CNN网络实现手写数字(MNIST)识别 代码分析(自学用)
Github代码源文件
本文是学习了使用Pytorch框架的CNN网络实现手写数字(MNIST)识别
#导入需要的包
import numpy as np //第三方库,用于进行科学计算
import torch
from torch import nn
from PIL import Image // Python Image Library,python第三方图像处理库
import matplotlib.pyplot as plt //python的绘图库 pyplot:matplotlib的绘图框架
import os //提供了丰富的方法来处理文件和目录
from torchvision import datasets, transforms,utils //提供很多数据集的下载,包括COCO,ImageNet,CIFCAR等
1. 准备数据
(1)数据集介绍
MNIST数据集包含60000个训练集和10000测试数据集。分为图片和标签,图片是28*28的像素矩阵,标签为0~9共10个数字。
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])])
//Compos把多种数据处理的方法集合在一起
//使用transforms进行Tensor格式转换,将灰度范围从0-255变换到0-1之间
//批标准化(Batch Normalization),其作用就是先将输入归一化到(0,1),再使用公式"(x-mean)/std",将每个元素分布到(-1,1)
train_data = datasets.MNIST(root = "./data/"//root为数据集存放的路
transform=transform, //transform指定数据集导入的时候需要进行的变换
train = True, //train设置为true表明导入的是训练集合,否则是测试集合
download = True) //如果为true,请从互联网下载数据集,然后将其放在根目录中。 如果数据集已经下载,则不是再次下载。
test_data = datasets.MNIST(root="./data/",
transform = transform,
train = False)
//train_data 的个数:60000个训练样
//test_data 的个数:10000个训练样本
//一个样本的格式为[data,label],第一个存放数据,第二个存放标签
train_loader = torch.utils.data.DataLoader(train_data,batch_size=64,
shuffle=True,num_workers=2)
test_loader = torch.utils.data.DataLoader(test_data,batch_size=64,
shuffle=True,num_workers=2)
//设置batch_size表示每次训练的样本数量 ,加载器中的基本单位是一个batch的数据 ,这里是64
//所以train_loader 的长度是60000/64 = 938 个batch,test_loader 的长度是10000/64= 157 个batch
//shuffle 将序列的所有元素随机排序。
//num_workers 表示用多少个子进程加载数据
从二维数组生成一张图片
oneimg,label = train_data[0]
oneimg = oneimg.numpy().transpose(1,2,0) //numpy.transpose默认第一个方括号“[]”为 0轴 ,第二个方括号为 1轴...所以有着交换轴改变矩阵序列的作,(x=0,y=1,z=2),新的x是原来的y轴大小,新的y是原来的z轴大小,新的z是原来的x大小
std = [0.5] //标准差
mean = [0.5] //平均值
oneimg = oneimg * std + mean
oneimg.resize(28,28)
plt.imshow(oneimg)
plt.show()
从三维生成一张黑白图片
oneimg,label = train_data[0]
grid = utils.make_grid(oneimg) //make_grid的作用是将若干幅图像拼成一幅图像。在需要展示一批数据时很有用。
grid = grid.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
grid = grid * std + mean
plt.imshow(grid)
plt.show(
输出一个batch的图片和标签
images, lables = next(iter(train_loader))
//next()函数:不断返回迭代器下一个值
//iter()函数:把list,dict,str等可迭代的对象Iterable(可以用for循环的对象)转换为迭代器Iterator可以使用
img = utils.make_grid(images
img = img.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
img = img * std + mean
for i in range(64):
print(lables[i], end=" ")
i += 1
if i%8 is 0:
print(end='\n')
plt.imshow(img)
plt.show()
tensor(4) tensor(7) tensor(6) tensor(6) tensor(1) tensor(2) tensor(1) tensor(3)
tensor(2) tensor(9) tensor(6) tensor(2) tensor(5) tensor(0) tensor(7) tensor(1)
tensor(6) tensor(2) tensor(2) tensor(3) tensor(7) tensor(2) tensor(2) tensor(3)
tensor(4) tensor(6) tensor(3) tensor(3) tensor(8) tensor(3) tensor(6) tensor(6)
tensor(7) tensor(4) tensor(3) tensor(0) tensor(2) tensor(1) tensor(2) tensor(0)
tensor(3) tensor(9) tensor(2) tensor(2) tensor(4) tensor(5) tensor(7) tensor(0)
tensor(5) tensor(0) tensor(5) tensor(8) tensor(3) tensor(9) tensor(8) tensor(2)
tensor(7) tensor(5) tensor(8) tensor(2) tensor(6) tensor(8) tensor(9) tensor(1)
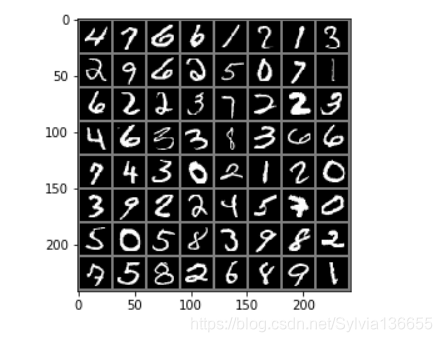
2.网络配置
网络结构是两个卷积层,3个全连接层。
Conv2d参数
- in_channels(int) – 输入信号的通道数目
- out_channels(int) – 卷积产生的通道数目
- kerner_size(int or tuple) - 卷积核的尺寸
- stride(int or tuple, optional) - 卷积步长
- padding(int or tuple, optional) - 输入的每一条边补充0的层数
1.定义一个CNN网络
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__() //首先找到CNN的父类(比如是类A),然后把类CNN的对象self转换为类A的对象,然后“被转换”的类A对象调用自己的__init__函数 (不理解)
self.conv1 = nn.Conv2d(1,32,kernel_size=3,stride=1,padding=1) //添加第一个卷积层,调用了nn里面的Conv2d(),输入的灰度图,所以 in_channels=1, out_channels=32 说明使用了32个滤波器/卷积核
self.pool = nn.MaxPool2d(2,2) //Max pooling over a (2, 2) window 即最大池化层
self.conv2 = nn.Conv2d(32,64,kernel_size=3,stride=1,padding=1) //2层, 输入通道in_channels 要等于上一层的 out_channels
//接着三个全连接层
self.fc1 = nn.Linear(64*7*7,1024//全连接层的输入特征维度为64*7*7,因为上一层Conv2d的out_channels=64,两个池化,所以是7*7而不是14*14(???)
self.fc2 = nn.Linear(1024,512)
self.fc3 = nn.Linear(512,10)
//in_features:每个输入(x)样本的特征的大小
//out_features:每个输出(y)样本的特征的大小
def forward(self,x): //这里定义前向传播的方法
x = self.pool(F.relu(self.conv1(x))) //F是torch.nn.functional的别名,F.relu()将ReLU层添加到网络。
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64 * 7* 7)//将特征图转换为一个1维的向量。第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。第一个全连接层的首参数是64*7*7,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = CNN() //类定义完之后实例化,我们这里就实例化了一个net
2.定义损失函数和优化函数
交叉熵的函数是这样的:
其中yi表示真实的分类结果

import torch.optim as optim
criterion = nn.CrossEntropyLoss() //交叉熵损失
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) //实现随机梯度下降算法,lr– 学习率,momentum– 动量因子
3.模型训练
train_accs = []
train_loss = []
test_accs = []
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
for epoch in range(3):
running_loss = 0.0
for i,data in enumerate(train_loader,0):#0是下标起始位置默认为0
// data 的格式[[inputs, labels]]
inputs,labels = data[0].to(device), data[1].to(device)
//初始为0,清除上个batch的梯度信息
optimizer.zero_grad()
//前向+后向+优化
outputs = net(inputs)
loss = criterion(outputs,labels)
loss.backward()
optimizer.step()
// loss 的输出,每个一百个batch输出,平均的loss
running_loss += loss.item()
if i%100 == 99:
print('[%d,%5d] loss :%.3f' %
(epoch+1,i+1,running_loss/100))
running_loss = 0.0
train_loss.append(loss.item())
//训练曲线的绘制 一个batch中的准确率
correct = 0
total = 0
_, predicted = torch.max(outputs.data, 1)
total = labels.size(0)// labels 的长度
correct = (predicted == labels).sum().item() // 预测正确的数目
train_accs.append(100*correct/total)
print('Finished Training')
[1, 100] loss :2.292
[1, 200] loss :2.261
[1, 300] loss :2.195
[1, 400] loss :1.984
[1, 500] loss :1.337
[1, 600] loss :0.765
[1, 700] loss :0.520
[1, 800] loss :0.427
[1, 900] loss :0.385
[2, 100] loss :0.339
[2, 200] loss :0.301
[2, 300] loss :0.290
[2, 400] loss :0.260
[2, 500] loss :0.250
[2, 600] loss :0.245
[2, 700] loss :0.226
[2, 800] loss :0.218
[2, 900] loss :0.206
[3, 100] loss :0.183
[3, 200] loss :0.176
[3, 300] loss :0.174
[3, 400] loss :0.156
[3, 500] loss :0.160
[3, 600] loss :0.147
[3, 700] loss :0.146
[3, 800] loss :0.130
[3, 900] loss :0.115
Finished Training
4.模型评估
画图
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("acc(\%)", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
train_iters = range(len(train_accs))
draw_train_process('training',train_iters,train_loss,train_accs,'training loss','training acc')
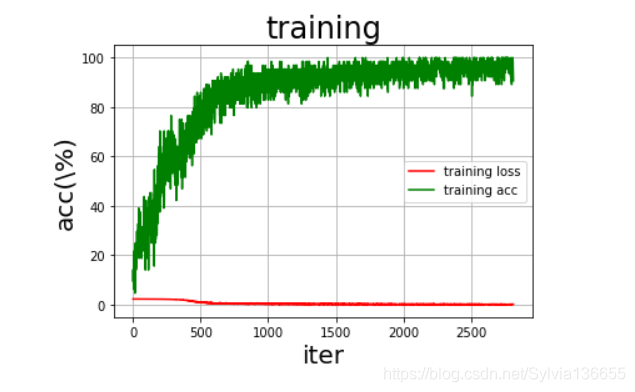
检验一个batch的分类情况
dataiter = iter(test_loader)
images, labels = dataiter.next()
# print images
test_img = utils.make_grid(images)
test_img = test_img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
test_img = test_img*std+0.5
plt.imshow(test_img)
plt.show()
print('GroundTruth: ', ' '.join('%d' % labels[j] for j in range(64)))

GroundTruth: 0 6 4 8 3 8 4 8 0 0 6 3 9 8 2 3 4 4 6 0 5 7 6 3 1 6 6 3 9 4 7 5 0 2 5 0 0 8 8 9 3 0 8 2 4 1 2 1 0 6 5 5 7 3 9 5 1 5 7 6 4 2 7 7
test_net = CNN()
test_net.load_state_dict(torch.load(PATH))
test_out = test_net(images)
输出的是每一类的对应概率,所以需要选择max来确定最终输出的类别
dim=1 表示选择行的最大索引
_, predicted = torch.max(test_out, dim=1)
print('Predicted: ', ' '.join('%d' % predicted[j]
for j in range(64)))
Predicted: 0 6 4 8 3 8 4 8 0 0 6 3 9 8 2 3 4 4 6 0 6 7 6 3 1 6 6 3 9 6 7 5 0 2 5 0 0 2 8 9 3 0 8 2 4 1 2 1 0 6 5 5 9 3 9 5 1 5 7 6 4 2 7 7
测试集上面整体的准确率
correct = 0
total = 0
with torch.no_grad()://进行评测的时候网络不更新梯度
for data in test_loader:
images, labels = data
outputs = test_net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)# labels 的长度
correct += (predicted == labels).sum().item() //预测正确的数目
print('Accuracy of the network on the test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the test images: 96 %
10个类别的准确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = test_net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels)
# print(predicted == labels)
for i in range(10):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %d : %2d %%' % (
i, 100 * class_correct[i] / class_total[i]))
Accuracy of 0 : 99 %
Accuracy of 1 : 98 %
Accuracy of 2 : 96 %
Accuracy of 3 : 91 %
Accuracy of 4 : 97 %
Accuracy of 5 : 95 %
Accuracy of 6 : 96 %
Accuracy of 7 : 93 %
Accuracy of 8 : 94 %
Accuracy of 9 : 92 %
版权声明:本文为Sylvia136655原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。