1、hive 的概念
首先我们在最初接触hive的时候就是书写SQl,所以会误以为hive是一个数据库。然而hive并不是数据库。
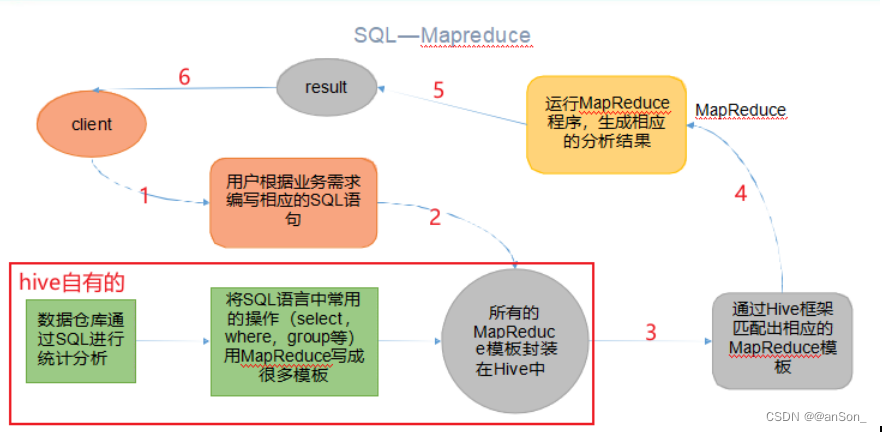
hive由Facebook开源用于解决海量结构化日志的数据统计工具,或者说是数据仓库的工具,其最大的作用就是将HQL转化成MapReduce程序,然后对数据进行处理,如下是其实现的流程。
2、hive的架构
hive管理数据会将元数据结构化存储在数据库中,可以是mysql;
hive是基于hdfs文件系统以SQl形式对数据统计分析的工具,所以了解hive主要是看它的SQL运行是怎么实现的。
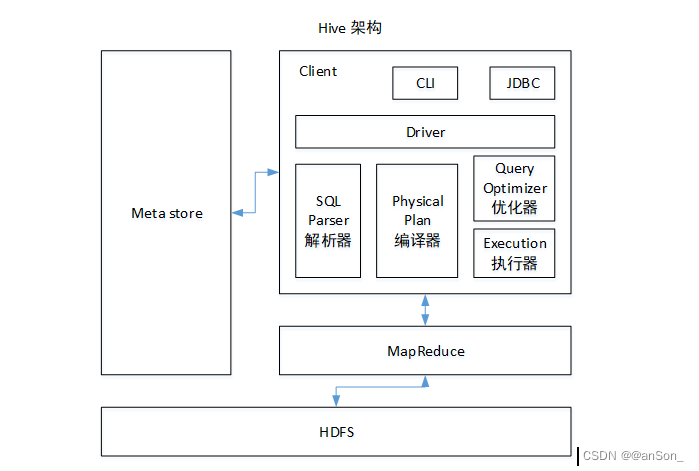
2.1 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.2 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
Derby数据库只支持一个连接,只能做测试
2.3 Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
2.4 驱动器:Driver
(1)解析器(SQL Parser):通过映射关系,如把from后面的表名找到数据的所在地。将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):把hql编译成mr的程序。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
3、hiveSQl执行基本流程
3.1 UI调用driver的接口;
3.2 driver为查询创建会话句柄,并将查询发送到Compiler(编译器)生成执行计划;
3.3 编译器从元数据存储中获取本次查询所需的元数据,该数据用于对查询树中的表达式进行类型检查,以及基于查询谓词修建分区;
3.4 编辑器生成的计划是分阶段的DAG,每个阶段要么是map/reduce作业,要么是一个元数据或者HDFS上的操作,将生成的计划发给driver。如果是map/reduce作业,该计划包括map operator trees和一个reduce operator tree,执行引擎将会把这些作业发送给MapReduce
3.5 执行引擎将这些阶段提交给适当的组件。在每个task(mapper/reducer)中,从HDFS文件中读取与表或中间输出相关联的数据,并通过相关算子树传递这些数据。最终这些数据通过序列化器写入一个临时HDFS文件中(如果不需要reduce阶段,则在map中操作)。临时文件用于向计划中后面的map/reduce阶段提供数据。
3.6 最终的临时文件将移动到表的位置,确保不读脏数据,对于用户的查询,临时文件的内容由执行引擎直接从HDFS读取,然后通过driver发送到UI。
4、建表测试
--创建启动日志表 drop table if exists ods_start_log; CREATE EXTERNAL TABLE ods_start_log (`line` string) PARTITIONED BY (`dt` string) -- 按照时间创建分区 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' -- 指定存储方式,读数据采用LzoTextInputFormat OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/offline/ods/ods_start_log'; -- 指定数据要在hdfs上存储的位置
//导入数据 load data inpath '/offline_data/log/topic_start/2022-09-10' into table demo.ods_start_log partition(dt='2022-09-10');
-- 在服务器上运行 为LZO压缩文件创建索引 hadoop jar /opt/software/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/offline/ods/ods_start_log/dt=2022-09-10
值得一提的是,建表的时候配置参数很重要,比如选择写入普通写入、列式写入,还是行式写入,不同的写入方式在读的时候会有不同的效果。另外,分区也能在查找的时候大大提高查找效率。