多流转换
文章目录
下一章: Flink 1.13 状态编程与容错机制
一、分流
针对同一条流多次独立调用.filter()方法进行筛选,就可以得到拆分之后的流,它将原始数据流 stream 复制三份,然后对每一份分别做筛选;这明显是不够高效。
早期的版本中,DataStream API 中提供了一个.split()方法,基本思路是按照筛选条件,给数据分类“盖戳”;然后基于这条盖戳之后的流,分别拣选想要的“戳”就可以得到拆分后的流。因为只是“盖戳”拣选,所以无法对数据进行转换,分流后的数据类型必须跟原始流保持一致。这就极大地限制了分流操作的应用场景。
推荐使用使用侧输出流。
二、基本合流
1. 联合(Union)
直接将多条流合在一起,叫作流的“联合”(union)
联合操作要求必须流中的数据类型必须相同,对于合流之后的水位线,也是要以最小的那个为准,多流合并时处理的时效性是以最慢的那个流为准的。
stream1.union(stream2, stream3, ...)
2. 连接(Connect)
2.1 基本连接流(ConnectedStreams)
连接(connect):直接把两条流像接线一样对接起来,连接操作允许流的数据类型不同。
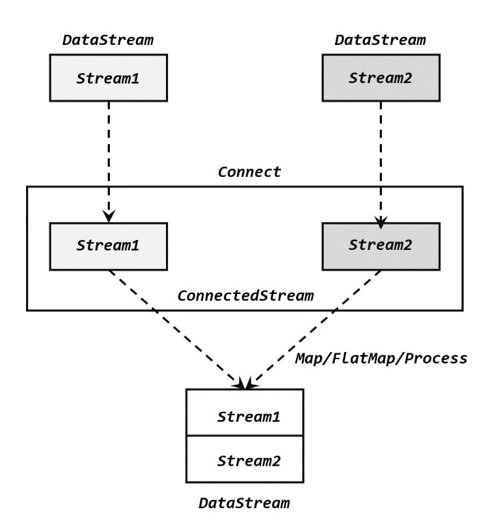
CoMapFunction 的简单示例,类似于MapFunction,实现两个map方法,CoFlatMapFunction也类似于FlatMapFunction,就不举例了。
ConnectedStreams<Integer,Long> connectedStreams = stream1.connect(stream2);
connectedStreams.map(
new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer value) {
return "Integer: " + value;
}
@Override
public String map2(Long value) {
return "Long: " + value;
}
});
CoProcessFunction示例:实现一个实时对账的需求,也就是 app 的支付操作和第三方的支付操作的一个双流 Join。App 的支付事件和第三方的支付事件将会互相等待 5 秒钟,如果等不来对应的支付事件,那么就输出报警信息。
// 检测同一支付单在两条流中是否匹配,不匹配就报警
appStream.connect(thirdpartStream)
.keyBy(data -> data.f0, data -> data.f0)
.process(new CoProcessFunction<Tuple3<String, String, Long>,Tuple4<String, String, String, Long>, String>{
// 定义状态变量,用来保存已经到达的事件
private ValueState<Tuple3<String, String, Long>> appEventState;
private ValueState<Tuple4<String,String,String,Long>> thirdPartyEventState;
@Override
public void open(Configuration parameters) throws Exception {
//初始化两个状态
appEventState = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple3<String,String, Long>>(
"app-event",
Types.TUPLE(Types.STRING, Types.STRING, Types.LONG)));
thirdPartyEventState = getRuntimeContext().getState(
new ValueStateDescriptor<Tuple4<String, String, String,Long>>(
"thirdparty-event",
Types.TUPLE(Types.STRING,Types.STRING,Types.STRING,Types.LONG)));
}
@Override
public void processElement1(Tuple3<String, String, Long> value,
Context ctx, Collector<String> out) throws Exception {
// 看另一条流中事件是否来过
if(thirdPartyEventState.value() != null){
out.collect("对账成功:" + value + " " +thirdPartyEventState.value());
thirdPartyEventState.clear(); // 清空状态
} else {
appEventState.update(value); // 更新状态
// 注册一个5秒后的定时器,开始等待另一条流的事件
ctx.timerService().registerEventTimeTimer(value.f2 + 5000L);
}
}
@Override
public void processElement2(Tuple4<String, String, String, Long> value,
Context ctx, Collector<String> out) throws Exception {
if (appEventState.value() != null){
out.collect("对账成功:" + appEventState.value() + " " + value);
appEventState.clear(); // 清空状态
} else {
thirdPartyEventState.update(value); // 更新状态
// 注册一个5秒后的定时器,开始等待另一条流的事件
ctx.timerService().registerEventTimeTimer(value.f3 + 5000L);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx,
Collector<String> out) throws Exception {
//定时器触发,判断状态,如果某个状态不为空,说明另一条流中事件没来
if (appEventState.value() != null) {
out.collect("对账失败:"+appEventState.value()+" "+"第三方支付平台信息未到");
}
if (thirdPartyEventState.value() != null) {
out.collect("对账失败:"+thirdPartyEventState.value()+" "+"app信息未到");
}
appEventState.clear();
thirdPartyEventState.clear();
}
}).print();
2.2 广播连接流(BroadcastConnectedStreams)
DataStream 调用.connect()方法时,传入的参数也可以不是一个DataStream,而是一个“广播流”(BroadcastStream),这时合并两条流得到的就变成了一个“广播连接流”。
这种连接方式往往用在需要动态定义某些规则或配置的场景。因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state)。
广播状态底层是用一个“映射”(map)结构来保存的。
//将ruleStream广播出去,这里需要传入一个MapState的描述器参数
MapStateDescriptor<String,Rule> ruleStateDescriptor=new MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream=ruleStream.broadcast(ruleStateDescriptor);
stream.connect(ruleBroadcastStream).process(new BroadcastProcessFunction<>() {...} );
public abstract class BroadcastProcessFunction<IN1, IN2, OUT> extends BaseBroadcastProcessFunction {
...
public abstract void processElement(IN1 value, ReadOnlyContext ctx,
Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx,
Collector<OUT> out) throws Exception;
...
}
三、基于时间的合流–双流联结(Join)
1.窗口联结(Window Join)
两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数 (first,second)传入JoinFunction/FlatJoinFunction 的.join()方法进行计算处理。
stream1.join(stream2)
.where(r -> r.f0).equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String,Long>,Tuple2<String,Long>,String>() {
@Override
public String join(Tuple2<String, Long> left,Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
}).print();
类似于 SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
2. 间隔联结(Interval Join)
隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
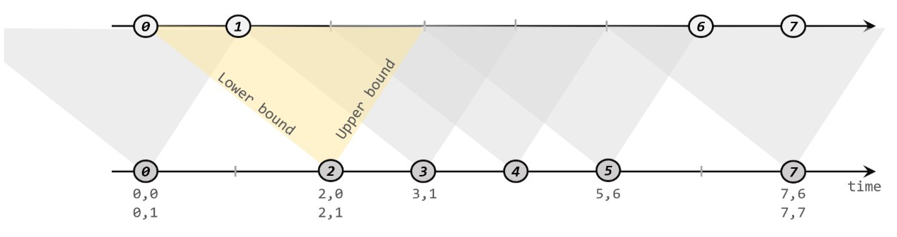
底层调用的是keyby+connect ,处理逻辑:
- 1)判断是否迟到(迟到就不处理了)
- 2)每条流都存了一个Map类型的状态(key是时间戳,value是List存数据)
- 3)任一条流,来了一条数据,遍历对方的map状态,能匹配上就发往join方法
- 4)超过有效时间范围,会删除对应Map中的数据(不是clear,是remove)
Interval join不会处理join不上的数据,如果需要没join上的数据,可以用coGroup或者connect算子实现,或者直接使用flinksql里的left join或right join。
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(
new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>(){
@Override
public void processElement(Tuple3<String, String, Long> left, Event right,
Context ctx, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
}
).print()
3. 窗口同组联结(Window CoGroup)
coGroup 操作比窗口的 join 更加通用,不仅可以实现类似 SQL 中的“内连接”(inner join),也可以实现左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。窗口 join 的底层,也是通过 coGroup 来实现的。
stream1.coGroup(stream2)
.where(r -> r.f0).equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(
new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1,Iterable<Tuple2<String, Long>> iter2,
Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
}
).print();
// 结果:
// [(a,1000), (a,2000)]=>[(a,3000), (a,4000)]
CoGroupFunction内部的.coGroup()方法,有些类似于 FlatJoinFunction 中.join()的形式,同样有三个参数,分别代表两条流中的数据以及用于输出的收集器(Collector)。不同的是,这里的前两个参数不再是单独的每一组“配对”数据了,而是传入了可遍历的数据集合。也就是说,现在不会再去计算窗口中两条流数据集的笛卡尔积,而是直接把收集到的所有数据一次性传入,至于要怎样配对完全是自定义的。
四、Flink 常见的维表 Join 方案
1. 预加载
通过富函数的生命周期方法 open(),查询维表,存储下来 ==》 定时查询最小维表数据。
2. 热存储
存在外部系统redis、hbase等,可以使用旁路缓存、异步IO查询方法提高并发。
3.广播维表
使用广播连接流的方式
4. Temporal join
外部存储,connector创建
要怎样配对完全是自定义的。
下一章: Flink 1.13 状态编程与容错机制