Hive中的Join可分为两种情况
Common Join(Reduce阶段完成join)
Map Join(Map阶段完成join)
Common Join
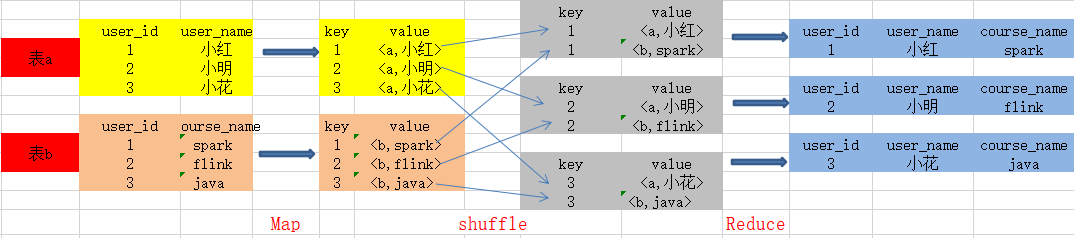
如果没开启hive.auto.convert.join=true或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join,在Reduce阶段完成join。并且整个过程包含Map、Shuffle、Reduce阶段。1 Map阶段 读取表的数据,Map输出时候以 Join on 条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的 value 为 join 之后需要输出或者作为条件的列;同时在value中还会包含表的 Tag 信息,用于标明此value对应的表;按照key进行排序
根据key取哈希值,并将key/value按照哈希值分发到不同的reduce中
3 Reduce阶段根据key的值完成join操作,并且通过Tag来识别不同表中的数据。在合并过程中,把表编号扔掉
4 举例 drop table if exists wedw_dwd.user_info_df; CREATE TABLE wedw_dwd.user_info_df( user_id string COMMENT '用户id', user_name string COMMENT '用户姓名' )row format delimited fields terminated by '\t' STORED AS textfile ; +----------+------------+--+| user_id | user_name |+----------+------------+--+| 1 | 小红 || 2 | 小明 || 3 | 小花 |+----------+------------+--+ drop table if exists wedw_dwd.order_info_df; CREATE TABLE wedw_dwd.order_info_df( user_id string COMMENT '用户id', course_name string COMMENT '课程名称' )row format delimited fields terminated by '\t' STORED AS textfile ; +----------+--------------+--+| user_id | course_name |+----------+--------------+--+| 1 | spark || 2 | flink || 3 | java |+----------+--------------+--+select t1.user_id,t1.user_name,t2.course_namefromwedw_dwd.user_info_df t1join wedw_dwd.order_info_df t2on t1.user_id = t2.user_id;+----------+------------+--------------+--+| user_id | user_name | course_name |+----------+------------+--------------+--+| 1 | 小红 | spark || 2 | 小明 | flink || 3 | 小花 | java |+----------+------------+--------------+--+图解:(在合并过程中,把表编号扔掉)
Map Join
大表join小表,独钟爱mapjoin
版权声明:本文为weixin_39609620原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。