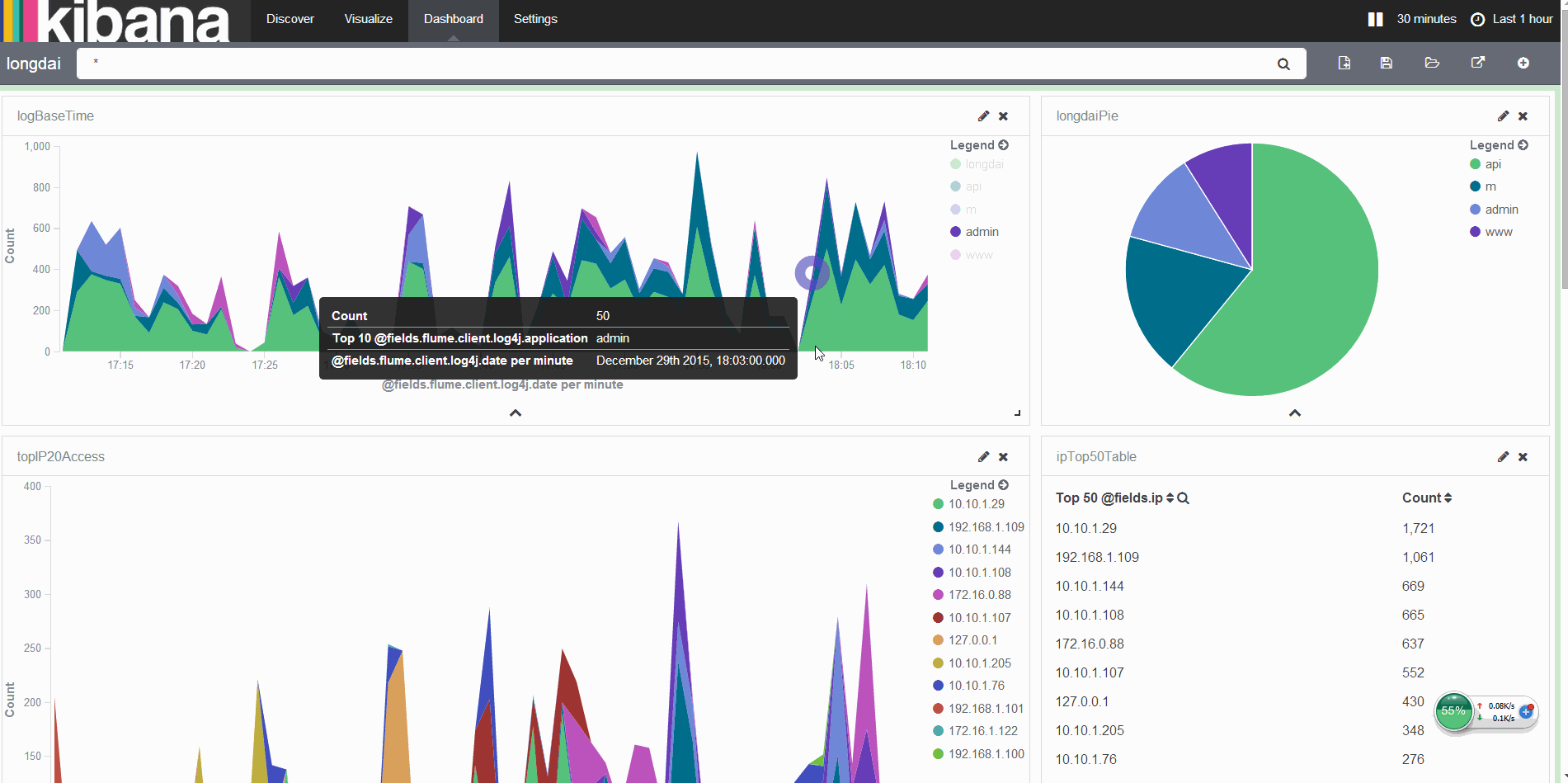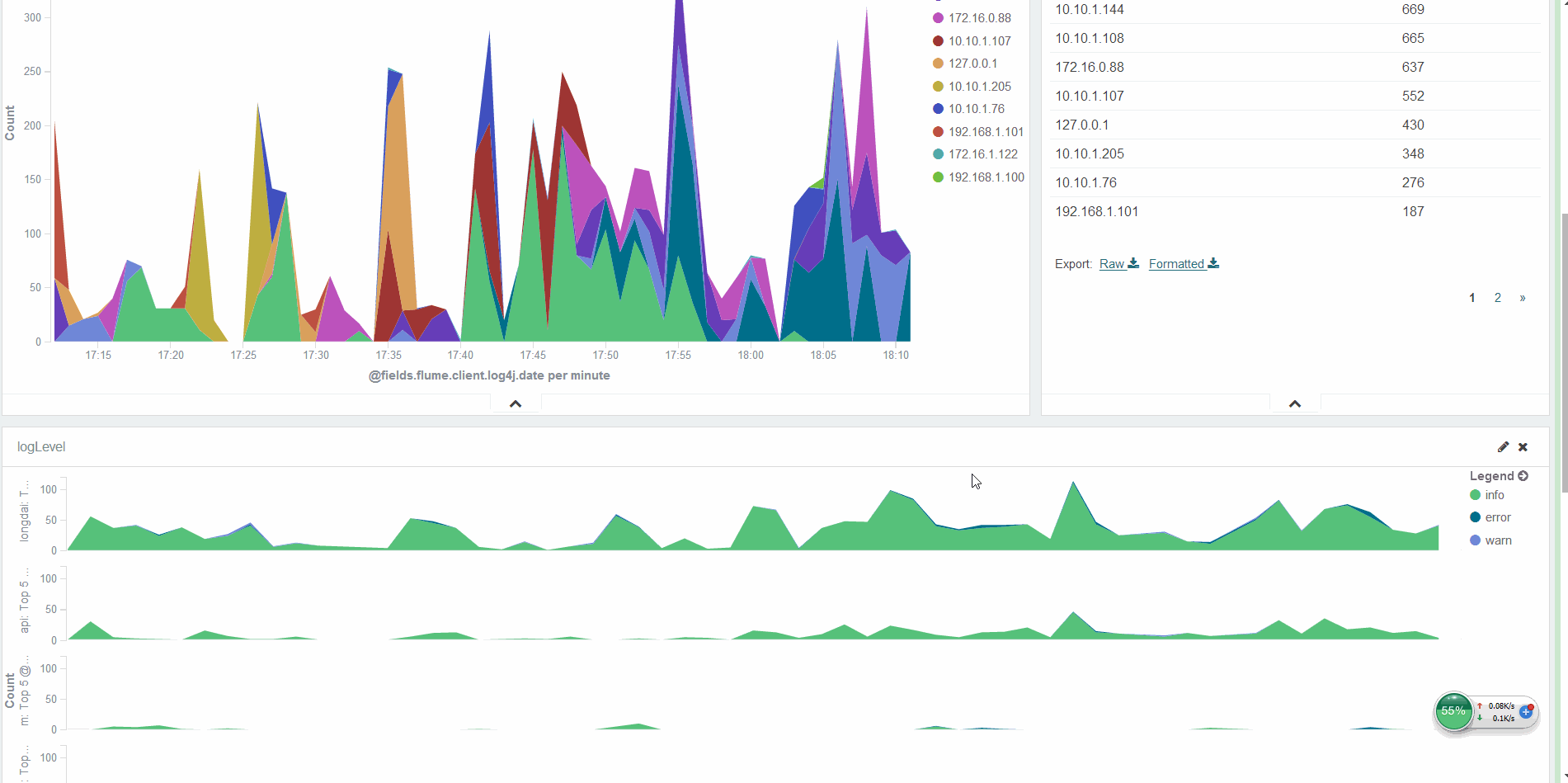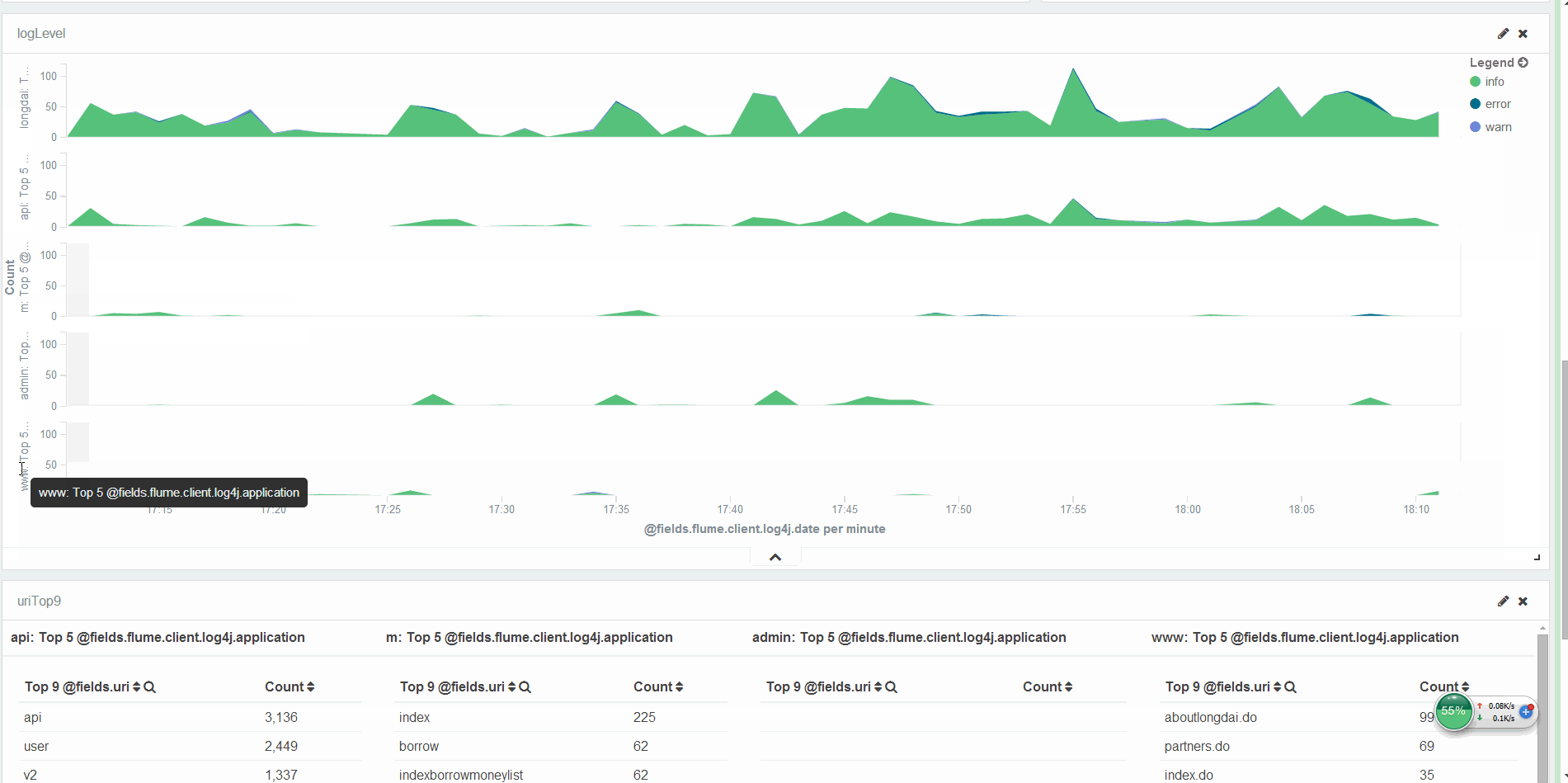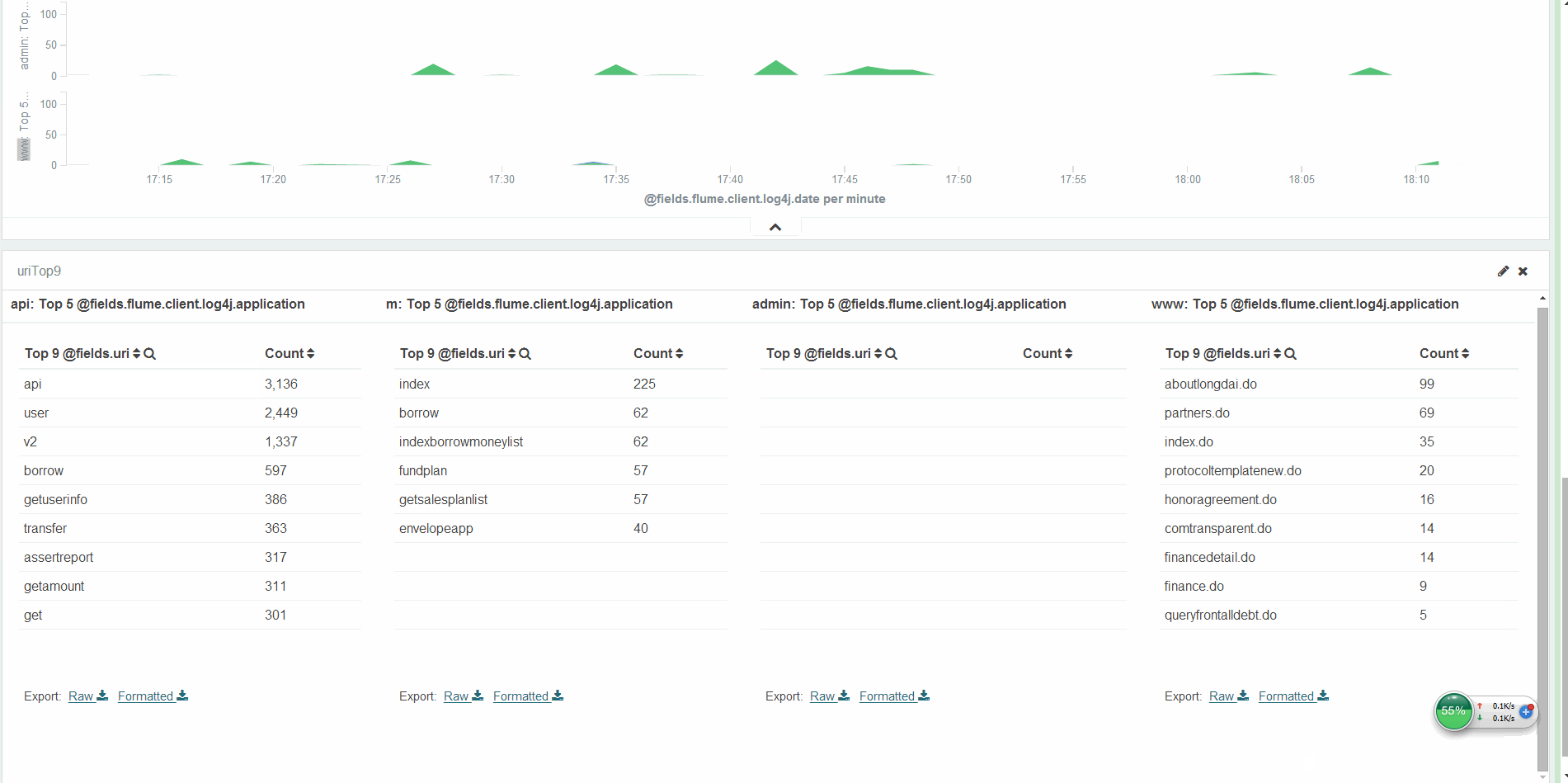
O
如果你的项目是java项目,且使用 log4j-1.x socket 收集日志也可以使用服务端log4j-collector收集,可以将日志按照自己需求路由到不同的appender。线上亲测,到目前为止无故障连续运行3个多月。可以搭配keepalive/deamontools使其更加稳定
