文章目录
零、本讲学习目标
一、搭建Spark单机版环境
(一)私有云上创建ied实例
(二)连接ied虚拟机
(三)修改ied实例主机名
(四)设置IP地址与主机名映射
(五)下载、安装和配置JDK
1、下载JDK压缩包
2、上传到ied虚拟机
3、将压缩包解压到指定目录
4、配置Java环境变量
(六)下载、安装与配置Spark
1、下载Spark安装包
2、将Spark安装包上传到ied虚拟机
3、将Spark安装包解压到指定目录
4、配置Spark环境变量
二、使用Spark单机版环境
(一)使用SparkPi来计算Pi的值
(二)使用Scala版本Spark-Shell
(三)使用Python版本Spark-Shell
(四)初步了解RDD
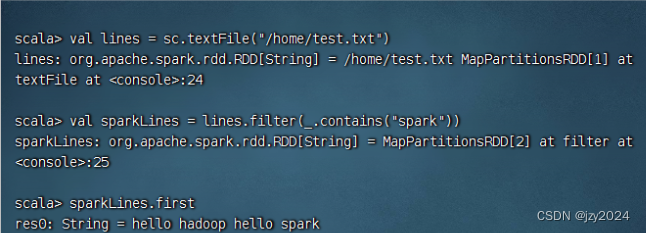
例1、创建一个RDD
例2、调用转化操作filter()
例3、调用行动操作first()
零、本讲学习目标
学会搭建Spark单机版环境
学会Spark应用程序的运行
学会启动Spark Shell
初步了解RDD的概念
一、搭建Spark单机版环境
(一)私有云上创建master实例(之前都创好了)
创建端口 - master_port
创建实例 - master
(二)连接master虚拟机
演示win7虚拟机通过FinalShell连接master虚拟机
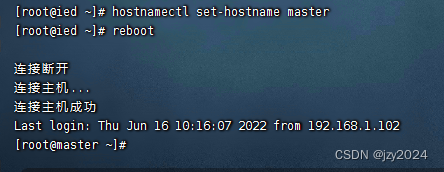
(三)修改ied实例主机名
执行命令:hostnamectl set-hostname master![[外链图片转存失败,源站可能有防盗在这里插入!链机制,建描述]议将图片上https://传(imblog.csdnimg.cn/d76g41z2e8chT64f0ca408e0ed4b93cfe.png1)https://imgblog.csdnimg.cn/d768a041c2e64f0ca408e0ed4b193cfe.png)]](https://img-blog.csdnimg.cn/91234b02000f45f796cb4e39553dc764.png)
重启虚拟机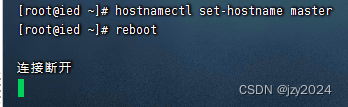
再次连接master虚拟机
(四)设置IP地址与主机名映射
执行命令:yum -y install vim,安装vim编辑器
执行命令:vim /etc/hosts
存盘退出,这样ping master就相当于ping 192.168.1.110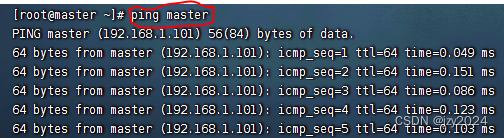
(五)下载、安装和配置JDK
1、下载JDK压缩包
下载链接:https://pan.baidu.com/s/1RcqHInNZjcV-TnxAMEtjzA 提取码:jivr
下载到win7虚拟机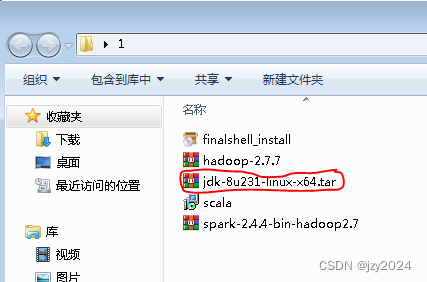
2、上传到ied虚拟机
将JDK压缩包上传到master虚拟机/opt目录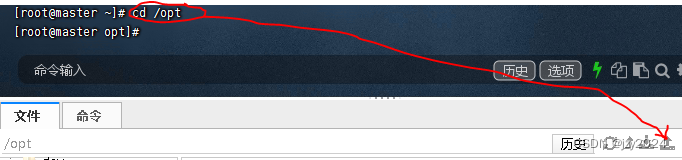
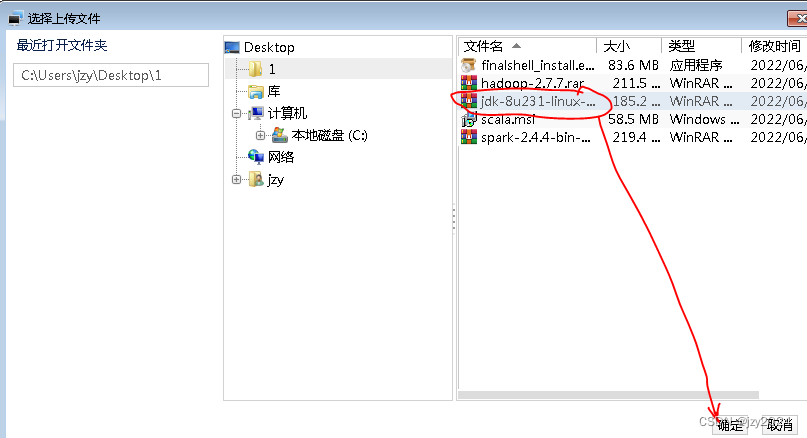
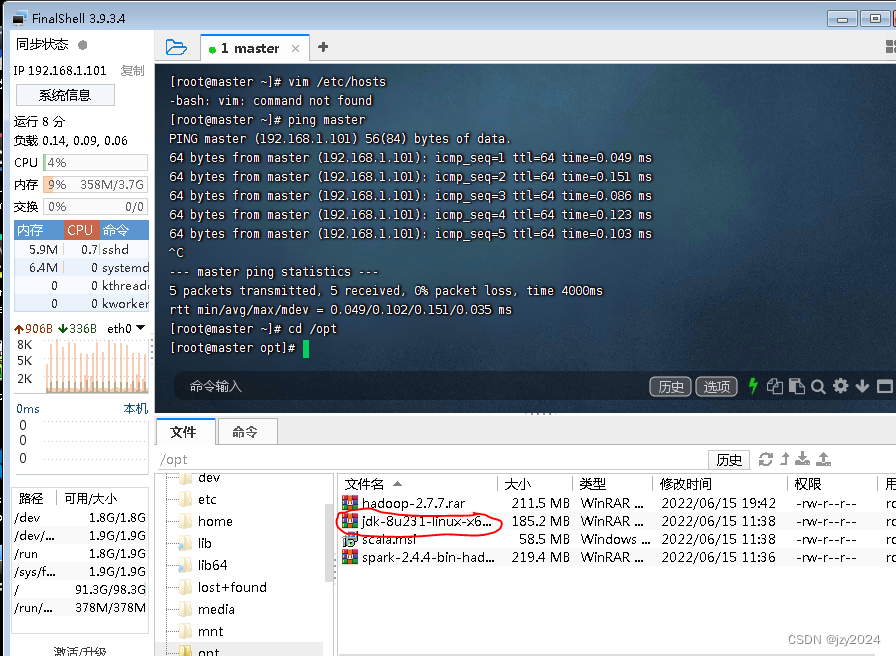
3、将压缩包解压到指定目录
执行命令:tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local
4、配置Java环境变量
执行命令:vim /etc/profile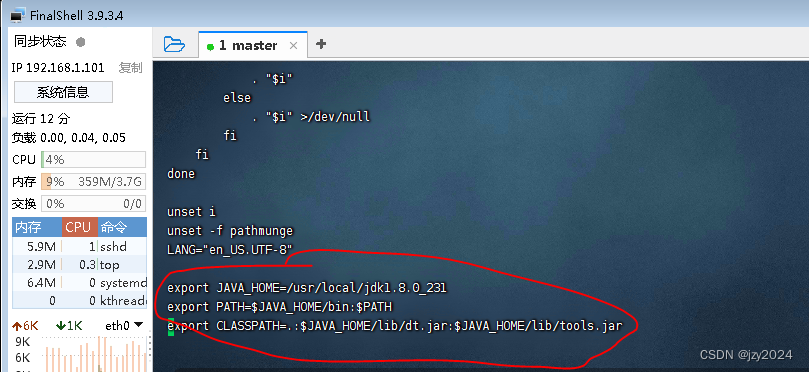
- export JAVA_HOME=/usr/local/jdk1.8.0_231
- export PATH=J A V A H O M E / b i n : JAVA_HOME/bin:JAVAHOME/bin:PATH export
- CLASSPATH=.:J A V A H O M E / l i b / d t . j a r : JAVA_HOME/lib/dt.jar:JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar
存盘退出,执行命令:source /etc/profile,让环境配置生效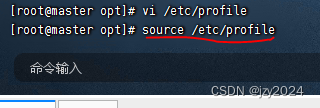
在任意目录下都可以查看JDK版本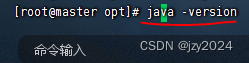
(六)下载、安装与配置Spark
1、下载Spark安装包
下载链接:https://pan.baidu.com/s/1dLKt5UJgpqehRNNDcoY2DQ 提取码:zh0x
2、将Spark安装包上传到master虚拟机
将Spark安装包上传到ied虚拟机/opt目录(跟之前上传jdk包一样)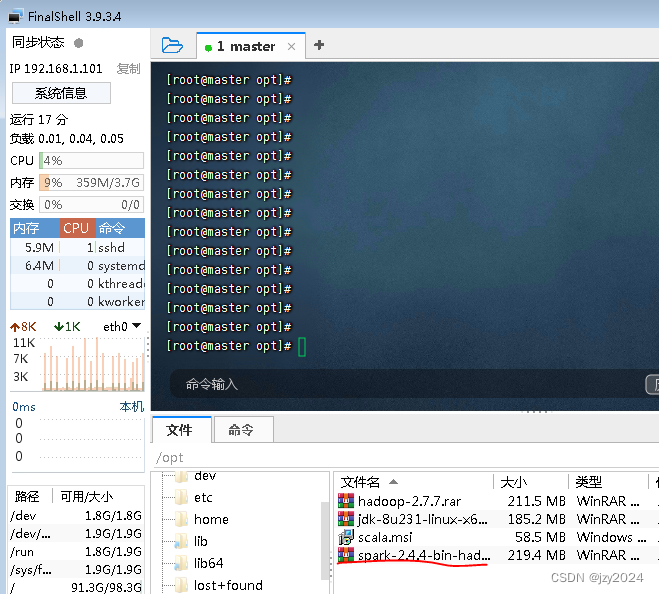
3、将Spark安装包解压到指定目录
执行命令:tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local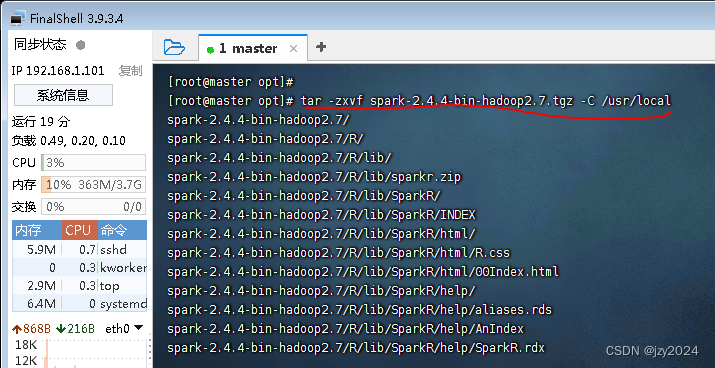
查看解压之后的spark目录ll /usr/local/spark-2.4.4-bin-hadoop2.7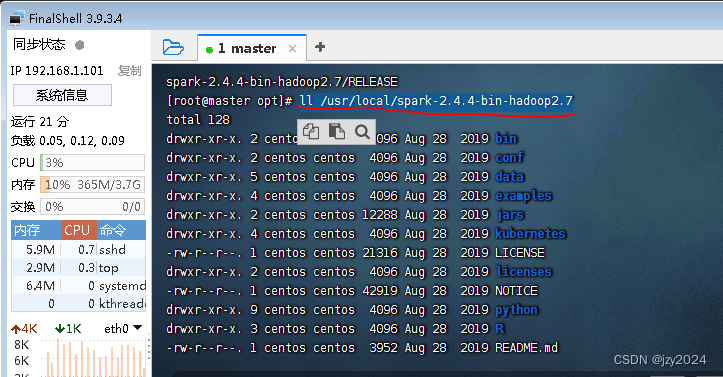
4、配置Spark环境变量
执行vim /etc/profile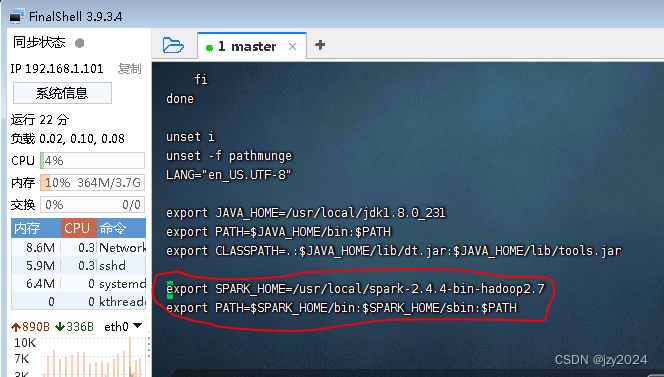
- export SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
- export PATH=S P A R K H O M E / b i n : SPARK_HOME/bin:SPARKHOME/bin:SPARK_HOME/sbin:$PATH
存盘退出,执行命令:source /etc/profile,让环境配置生效
二、使用Spark单机版环境
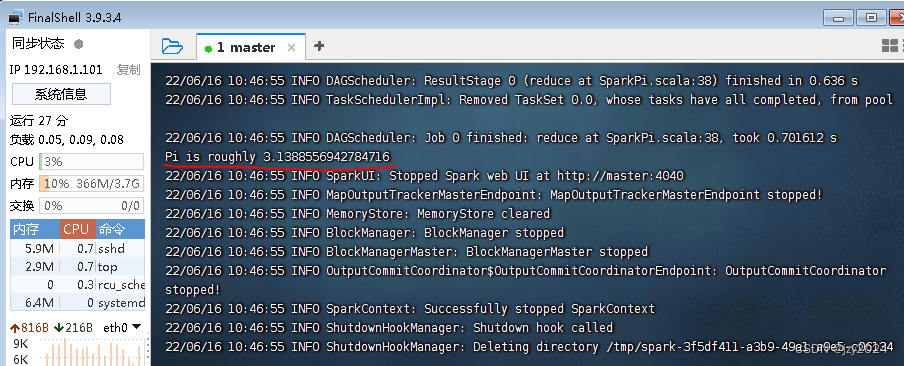
(一)使用SparkPi来计算Pi的值
执行命令:run-example SparkPi 2 (其中参数2是指两个并行度)
(二)使用Scala版本Spark-Shell
执行 spark-shell 命令启动Scala版的Spark-Shell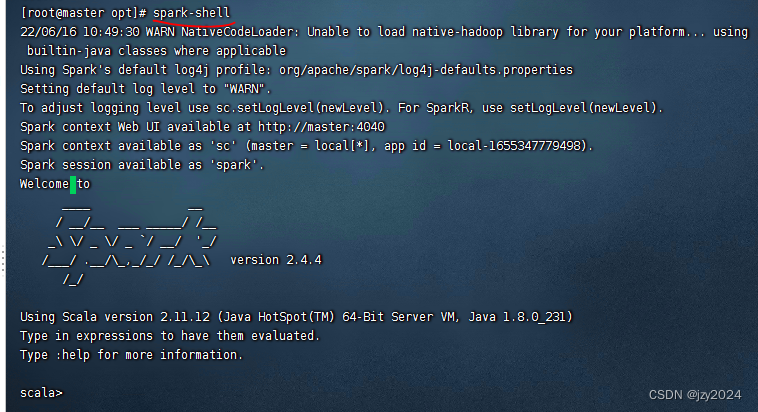
利用print函数输出了一条信息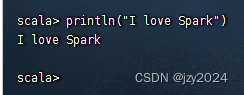
计算1 + 2 + 3 + …… + 100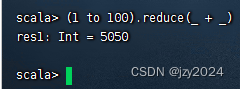
输出字符直角三角形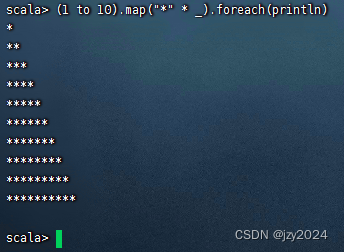
打印九九表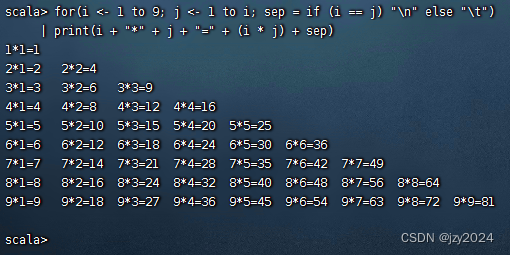
(三)使用Python版本Spark-Shell
执行 pyspark 命令启动Python版的Spark-Shell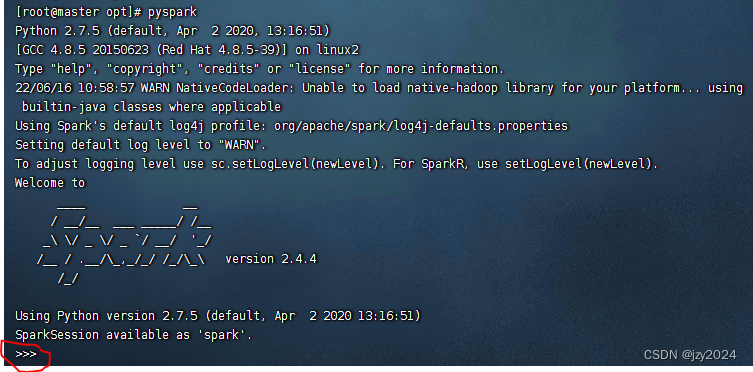
输出一条信息,进行加法运算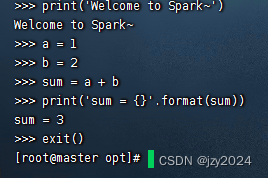
(四)初步了解RDD
Spark 中的RDD (Resilient Distributed Dataset) 就是一个不可变的分布式对象集合。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list 和set)。
在/home目录下创建test.txt文件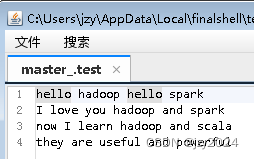
例1、创建一个RDD
在pyspark命令行,执行命令:lines = sc.textFile(‘test.txt’)
创建出来后,RDD 支持两种类型的操作: 转化操作(transformation) 和行动操作(action)。转化操作会由一个RDD 生成一个新的RDD。另一方面,行动操作会对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中。
例2、调用转化操作filter()
执行命令:sparkLines = lines.filter(lambda line: ‘spark’ in line)
例3、调用行动操作first()
执行命令:sparkLines.first()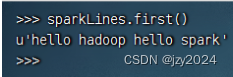
转化操作和行动操作的区别在于Spark 计算RDD 的方式不同。虽然你可以在任何时候定义新的RDD,但Spark 只会惰性计算这些RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。这种策略刚开始看起来可能会显得有些奇怪,不过在大数据领域是很有道理的。比如,看看例2 和例3,我们以一个文本文件定义了数据,然后把其中包含spark的行筛选出来。如果Spark 在我们运行lines = sc.textFile(…) 时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反, 一旦Spark 了解了完整的转化操作链之后,它就可以只计算求结果时真正需要的数据。事实上,在行动操作first() 中,Spark 只需要扫描文件直到找到第一个匹配的行为止,而不需要读取整个文件。
同样的操作,在Scala的Spark Shell里完成