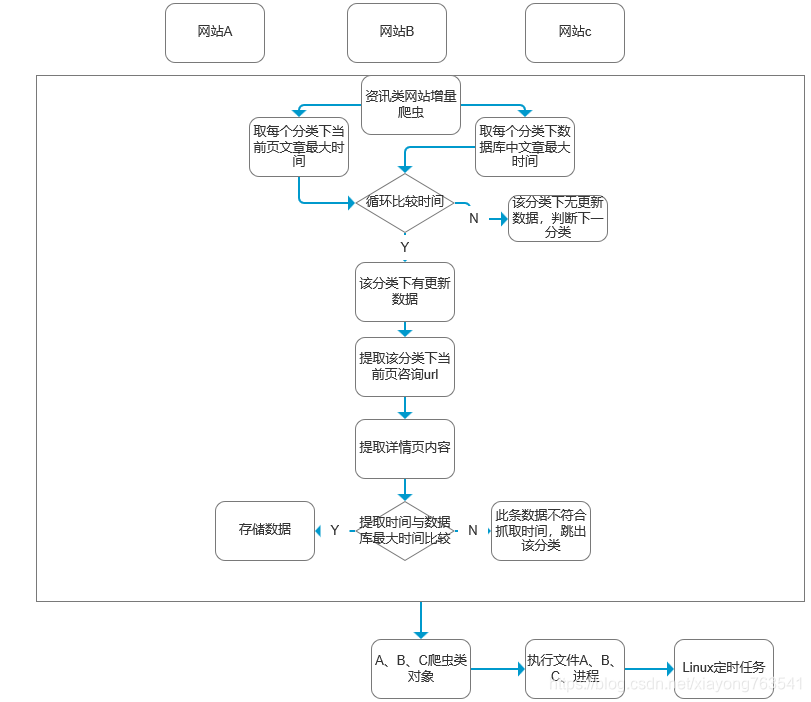
一:网站增量式爬虫流程图
1)前提是A、B、C网站分类下历史数据已经爬取过
2)A、B、C网站下的同一网站下分类数据存储的表名有规律
二:代码实现
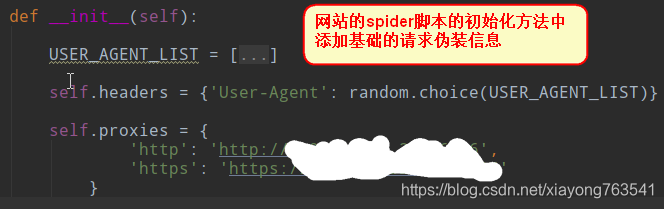
1)init初始化方法中添加基本的请求伪装信息
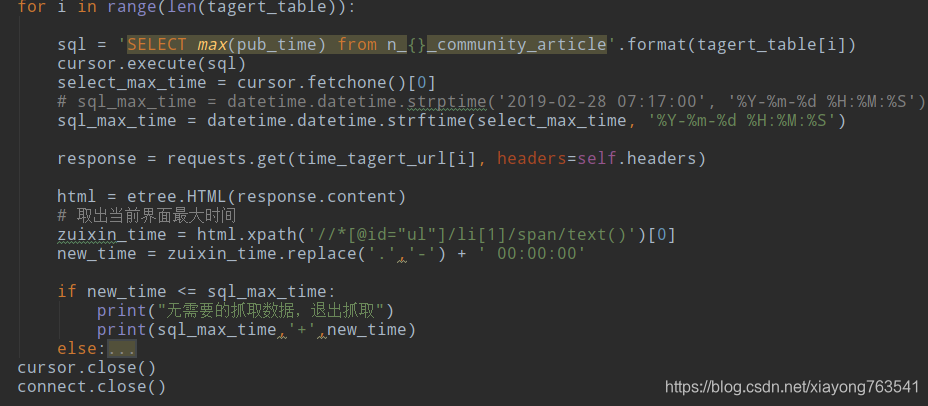
2)抓取方法

1、第一层循环判断分类下是否有数据更新
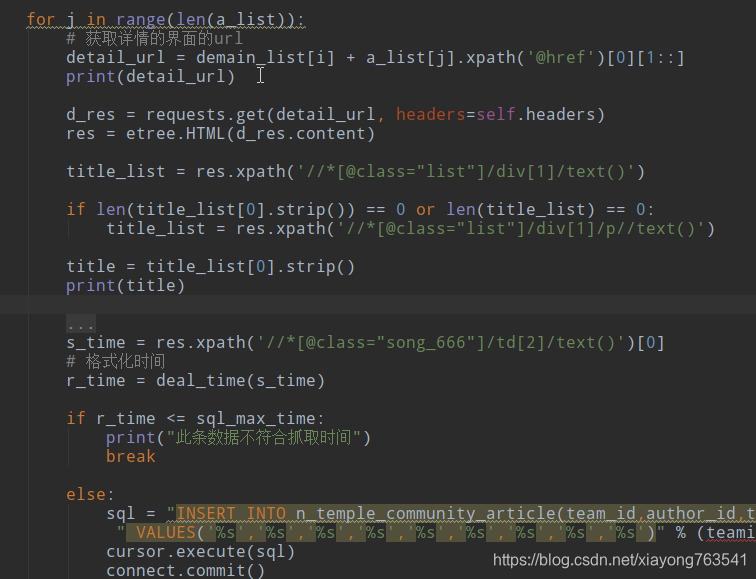
2、第二层循环判断分类下列表中数据是否都符合抓取时间,遇到不符合抓取的跳出该分类
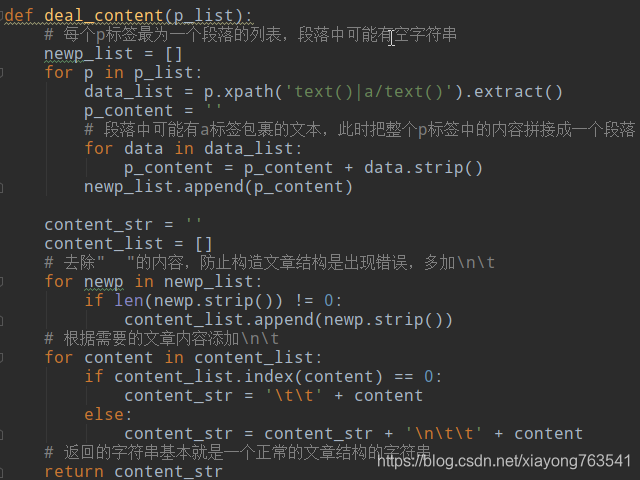
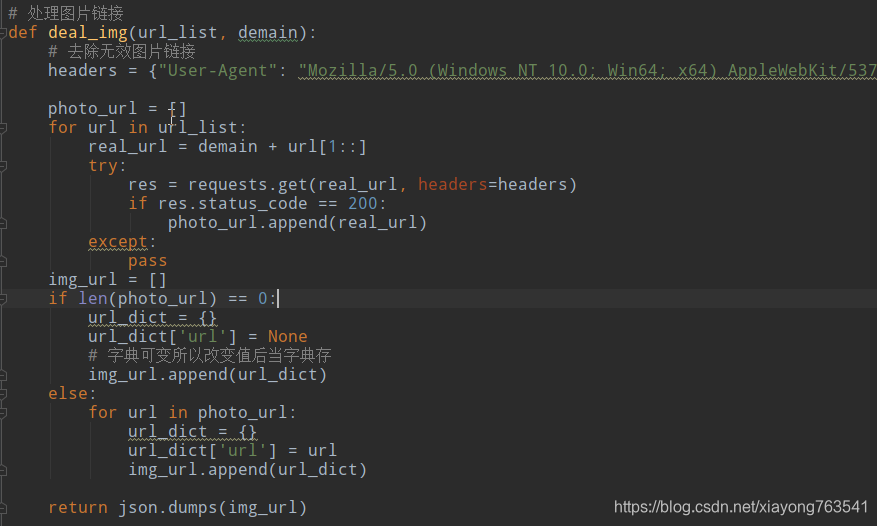
3)文章的结构构建与img_url生成json字符串的处理
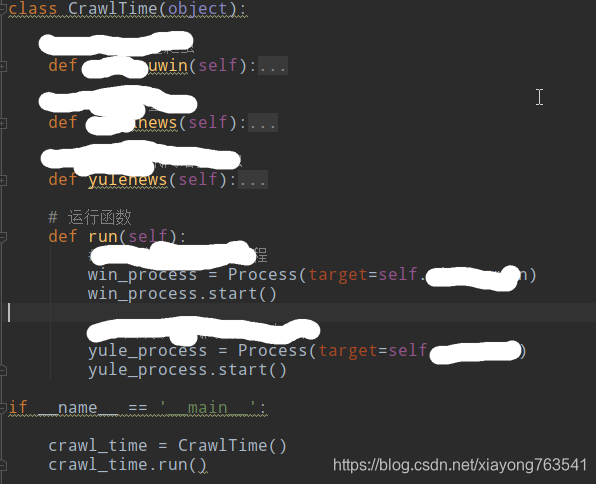
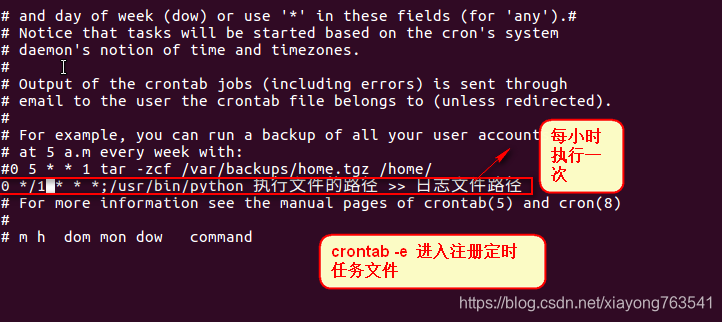
三:多网站的多进程Linux环境下定时任务执行
版权声明:本文为xiayong763541原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。