一.概念
- Docker是一个开源的应用容器引擎,开发者可以打包他们的应用及依赖到一个可移植的容器中,发布到流行的Linux机器上,也可实现虚拟化。
- k8s是一个开源的容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
- 可以根据以下网址进行学习
https://kubernetes.io/zh/docs/setup/independent/install-kubeadm/ - kubeadm 是 Kubernetes 官 方 推 出 的 快 速 部 署 Kubernetes 集 群 工 具 , 其 思 路 是 将 Kubernetes 相关服务容器化(Kubernetes 静态 Pod)以简化部署。
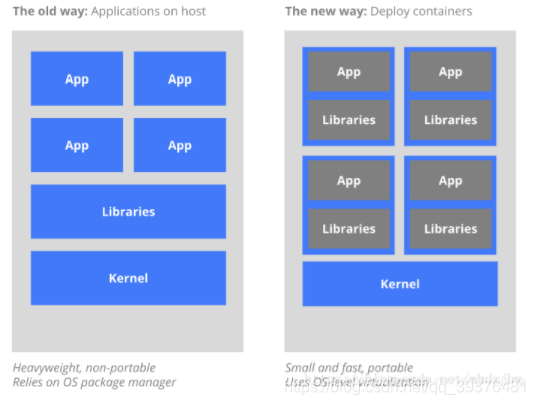
- 从虚拟化角度看(说明了为应用提供必要的运行环境所需要做的虚拟化操作(即:传统:虚拟出的虚拟机装操作系统、Docker:容器引擎管理下的容器)。),下图是Docker容器(可用k8s管理的玩意儿)与传统虚拟化方式的不同之处,传统的虚拟技术,在将物理硬件虚拟成多套硬件后,需要再每套硬件上都部署一个操作系统,接着在这些操作系统上运行相应的应用程序。而Docker容器内的应用程序进程直接运行在宿主机(真实物理机)的内核上,Docker引擎将一些各自独立的应用程序和它们各自的依赖打包,相互独立直接运行于未经虚拟化的宿主机硬件上,同时各个容器也没有自己的内核,显然比传统虚拟机更轻便。 每个集群有多个节点,每个节点可,我们的kuberbete就是管理这些应用程序所在的小运行环境(container)而生。

- 从部署角度看,在这些具体运行环境上进行真实应用部署时的情况,传统方式是将所有应用直接部署在同一个物理机器节点上,这样每个App的依赖都是完全相同的,无法做到App之间隔离,当然,为了隔离,我们也可以通过创建虚拟机的方式来将App部署到其中(就像图1上半部分那样),但这样太过繁重,故比虚拟机更轻便的Docker技术出现,现在我们通过部署Container容器的技术来部署应用,全部Container运行在容器引擎上即可。既然嫌弃虚拟机繁重,想用Docker,那好,你用吧,怎么用呢?手动一个一个创建?当然不,故kubernetes技术便出现了,以kubernetes为代表的容器集群管理系统,这时候就该上场表演了。 说白了,我们用kubernetes去管理Docker集群,即可以将Docker看成Kubernetes内部使用的低级别组件。另外,kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术。希望我这篇文章中简单的描述能让你对两者有所理解和认识。
二.K8s管理Docker集群
实验环境:
~~~~~~~~~~~~~~~~~~~~~~~
虚拟机环境:RHEL7.3 selinux and iptables disabled
172.25.66.1 server1 master
172.25.66.2 server2 node
172.25.66.3 server3 node
~~~~~~~~~~~~~~~~~~~~~~~
前提:
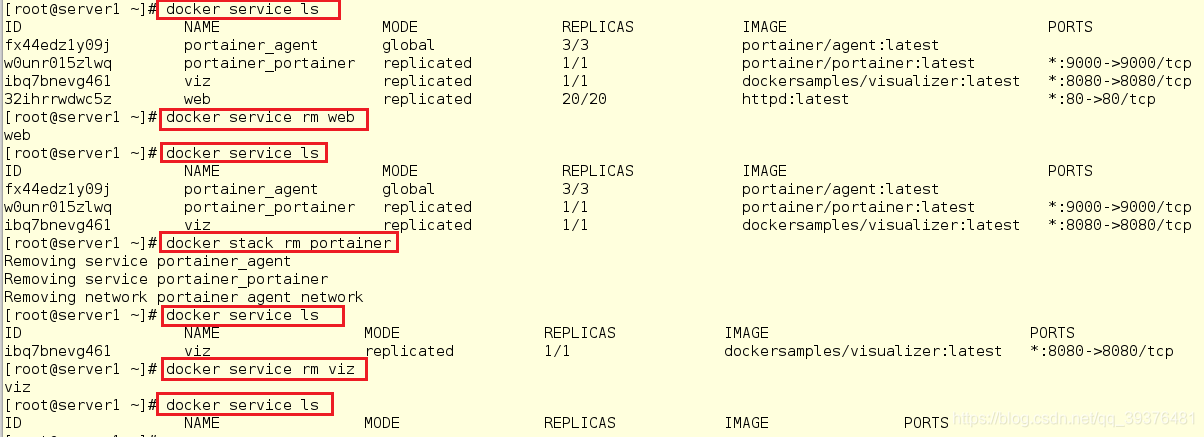
清理环境(因为在各个节点上的步骤是一样的,所以这里只显示清除server1的步骤)
清除列表管理
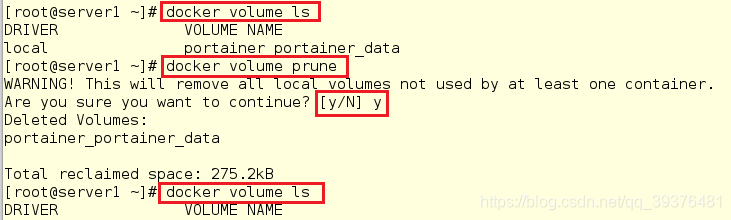
清除卷
删除容器

删除网络

各个节点离开swarm集群
[root@server1 ~]# docker swarm leave -f
[root@server2 ~]# docker swarm leave -f
[root@server3 ~]# docker swarm leave -f

注意:
这里节点离开swarm集群是强制性离开的,因为其不强制离开会出现报错,而报错的原因为是因为工作节点还在管理节点上,所以无法离开,正确的使用如下:
禁用swap分区
[root@server1 ~]# swapon -s
[root@server1 ~]# swapoff -a
[root@server1 ~]# swapon -s

[root@server1 ~]# vim /etc/fstab


实验:
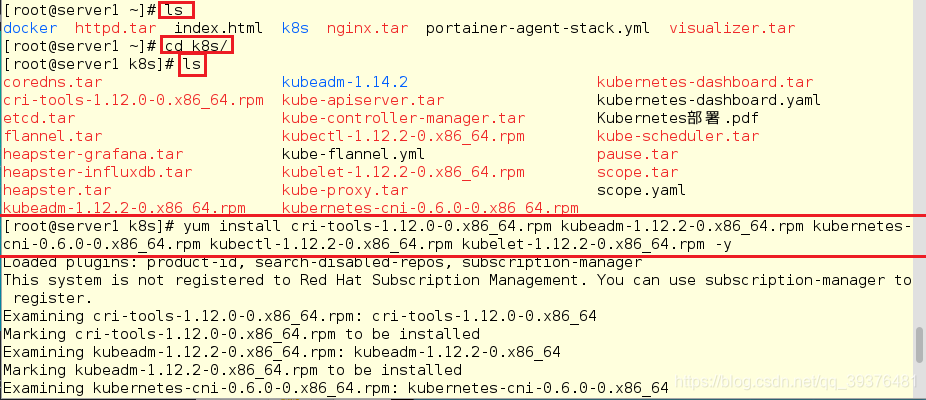
1.在server1,server2,server3安装相应的软件
需要在每台机器上都安装以下的软件包:
kubeadm: 用来初始化集群的指令。
kubelet: 在集群中的每个节点上用来启动 pod 和 container 等。
kubectl: 用来与集群通信的命令行工具。
kubeadm 不能 帮您安装或管理 kubelet 或 kubectl ,所以您得保证他们满足通过 kubeadm 安装的 Kubernetes 控制层对版本的要求。如果版本没有满足要求,就有可能导致一些难以想到的错误或问题。然而控制层与 kubelet 间的 小版本号 不一致无伤大雅,不过请记住 kubelet 的版本不可以超过 API server 的版本。例如 1.8.0 的 API server 可以适配 1.7.0 的 kubelet,反之就不行了
server1[root@server1 ~]# ls [root@server1 ~]# cd k8s/ [root@server1 k8s]# ls [root@server1 k8s]# yum install cri-tools-1.12.0-0.x86_64.rpm kubeadm-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm -y [root@server1 k8s]# scp cri-tools-1.12.0-0.x86_64.rpm kubeadm-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm server2: [root@server1 k8s]# scp cri-tools-1.12.0-0.x86_64.rpm kubeadm-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm server3:


server2
[root@server2 ~]# yum install cri-tools-1.12.0-0.x86_64.rpm kubeadm-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm -y
server3
[root@server3 ~]# yum install cri-tools-1.12.0-0.x86_64.rpm kubeadm-1.12.2-0.x86_64.rpm kubernetes-cni-0.6.0-0.x86_64.rpm kubectl-1.12.2-0.x86_64.rpm kubelet-1.12.2-0.x86_64.rpm -y
2.在server1,server2,server3设置服务为自启动
[root@server1 ~]# systemctl enable kubelet.service && systemctl enable docker.service
[root@server2 ~]# systemctl enable kubelet.service && systemctl enable docker.service
[root@server3 ~]# systemctl enable kubelet.service && systemctl enable docker.service



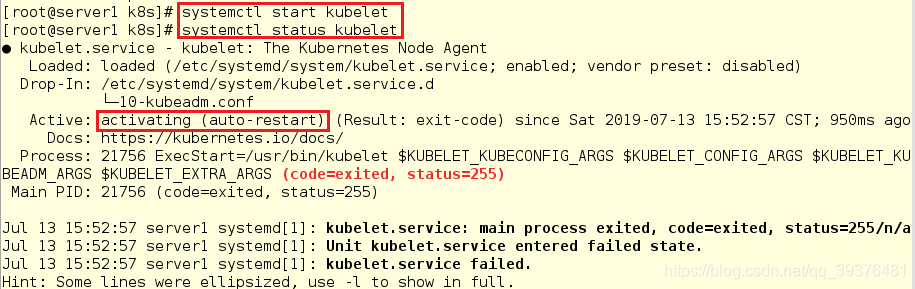
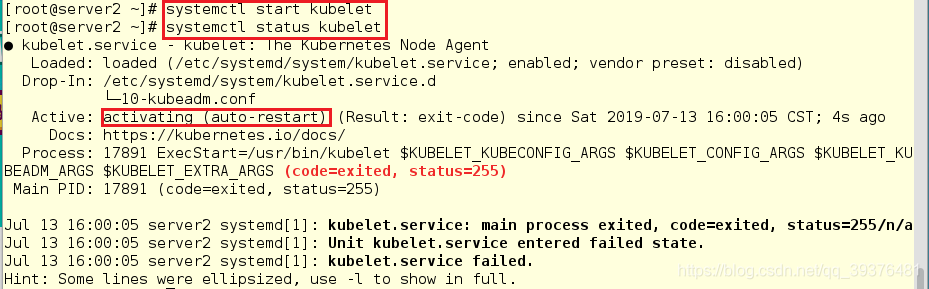
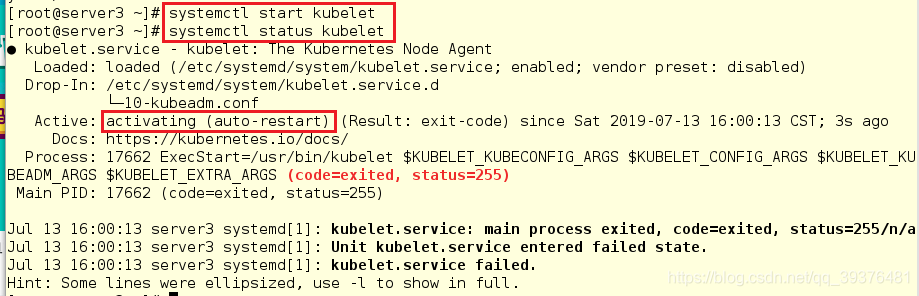
3.在server1,server2,server3开启kubelet服务,尽管察看其状态时,显示的是未开启,但是依旧需要开启
[root@server1 k8s]# systemctl start kubelet
[root@server1 k8s]# systemctl status kubelet
[root@server2 ~]# systemctl start kubelet
[root@server2 ~]# systemctl status kubelet
[root@server3 ~]# systemctl start kubelet
[root@server3 ~]# systemctl status kubelet
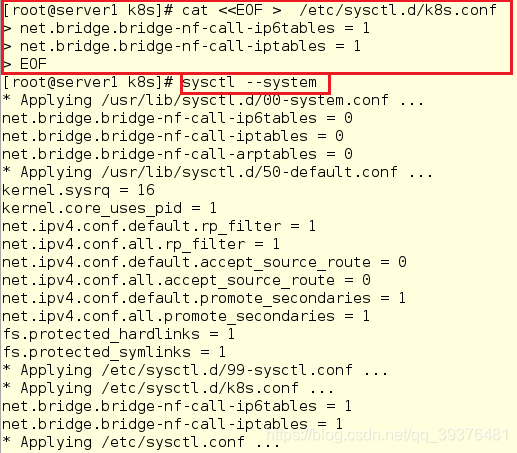
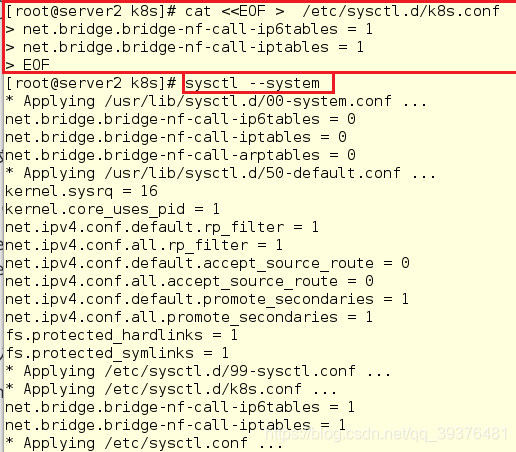
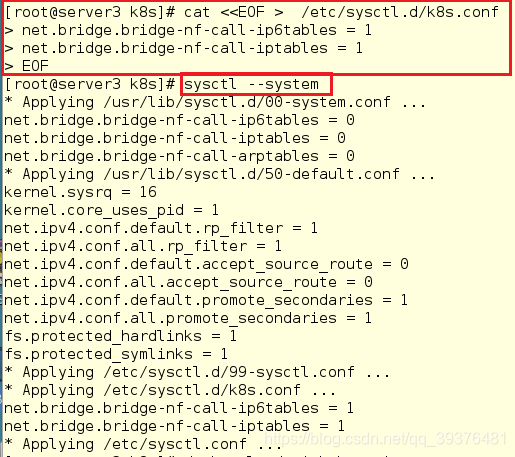
4.在所有节点的/etc/sysctl.d/k8s.conf内写入内容并查看
[root@server1 k8s]# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@server1 k8s]# sysctl --system
[root@server2 k8s]# cat <<EOF > /etc/sysctl.d/k8s.conf
> net.bridge.bridge-nf-call-ip6tables = 1
> net.bridge.bridge-nf-call-iptables = 1
> EOF
[root@server2 k8s]# sysctl --system
[root@server3 k8s]# cat <<EOF > /etc/sysctl.d/k8s.conf
> net.bridge.bridge-nf-call-ip6tables = 1
> net.bridge.bridge-nf-call-iptables = 1
> EOF
[root@server3 k8s]# sysctl --system
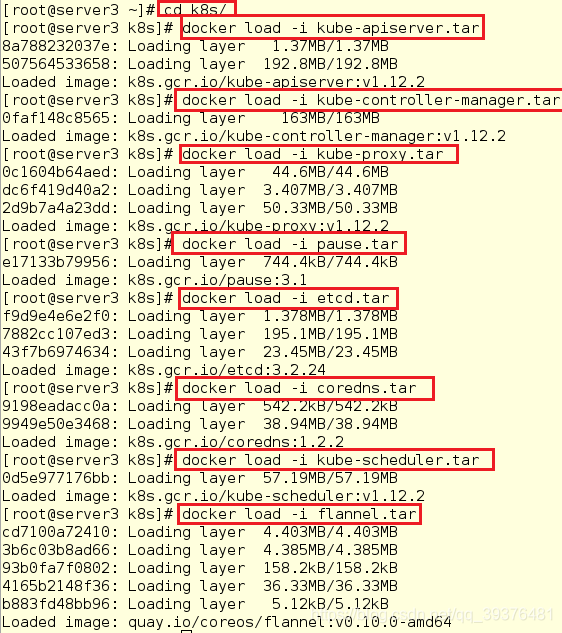
5.查看kubeadm会用到的镜像并将其一一导入(不然init时会从外网下载,但需要翻墙)
[root@server1 k8s]# kubeadm config images list
[root@server1 k8s]# docker load -i kube-apiserver.tar
[root@server1 k8s]# docker load -i kube-controller-manager.tar
[root@server1 k8s]# docker load -i kube-proxy.tar
[root@server1 k8s]# docker load -i pause.tar
[root@server1 k8s]# docker load -i etcd.tar
[root@server1 k8s]# docker load -i coredns.tar
[root@server1 k8s]# docker load -i kube-scheduler.tar
[root@server1 k8s]# docker load -i flannel.tar

6.在server2和server3中导入应该导入的镜像(和server1一样)
server2
[root@server2 ~]# cd k8s/
[root@server2 k8s]# docker load -i kube-apiserver.tar
[root@server2 k8s]# docker load -i kube-controller-
[root@server2 k8s]# docker load -i kube-proxy.tar
[root@server2 k8s]# docker load -i pause.tar
[root@server2 k8s]# docker load -i etcd.tar
[root@server2 k8s]# docker load -i coredns.tar
[root@server2 k8s]# docker load -i kube-scheduler.tar
[root@server2 k8s]# docker load -i flannel.tar

server3:
[root@server3 ~]# cd k8s/
[root@server3 k8s]# docker load -i kube-apiserver.tar
[root@server3 k8s]# docker load -i kube-controller-
[root@server3 k8s]# docker load -i kube-proxy.tar
[root@server3 k8s]# docker load -i pause.tar
[root@server3 k8s]# docker load -i etcd.tar
[root@server3 k8s]# docker load -i coredns.tar
[root@server3 k8s]# docker load -i kube-scheduler.tar
[root@server3 k8s]# docker load -i flannel.tar
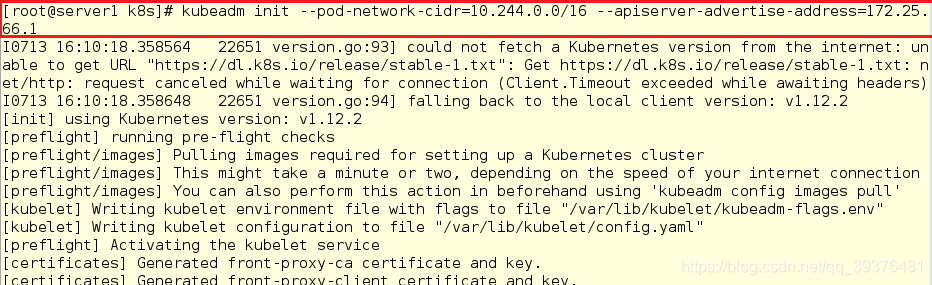
7.在server1(master节点)上初始化
[root@server1 k8s]# kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=172.25.66.1
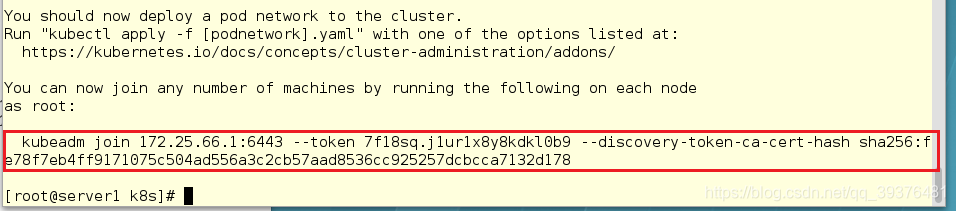
注意:
1.如果第一次初始化集群失败,需要执行命令"kubeadm reset"进行重置,重置之后再执行初始化集群的命令,进行集群初始化。
2.一定要将此内容复制下kubeadm join 172.25.66.1:6443 --token 7f18sq.j1ur1x8y8kdkl0b9 --discovery-token-ca-cert-hash sha256:fe78f7eb4ff9171075c504ad556a3c2cb57aad8536cc925257dcbcca7132d178
3.选 择flannel作 为Pod网 络 插 件 , init时 需 要 指 定 参 数 :
–pod-network-cidr=10.244.0.0/16
8.在server1中创建一个用户并在/etc/sudoers文件内写入内容,给予用户赋予所有的权限
[root@server1 k8s]# useradd kubeadm
[root@server1 k8s]# vim /etc/sudoers
[root@server1 k8s]# tail -n 1 /etc/sudoers
文件中增加的内容如下:
kubeadm ALL=(ALL) NOPASSWD: ALL


9.切换到kubeadm用户下创建文件并将其复制(根据上一部初始化集群的结果)提示信息进行操作
[root@server1 k8s]# su - kubeadm
[kubeadm@server1 ~]$ mkdir -p $HOME/.kube
[kubeadm@server1 ~]$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[kubeadm@server1 ~]$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
[kubeadm@server1 ~]$ exit

10.在server1上配置 kubectl 命令补齐功能:
[root@server1 k8s]# su - kubeadm
[kubeadm@server1 ~]$ echo "source <(kubectl completion bash)" >> ./.bashr
[kubeadm@server1 ~]$ logout

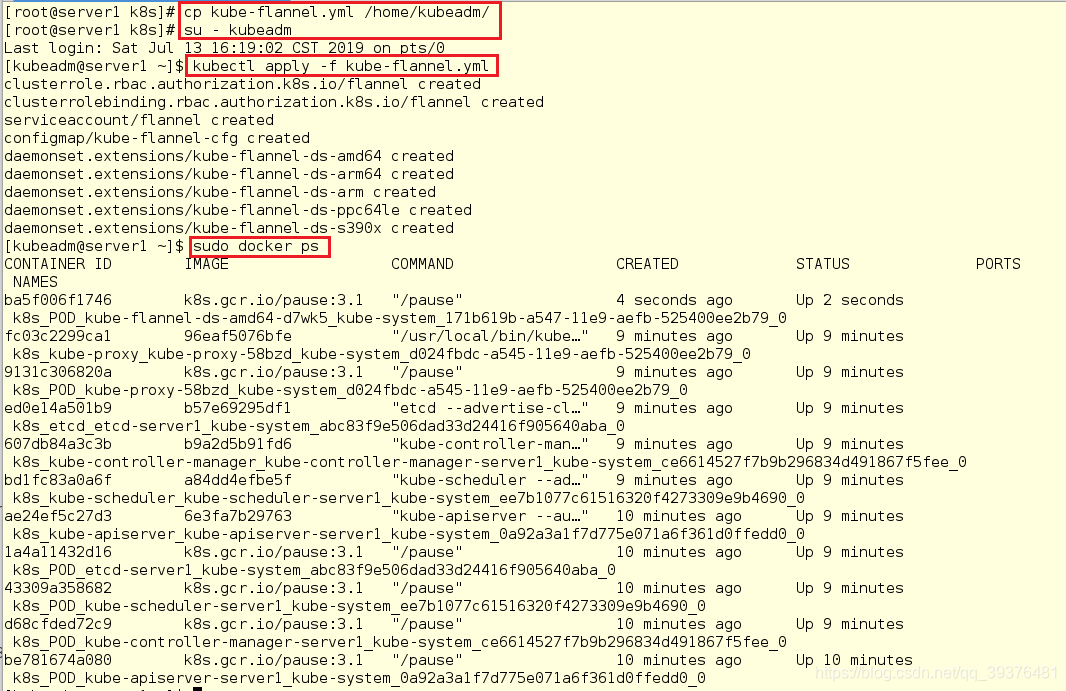
11.在server1上将kube-flannel.yml文件发送到/home/k8s目录下。因为kube-flannel.yml文件原来的/root/k8s目录下,普通用户k8s无法访问
[root@server1 k8s]# cp kube-flannel.yml /home/kubeadm/
[root@server1 k8s]# su - kubeadm
#安装 pod 网络:
[kubeadm@server1 ~]$ kubectl apply -f kube-flannel.yml
[kubeadm@server1 ~]$ sudo docker ps
12.在server2和server3上加载ipvs内核模块并使其临时生效
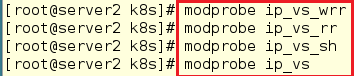
server2:
[root@server2 k8s]# modprobe ip_vs_wrr
[root@server2 k8s]# modprobe ip_vs_rr
[root@server2 k8s]# modprobe ip_vs_sh
[root@server2 k8s]# modprobe ip_vs
server3:
[root@server3 k8s]# modprobe ip_vs_wrr
[root@server3 k8s]# modprobe ip_vs_rr
[root@server3 k8s]# modprobe ip_vs_sh
[root@server3 k8s]# modprobe ip_vs

注意:
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
13.在server2和server3中加入集群
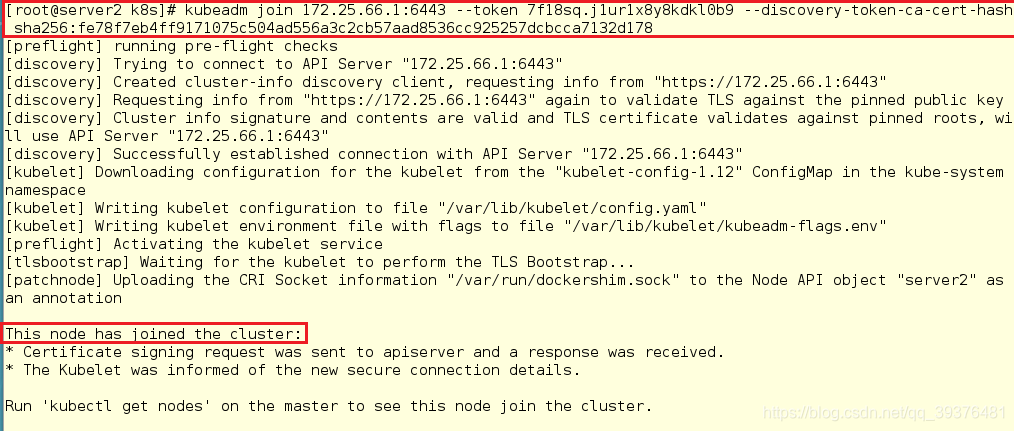
server2
[root@server2 k8s]# kubeadm join 172.25.66.1:6443 --token 7f18sq.j1ur1x8y8kdkl0b9 --discovery-token-ca-cert-hash sha256:fe78f7eb4ff9171075c504ad556a3c2cb57aad8536cc925257dcbcca7132d178
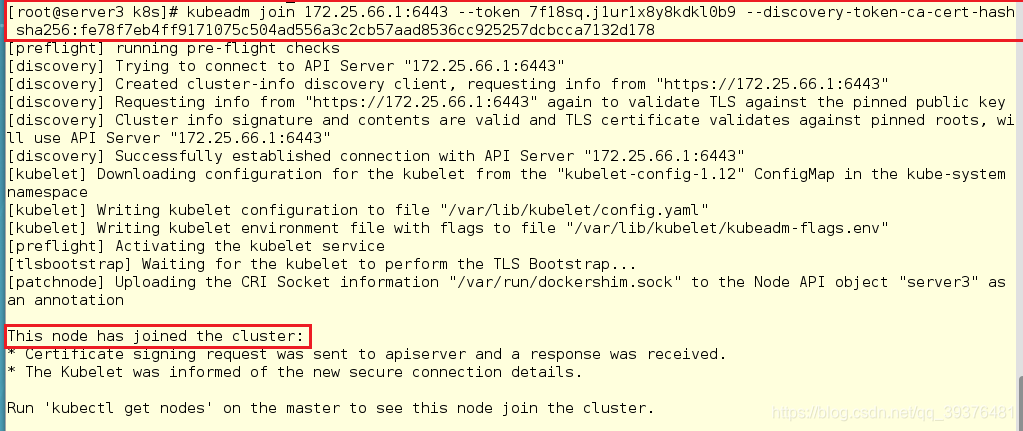
server3
[root@server3 k8s]# kubeadm join 172.25.66.1:6443 --token 7f18sq.j1ur1x8y8kdkl0b9 --discovery-token-ca-cert-hash sha256:fe78f7eb4ff9171075c504ad556a3c2cb57aad8536cc925257dcbcca7132d178
14.获取默认namespace(default)下的pod,查看所有节点的状态是否都是ready(如果先开始不是,稍等一下就好了)
[kubeadm@server1 ~]$ kubectl get nodes

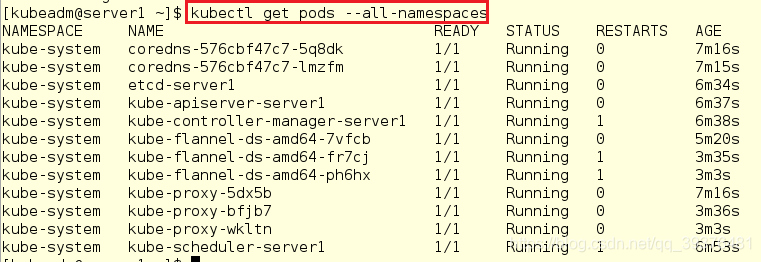
15.获取所有namespace下的pod,查看是否所有的pod的状态都是running
[kubeadm@server1 ~]$ kubectl get pods --all-namespaces
16.在master节点上查看状态
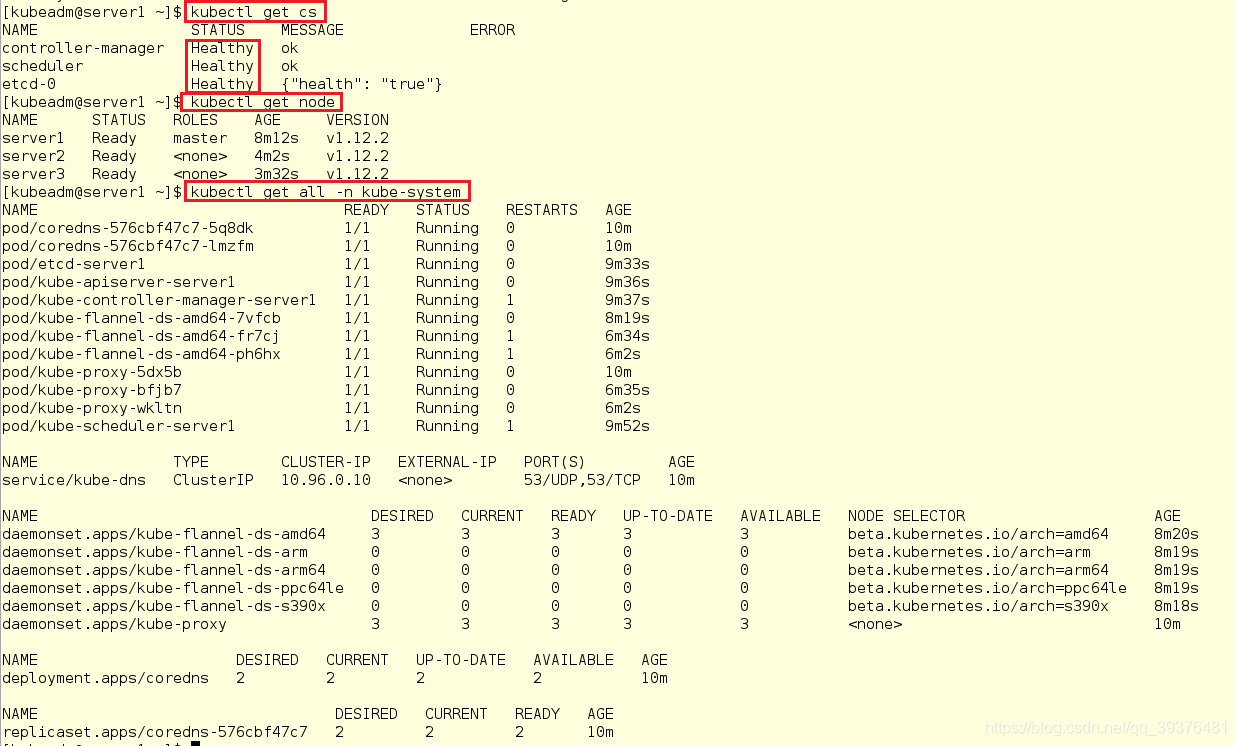
[kubeadm@server1 ~]$ kubectl get cs
[kubeadm@server1 ~]$ kubectl get node
[kubeadm@server1 ~]$ kubectl get all -n kube-system
补充:
添加的节点需要设置网关,不然会报如下错误:
出现 CrashLoopBackOff 这样的错误,排错思路:
获取问题 pod 的详细信息:
kubectl describe pod kube-flannel-ds-amd64-5967g -n kube-systemkubectl logs kube-flannel-ds-amd64-5967g
-n kube-system
通常删除就可以解决:
kubectl delete pod kube-flannel-ds-amd64-5967g -n kube-system
出现 coredns ImagePullBackOff 这样的错误,表示节点镜像 pull 失败了
看一下 coredns 的 pod 是部署在哪个节点上,手动导入镜像即可。