1、zk实现分布式锁
1、临时节点: 回话链接失效后,值自动删除
2、使用临时节点,多个服务在zk上创建同一个临时节点,不能重复,只有那个创建成功,哪个就拿到锁
3、其他服务没有创建成功,应该等待, watcher事件监听节点被删除,重新进入到获取锁资源
2、负载均衡算法
- 权重
- IP绑定
- 轮询机制
3、zk负载均衡原理
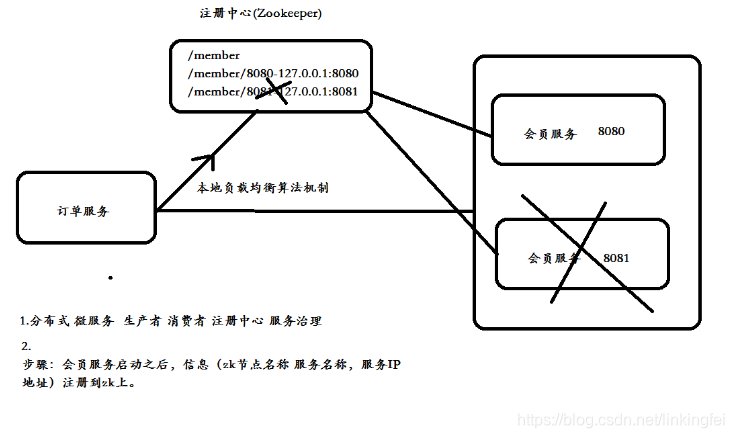
使用Zookeeper实现负载均衡原理,服务器端将启动的服务注册到,zk注册中心上,采用临时节点。客户端从zk节点上获取最新服务节点信息,本地使用负载均衡算法,随机分配服务器。
在分布式实现对服务管理
dubbo临时节点
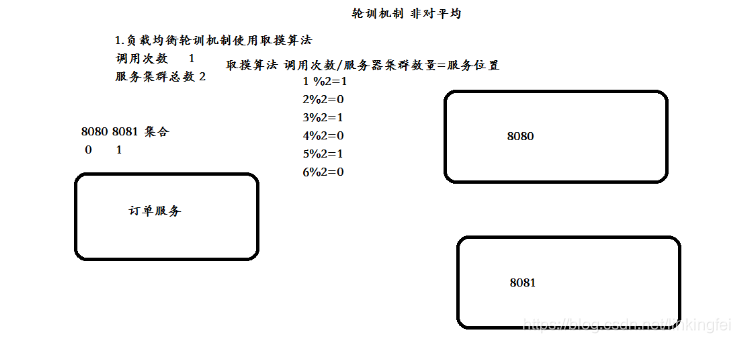
实现轮询机制: 取模算法
ZkServerScoekt服务
//##ServerScoekt服务端
public class ZkServerScoekt implements Runnable {
private int port = 18080;
public static void main(String[] args) throws IOException {
ZkServerScoekt server = new ZkServerScoekt(port);
Thread thread = new Thread(server);
thread.start();
}
public ZkServerScoekt(int port) {
this.port = port;
}
public void regServer() {
// 向ZooKeeper注册当前服务器
ZkClient client = new ZkClient("127.0.0.1:2181", 60000, 1000);
String path = "/test/server" + port;
if (client.exists(path))
client.delete(path);
client.createEphemeral(path, "127.0.0.1:" + port);
}
public void run() {
ServerSocket serverSocket = null;
try {
serverSocket = new ServerSocket(port);
System.out.println("Server start port:" + port);
Socket socket = null;
while (true) {
socket = serverSocket.accept();
new Thread(new ServerHandler(socket)).start();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (serverSocket != null) {
serverSocket.close();
}
} catch (Exception e2) {
}
}
}
}
ZkServerClient
public class ZkServerClient {
public static List<String> listServer = new ArrayList<String>();
public static void main(String[] args) {
initServer();
ZkServerClient client= new ZkServerClient();
BufferedReader console = new BufferedReader(new InputStreamReader(System.in));
while (true) {
String name;
try {
name = console.readLine();
if ("exit".equals(name)) {
System.exit(0);
}
client.send(name);
} catch (IOException e) {
e.printStackTrace();
}
}
}
// 注册所有server
public static void initServer() {
final String path = "/test";
final ZkClient zkClient = new ZkClient("127.0.0.1:2181", 60000, 1000);
List<String> children = zkClient.getChildren(path);
listServer.clear();
for (String p : children) {
listServer.add((String) zkClient.readData(path + "/" + p));
}
// 订阅节点变化事件
zkClient.subscribeChildChanges("/test", new IZkChildListener() {
public void handleChildChange(String parentPath, List<String> currentChilds) throws Exception {
listServer.clear();
for (String p : currentChilds) {
listServer.add((String) zkClient.readData(path + "/" + p));
}
System.out.println("####handleChildChange()####listServer:" + listServer.toString());
}
});
}
// 请求次数
private static int count = 1;
// 服务数量
private static int serverCount=2;
// 获取当前server信息
public static String getServer() {
String serverName = listServer.get(count%serverCount);
++count;
return serverName;
}
public void send(String name) {
String server = ZkServerClient.getServer();
String[] cfg = server.split(":");
Socket socket = null;
BufferedReader in = null;
PrintWriter out = null;
try {
socket = new Socket(cfg[0], Integer.parseInt(cfg[1]));
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out = new PrintWriter(socket.getOutputStream(), true);
out.println(name);
while (true) {
String resp = in.readLine();
if (resp == null)
break;
else if (resp.length() > 0) {
System.out.println("Receive : " + resp);
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (out != null) {
out.close();
}
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (socket != null) {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
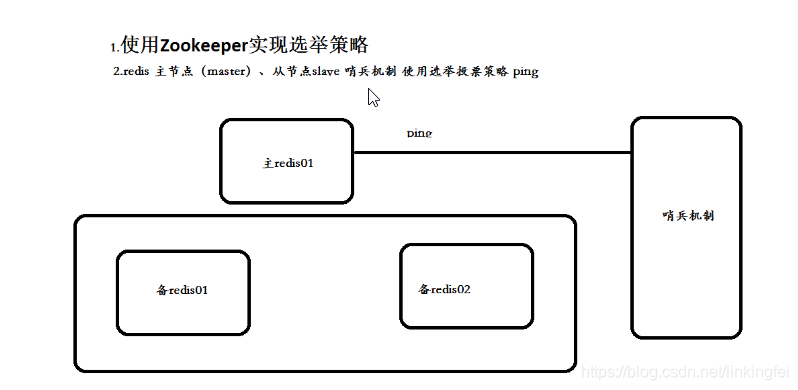
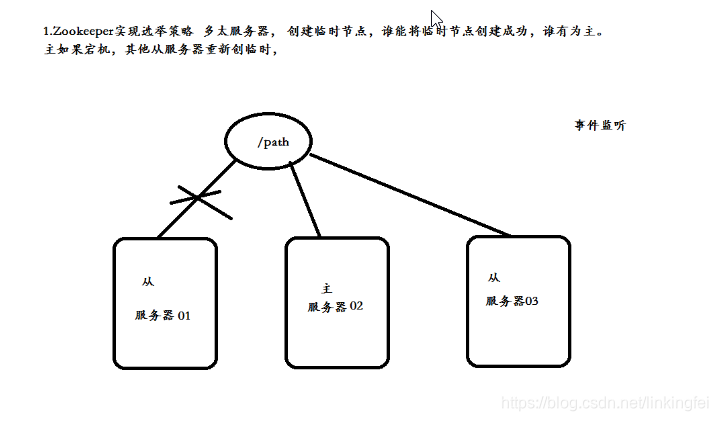
4、zk实现选举策略
有一个向外提供的服务,服务必须7*24小时提供服务,不能有单点故障。所以采用集群的方式,采用master、slave的结构。一台主机多台备机。主机向外提供服务,备机负责监听主机的状态,一旦主机宕机,备机要迅速接代主机继续向外提供服务。从备机选择一台作为主机,就是master选举。
- 多台服务器,创建临时节点,哪个创建成功哪个就为主
- 如果宕机,其他服务器重新创建临时节点
1、redis 选举策略
2、zk选举策略
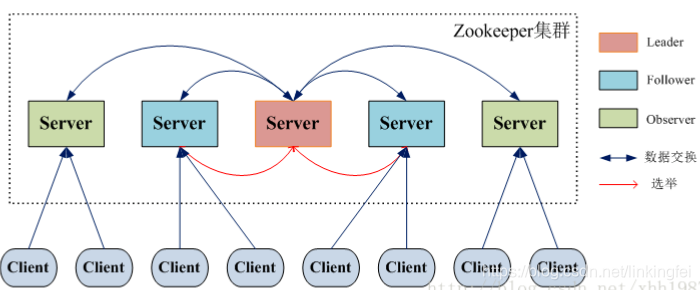
右边三台主机会尝试创建master节点,谁创建成功了,就是master,向外提供。其他两台就是slave。
所有slave必须关注master的删除事件(临时节点,如果服务器宕机了,Zookeeper会自动把master节点删除)。如果master宕机了,会进行新一轮的master选举。本次我们主要关注master选举,服务注册、发现先不讨论。
3、使用Zookeeper原理
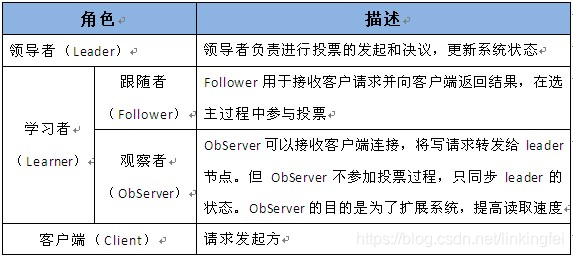
领导者(leader),负责进行投票的发起和决议,更新系统状态
学习者(learner),包括跟随者(follower)和观察者(observer),follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票
Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度
客户端(client),请求发起方
- Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。
实现这个机制的协议叫做Zab协 议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后 ,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。 - 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。
所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。 - 每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步