UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 12423: illegal multibyte sequence,读取ANSI文件
问题描述:
在读取文件的时候遇到了报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 12423: illegal multibyte sequence,这个时候大家可能会把参数encodin改成utf-8,但是改成utf-8之后又会出现UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 12423: invalid start byte。通过记事本打开文件发现其确实是ANSI编码(使用gbk应该是可以的)
example = open('49960', 'r')
print(example.read())
原因分析:
编码问题,可能是出现了gbk无法表示的特殊字符,即虽然文件是gbk编码但是由于部分字符超出了gbk的表示范围所以无法读取。
尝试解决:
1. 修改编码
使用表示范围更广的gb18030编码
example = open('49960', 'r', encoding='gb18030')
print(example.read())
但仍然报错UnicodeDecodeError: 'gb18030' codec can't decode byte 0xff in position 12423: illegal multibyte sequence
2. 更换读取模式
把读取模式由r修改为rb
example = open('49960', 'rb')
print(example.read())
成功读取出内容,但由于是二进制我希望它能够以十进制的方式读取出来
3. 忽略报错
example = open('49960', 'r', encoding='gbk', errors='ignore')
print(example.read())
成功读取!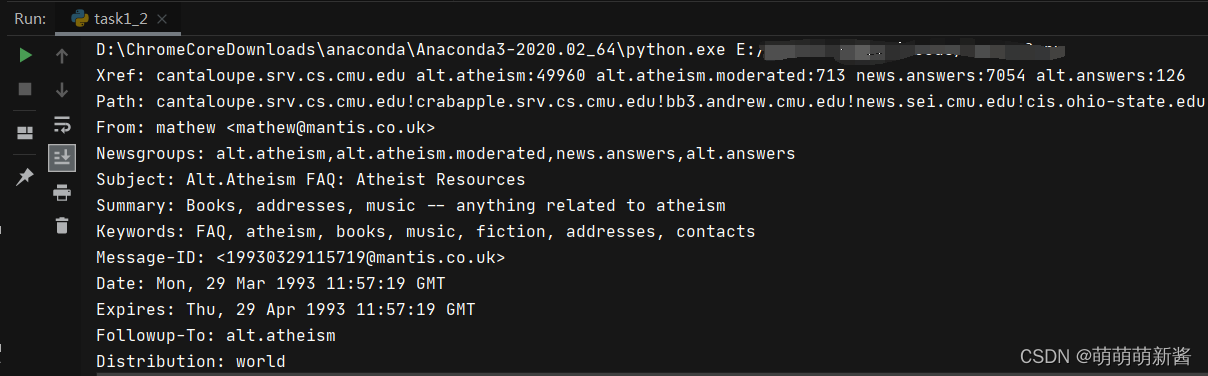
版权声明:本文为qq_46213352原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。