度量学习( Metric Learning):指给定数据集,学习一个从原始的数据空间到球面(嵌入空间)的映射。目的是让嵌入空间中同类型的样本距离近(即表示样本间的相似程度),不同类的远。又称为嵌入学习(Embedding learning), 监督表示学习 (supervised representation learning)。
噪音对比估计 (NCE):一种采样损失,用于降低计算的复杂度。以自然语言处理为例,当词汇库很大时去计算一个概率分布,在大量可能的类上计算softmax开销非常大。而NCE通过训练分类器从“真实”分布和人工生成的噪声分布中区分样本,从而简化为二分类问题。
对比学习:训练目标通常是噪声对比估计(noise-contrastive estimation),引导学习过的表示f将正对映射到锚点附近的位置,将负对映射到更远的位置。
“Hard”负样本:嵌入空间中难以与锚点“anchor”(即原始样本)区分的点。
主要贡献
1. 提出了一个新的无监督采样方法,用于选择用户可以控制难度的“Hard”负样本。
2、推导了一个负样本的抽样策略,其计算开销为零。
方法概要
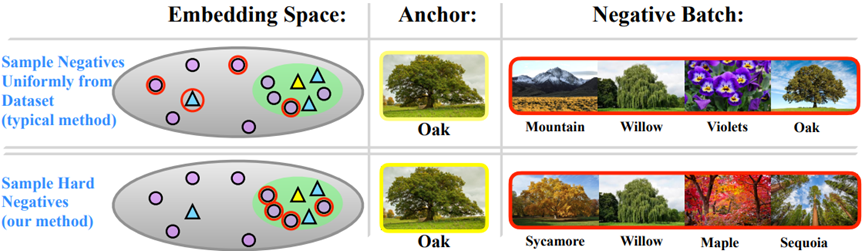
上图为典型抽样方法(上)与本文提出方法(下)的对比。嵌入空间中的黄色三角为锚点,带红圈的为抽样到的负样本,可见本文方法选取的都是难负样本,而典型方法选取的比较随机,甚至还有与锚点同类型的(同是三角形状),我们称这种负样本为“假负”,反之,不同类型称为“真负”。
公式推导
一、常规的对比学习损失公式:
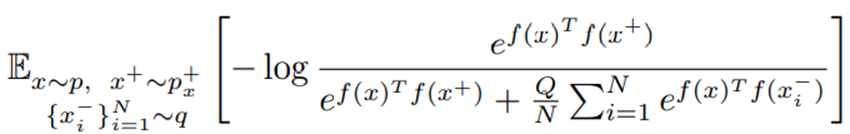
其中,q为负样本分布,通常为边界分布p。
二、作者提出的方法:
采样遵循两个原则:(1)只采样“真负”的样本。(类别判断) (2)采样与锚点相似的样本。(相似度判断)
1、难负样本的采样分布函数:
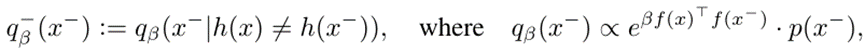
上式表示难负样本在与原样本的类别不同的条件下的概率分布(原则1)。 其中函数h(x)表示样本对应的潜在类,超参数β项控制qβ上负样本的“hard”程度,内积越大,qβ越大,难负样本与锚点越相似(原则2)。但是对于没有标签的数据(无监督)就不能直接判断出![]() ,所以原则1并没有解决。
,所以原则1并没有解决。
2、原则1的解决:采用PU-learning的方法重写分布,先把常规的负样本分布![]() 拆成来自同标签分布
拆成来自同标签分布![]() 与来自不同标签分布
与来自不同标签分布![]() 两部分:
两部分:
![]()
其中,超参数![]() 表示潜在类的分布(假设是均匀分布),
表示潜在类的分布(假设是均匀分布),![]() 表示另一个类的概率。
表示另一个类的概率。
再对来自同标签的样本应用原则2,即在条件{h(x) = h(x−)}作用下的概率分布:
![]()
3、最后整理一下公式,就得到满足原则1和原则2的难负样本分布:
![]()
4、本文提出的对比损失函数: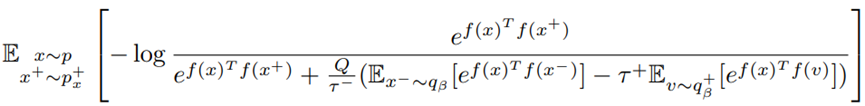
其中期望![]() 、
、![]() 分别表示总负样本和与锚点相似度很高的同类型负样本,作者在本文中采用蒙特卡罗(Monte-Carlo)重要性抽样技术来计算。
分别表示总负样本和与锚点相似度很高的同类型负样本,作者在本文中采用蒙特卡罗(Monte-Carlo)重要性抽样技术来计算。
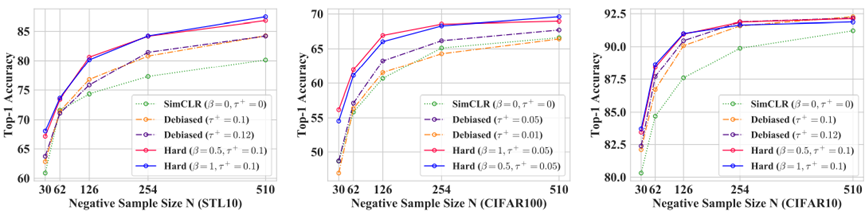
实验结果
下图为基于对比学习模型SimCLR在数据集STL10、CIFAR100和CIFAR10上测试难采样方法的测试结果。当负样本数N=510时,CIFAR100和STL10上SimCLR的绝对改善分别为3%和7.3%,而Debiased(最佳去偏基线,β=0)的绝对改善分别为1.9%和3.2%。而在CIFAR10上,较小的N有轻微的改善,但在较大的N时,这种改善消失了。