整体步骤:选择鸢尾花数据集进行训练模型,然后根据生成的模型来开发模型API,通过API进行预测(Postman)
1.鸢尾花数据集准备(网上找呗)
2.鸢尾花数据训练GBDT.pkl模型,数据集、训练脚本、预测脚本同一级目录下即可
各包版本(建议使用anaconda,然后在pip install xgboost就行了):
matplotlib3.2.2
joblib0.16.0
xgboost1.2.1
Flask1.1.2
numpy1.18.5
pandas1.0.5
scikit_learn==0.23.2
# -*- coding:utf-8 -*-
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
import numpy as np
from joblib import dump,load
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def load_data():
import pandas as pd
iris = pd.read_csv("Iris.csv")
iris.drop(axis=0, columns="Id", inplace=True) #取除多余行
iris.drop_duplicates(inplace=True) #取除重复的行
labels = iris.iloc[::,4:].values #花的类型标签
species = set(labels.flatten()) #flatten()展平数组
label_type = {}
for i,j in enumerate(species):
label_type[j]=i
#print(label_type)
#用数字代替花的类别,对应的关系为label_type = {'Iris-versicolor': 0, 'Iris-virginica': 1, 'Iris-setosa': 2}
iris["Species"] = iris["Species"].map(label_type)
labels = iris.iloc[::,4:].values #数值类型标签
datas = iris.iloc[::,:4].values #样本
return datas,labels.flatten()
if __name__ == "__main__":
X,Y = load_data()
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.3,random_state=1)
clf=XGBClassifier(base_score=0.5, booster='gbtree', learning_rate=0.05, max_depth=8, n_estimators=50)
#训练
clf.fit(X_train, Y_train)
#保存模型
dump(clf,"GDBT.pkl")
#预测
model = load("GDBT.pkl")
#打分
print('GDBT the accuracy:\t',model.score(X_test, Y_test))
plt.scatter(range(len(X_test)),model.predict(X_test),marker="x",c="r",label="预测类别")
plt.scatter(range(len(X_test)),Y_test,marker="o",c="b",label="真实类别") #局部汉字 fontproperties="SimHei"
plt.title("预测与真实效果图")
plt.legend()
plt.savefig("预测与真实效果图.png")
#plt.show()
3.Flask框架开发鸢尾花模型API
# -*- coding:utf-8 -*-
#模型API服务参考:https://www.imooc.com/article/259009
"""
输入:
{
"SepalLengthCm": 5.7,
"SepalWidthCm": 3.0,
"PetalLengthCm": 4.2,
"PetalWidthCm": 1.2
}
输出:
{
"species": [
0
]
}
"""
from joblib import load
import numpy as np
import traceback
import sys
import pandas as pd
from flask import request
from flask import Flask
from flask import jsonify
app = Flask(__name__)
#http://192.168.1.34:8000/api/GBDT_iris/predict
name = "GBDT_iris"
@app.route(f'/api/{name}/predict', methods=['POST'])
def predict():
if model:
try:
json = request.json
data = pd.DataFrame([json])
predict_data = data.values
#return jsonify({"data":predict_data.tolist()}) #predict_data为numpy的array类型,json不识别,所以转换
prediction = model.predict(predict_data)
#return jsonify({"species":prediction.tolist()}) #输入预测类别
for i in list(label_type.keys()):
if label_type[i] == prediction[0]:
return jsonify({"鸢尾花的预测类型为":[i]})
except:
return jsonify({'trace': traceback.format_exc()})
else:
return '模型不可用'
if __name__ == '__main__':
label_type = {'Iris-versicolor': 0, 'Iris-virginica': 1, 'Iris-setosa': 2}
try:
port = int(sys.argv[1])
except:
port = 8888
model = load('GBDT.pkl')
#predict()
app.run(host='192.168.1.34', port=port, debug=True)
4.使用postman调用预测API
注意:在使用postman调API时,预测基本必须处于运行中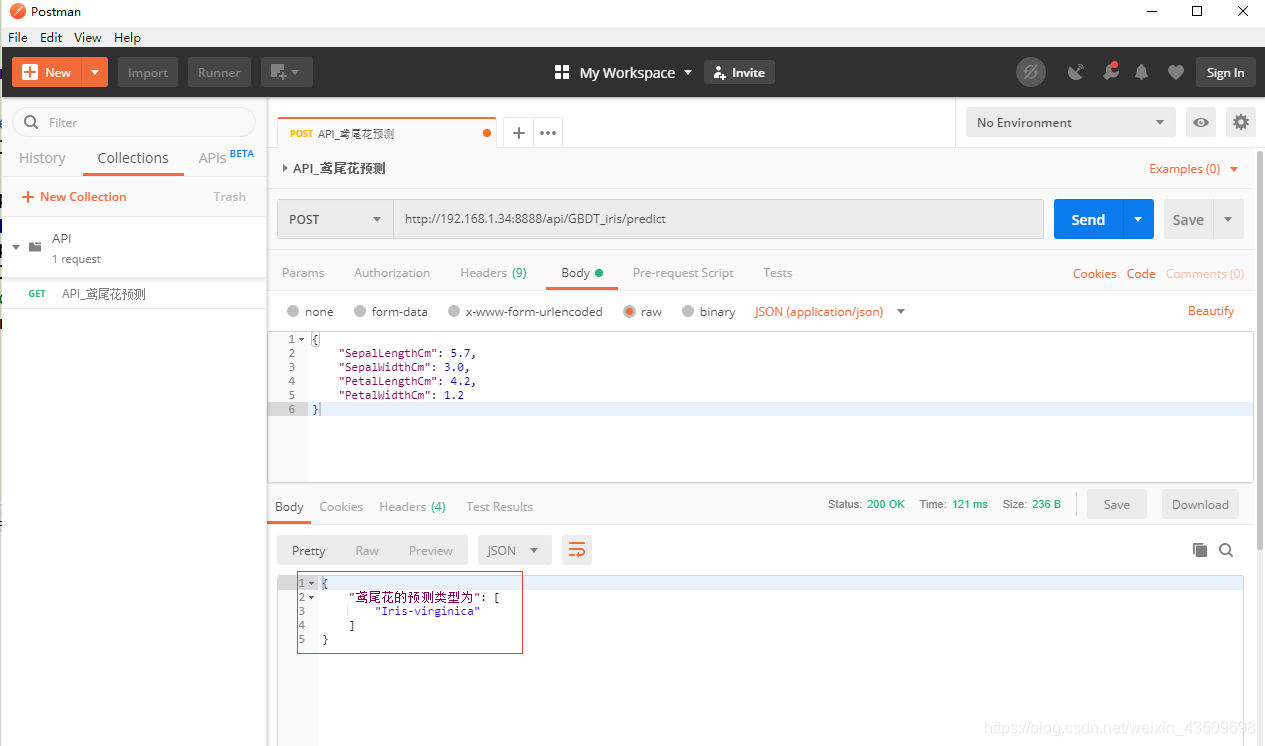

模型API参考:https://www.imooc.com/article/259009
注:纸上得来终觉浅,绝知此事要躬行。
版权声明:本文为weixin_43509698原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。