Xpath
详细的Xpath介绍手册——> https://www.w3school.com.cn/xpath/index.asp

1.安装xpath.
pip install lxml
2.安装谷歌XPath插件
下载:chrome_Xpath_v2.0.2.crx 格式的文件。拖进插件即可。
如果安装不成功,将后缀名改成.rar,解压以后再拖拽进去就可以使用了。
效果图(减头所指的地方就可以打开XPath):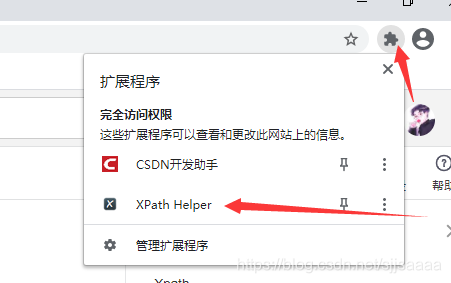

3.介绍
Xpath是在一门在XML文档种查找信息的语言。XPath可用来在XML文档种对元素和属性进行遍历,XPath是W3C XSLT标准的主要元素,并且XQuery和XPointer都构建于XPath表达之上。
4.节点的关系
- 父(Parent)
- 子(Children)
- 同胞(Sibling)
- 先辈(Ancestor)
- 后代(Descendant)
一、选取节点
1.常用的路径表达式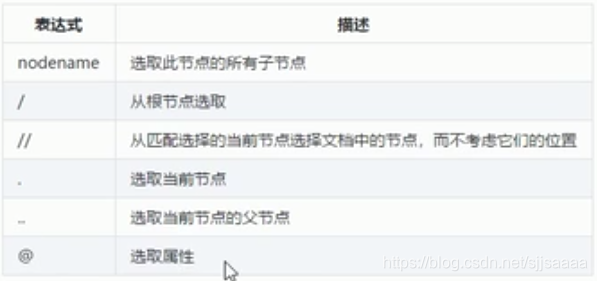
2.通配符
XPath通配符可用来选取未知的XML元素:
3.选取若干路径
4.谓语
谓语被嵌在方括号内,用来查找某个特定的节点或包含某个指定的值的节点。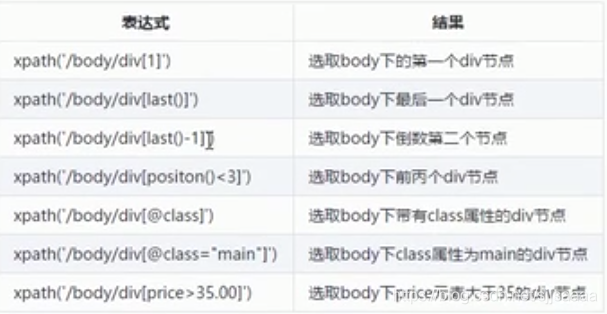
5.XPath运算符
二、案例
爬取起点中文网,排行里面小说的名称和作者。
首先要明确要什么: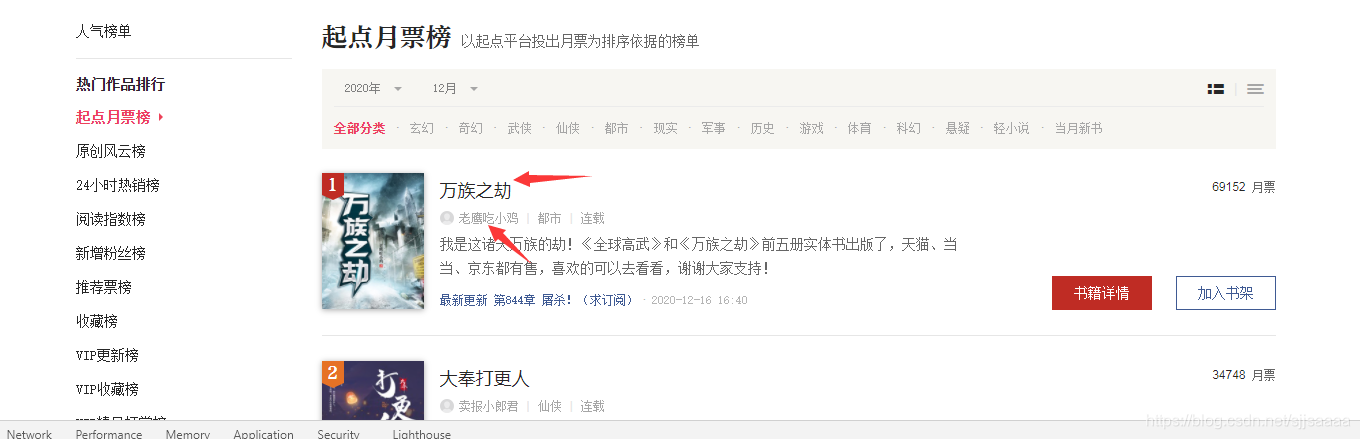
再用我们下载的谷歌XPath,找到相应的位置:

再找到作者的位置:
这样就提取到了我们想要的东西。
代码:
先导入库和获取页面:
from lxml import etree
import requests
from fake_useragent import UserAgent
url = "https://www.qidian.com/rank/yuepiao?chn=-1"
headers = {"User-Agent":UserAgent().random}
response = requests.get(url,headers)
e = etree.HTML(response.text)
利用XPath获取标题:
names = e.xpath('//h4/a/text()')
names

获取作者信息:
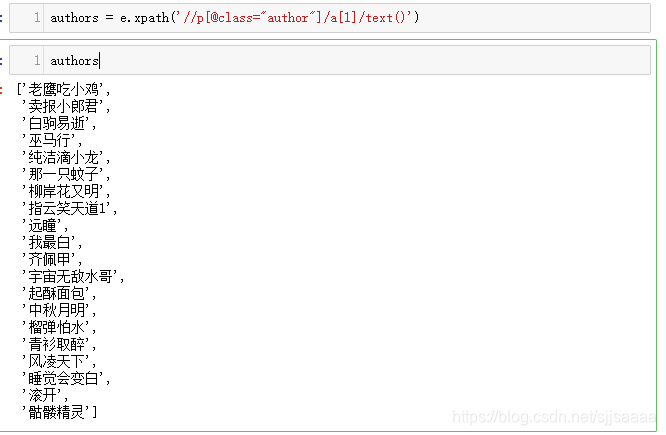
authors = e.xpath('//p[@class="author"]/a[1]/text()')
authors
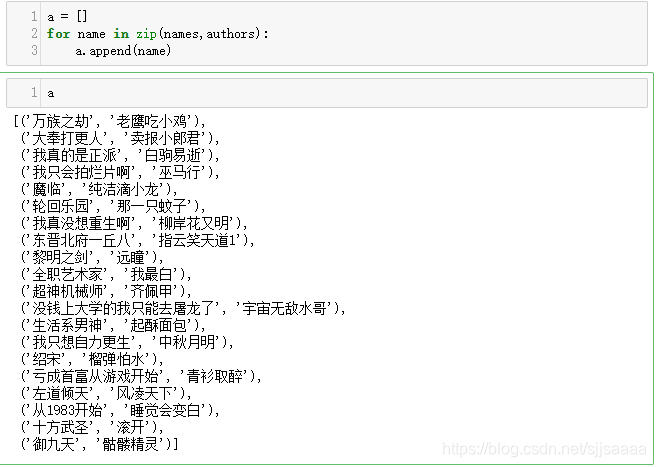
将书名和作者一一对应:
a = []
for name in zip(names,authors):
a.append(name)
a
版权声明:本文为sjjsaaaa原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。